TasNet: time-domain audio separation network for real-time, single-channel speech separation
Robust speech processing in multi-talker environments requires effective speech separation. Recent deep learning systems have made significant progress toward solving this problem, yet it remains challenging particularly in real-time, short latency a…
Authors: Yi Luo, Nima Mesgarani
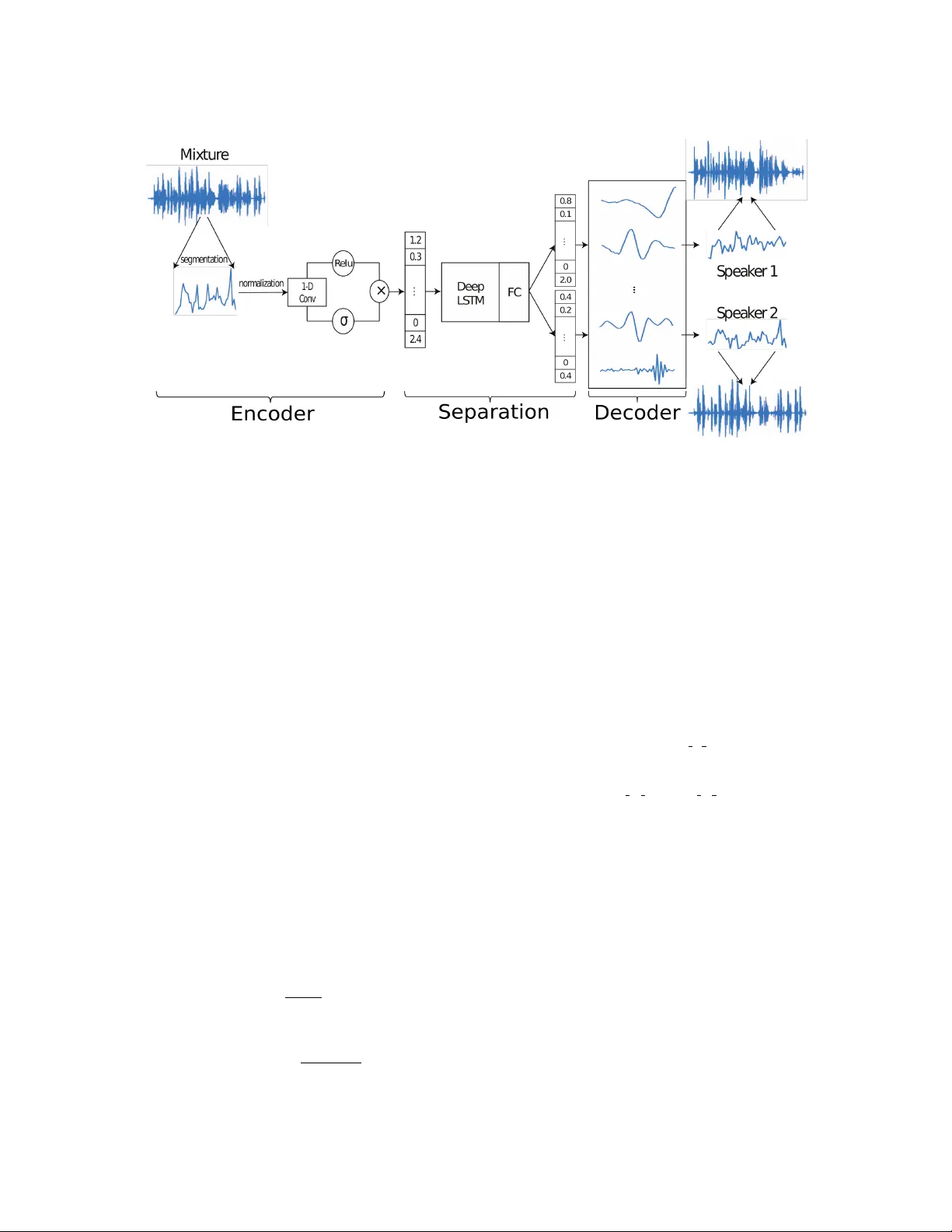
T ASNET : TIME-DOMAIN A UDIO SEP ARA TION NETWORK FOR REAL-TIME, SINGLE-CHANNEL SPEECH SEP ARA TION Y i Luo Nima Mesgar ani Department of Electrical Engineering, Columbia Uni versity , New Y ork, NY ABSTRA CT Robust speech processing in multi-talker en vironments requires effecti ve speech separation. Recent deep learning systems hav e made significant progress toward solving this problem, yet it re- mains challenging particularly in real-time, short latency applica- tions. Most methods attempt to construct a mask for each source in time-frequency representation of the mixture signal which is not necessarily an optimal representation for speech separation. In ad- dition, time-frequency decomposition results in inherent problems such as phase/magnitude decoupling and long time window which is required to achieve sufficient frequenc y resolution. W e propose T ime-domain Audio Separation Network (T asNet) to overcome these limitations. W e directly model the signal in the time-domain using an encoder-decoder framework and perform the source sep- aration on nonnegati ve encoder outputs. This method remo ves the frequency decomposition step and reduces the separation problem to estimation of source masks on encoder outputs which is then synthesized by the decoder . Our system outperforms the current state-of-the-art causal and noncausal speech separation algorithms, reduces the computational cost of speech separation, and signifi- cantly reduces the minimum required latency of the output. This makes T asNet suitable for applications where lo w-power , real-time implementation is desirable such as in hearable and telecommunica- tion devices. Index T erms — Source separation, single channel, raw wav e- form, deep learning 1. INTRODUCTION Real-world speech communication often takes place in crowded, multi-talker environments. A speech processing system that is de- signed to operate in such conditions needs the ability to separate speech of dif ferent talkers. This task which is ef fortless for humans has pro ven v ery dif ficult to model in machines. In recent years, deep learning approaches hav e significantly advanced the state of this problem compared to traditional methods [1, 2, 3, 4, 5, 6]. A typical neural network speech separation algorithm starts with calculating the short-time Fourier transform (STFT) to create a time- frequency (T -F) representation of the mixture sound. The T -F bins that correspond to each source are then separated, and are used to synthesize the source w aveforms using in verse STFT . Sev eral issues arise in this framework. First, it is unclear whether F ourier decom- position is the optimal transformation of the signal for speech sepa- ration. Second, because STFT transforms the signal into a comple x domain, the separation algorithm needs to deal with both magni- tude and the phase of the signal. Because of the dif ficulty in mod- ifying the phase, the majority of proposed methods only modify the magnitude of the STFT by calculating a time-frequency mask for each source, and synthesize using the mask ed magnitude spec- trogram with the original phase of the mixture. This imposes an upper bound on separation performance. Even though se veral sys- tems have been proposed to use the phase information to design the masks, such as the phase-sensiti ve mask [7] and comple x ratio mask [8], the upper bound still exists since the reconstruction is not ex- act. Moreover , effecti ve speech separation in STFT domain requires high frequency resolution which results in relati vely large time win- dow length, which is typically more than 32 ms for speech [3, 4, 5] and more than 90 ms for music separation [9]. Because the mini- mum latency of the system is bounded by the length of the STFT time windo w , this limits the use of such systems when v ery short la- tency is required, such as in telecommunication systems or hearable devices. A natural way to overcome these obstacles is to directly model the signal in the time-domain. In recent years, this approach has been successfully applied in tasks such as speech recognition, speech syn- thesis and speech enhancement [10, 11, 12, 13, 14], but waveform- lev el speech separation with deep learning has not been in vestigated yet. In this paper , we propose T ime-domain Audio Separation Net- work (T asNet), a neural network that directly models the mixture wa veform using an encoder-decoder framew ork, and performs the separation on the output of the encoder . In this framew ork, the mix- ture wa veform is represented by a nonne gativ e weighted sum of N basis signals, where the weights are the outputs of the encoder, and the basis signals are the filters of the decoder . The separation is done by estimating the weights that correspond to each source from the mixture weight. Because the weights are nonneg ative, the estima- tion of source weights can be formulated as finding the masks which indicate the contribution of each source to the mixture weight, sim- ilar to the T -F masks that are used in STFT systems. The source wa veforms are then reconstructed using the learned decoder . This signal factorization technique shares the moti v ation behind independent component analysis (ICA) with nonnegati ve mixing matrix [15] and semi-nonnegati ve matrix factorization (semi-NMF) [16]. Howev er unlike ICA or semi-NMF , the weights and the ba- sis signals are learned in a nonnegati ve autoencoder frame work [17, 18, 19, 20], where the encoder is a 1-D conv olutional layer and the decoder is a 1-D deconv olutional layer (also kno wn as trans- posed con volutional). In this scenario, the mixture weights replace the commonly used STFT representations. Since T asNet operates on wav eform segments that can be as small as 5 ms, the system can be implemented in real-time with very low latency . In addition to having lower latency , T asNet out- performs the state-of-art STFT -based system. In applications that do not require real-time processing, a noncausal separation module can also be used to further improve the performance by using informa- tion from the entire signal. 2. MODEL DESCRIPTION 2.1. Problem f ormulation The problem of single-channel speech separation is formulated as estimating C sources s 1 ( t ) , . . . , s c ( t ) , gi ven the discrete w aveform of the mixture x ( t ) x ( t ) = C X i =1 s i ( t ) (1) W e first segment the mixture and clean sources into K non- ov erlapping vectors of length L samples, x k ∈ R 1 × L (note that K varies from utterance to utterance) ( x k = x ( t ) s i,k = s i ( t ) t ∈ [ k L, ( k + 1) L ) , k = 1 , 2 , . . . , K (2) For simplicity , we drop the notation k where there is no ambi- guity . Each segment of mixture and clean signals can be repre- sented by a nonneg ative weighted sum of N basis signals B = [ b 1 , b 2 , . . . , b N ] ∈ R N × L x = wB s i = d i B (3) where w ∈ R 1 × N is the mixture weight vector , and d i ∈ R 1 × N is the weight vector for the source i . Separating the sources in this representation is then reformulated as estimating the weight matrix of each source d i ∈ R 1 × N giv en the mixture weight w , subject to: w = C X i =1 d i (4) Because all weights ( w , d i ) are nonneg ative, estimating the weight of each source can be thought of as finding its corresponding mask-like vector , m i , which is applied to the mixture weight, w , to recov er D i : w = C X i =1 w ( d i w ) := w C X i =1 m i (5) d i = m i w (6) where m i ∈ R 1 × N represents the relative contribution source i to the mixture weight matrix, and and denotes element-wise mul- tiplication and division. In comparison to other matrix factorization algorithms such as ICA where the basis signals are required to hav e distinct statisti- cal properties or e xplicit frequency band preferences, no such con- straints are imposed here. Instead, the basis signals are jointly op- timized with the other parameters of the separation network dur - ing training. Moreover , the synthesis of the source signal from the weights and basis signals is done directly in the time-domain, unlike the in verse STFT step which is needed in T -F based solutions. 2.2. Network design Figure 1 shows the structure of the network. It contains three parts: an encoder for estimating the mixture weight, a separation module, and a decoder for source wa veform reconstruction. The combination of the encoder and the decoder modules construct a nonnegati ve au- toencoder for the wav eform of the mixture, where the nonnegati ve weights are calculated by the encoder and the basis signals are the 1-D filters in the decoder . The separation is performed on the mix- ture weight matrix using a subnetwork that estimates a mask for each source. 2.2.1. Encoder for mixture weight calculation The estimation of the nonneg ative mixture weight w k for se gment k is done by a 1-D gated con volutional layer w k = ReLU ( x k ~ U ) σ ( x k ~ V ) , k = 1 , 2 , . . . , K (7) where U ∈ R N × L and V ∈ R N × L are N vectors with length L , and w k ∈ R 1 × N is the mixture weight vector . σ denotes the Sigmoid acti vation function and ~ denotes con volution operator . x k ∈ R 1 × L is the k -th segment of the entire mixture signal x ( t ) with length L , and is normalized to ha ve unit L 2 norm to reduce the variability . The con volution is applied on the rows (time dimension). This step is motiv ated by the gated CNN approach that is used in language modeling [21], and empirically it performs significantly better than using only ReLU or Sigmoid in our system. 2.2.2. Separation network The estimation of the source masks is done with a deep LSTM net- work to model the time dependencies across the K segments, fol- lowed by a fully-connected layer with Softmax acti vation function for mask generation. The input to the LSTM network is the sequence of K mixture weight vectors w 1 , . . . w K ∈ R 1 × N , and the output of the network for source i is K mask v ectors m i, 1 , . . . , m i,K ∈ R 1 × N . The procedure for estimation of the masks is the same as the T -F mask estimation in [4], where a set of masks are generated by several LSTM layers followed by a fully-connected layer with Softmax function as activ ation. T o speed up and stabilize the training process, we normalize the mixture weight vector w k in a way similar to layer normalization [22] ˆ w k = g σ ⊗ ( w k − µ ) + b , k = 1 , 2 , . . . , K (8) µ = 1 N N X j =1 w k,j σ = v u u t 1 N N X j =1 ( w k,j − µ ) 2 (9) where parameters g ∈ R 1 × N and b ∈ R 1 × N are gain and bias vectors that are jointly optimized with the network. This normaliza- tion step results in scale inv ariant mixture weight vectors and also enables more efficient training of the LSTM layers. Starting from the second LSTM layer, an identity skip connec- tion [23] is added between every two LSTM layers to enhance the gradient flow and accelerate the training process. 2.2.3. Decoder for waveform r econstruction The separation network produces a mask matrix for each source i M i = [ m i, 1 , . . . , m i,K ] ∈ R K × N from the mixture weight ˆ W = [ ˆ w 1 , . . . , ˆ w K ] ∈ R K × N across all the K segments. The source weight matrices can then be calculated by D i = W M i (10) Fig. 1 . Time-domain Audio Separation Network (T asNet) models the signal in the time-domain using encoder-decoder framework, and perform the source separation on nonne gativ e encoder outputs. Separation is achie ved by estimating source masks that are applied to mixture weights to reconstruct the sources. The source weights are then synthesized by the decoder . where D i = [ d i, 1 , . . . , d i,K ] ∈ R K × N is the weight matrix for source i . Note that M i is applied to the original mixture weight W = [ w 1 , . . . , w K ] instead of normalized weight ˆ W . The time- domain synthesis of the sources is done by matrix multiplication be- tween D i and the basis signals B ∈ R N × L S i = D i B (11) For each segment, this operation can also be formulated as a linear deconv olutional operation (also kno wn as transposed conv o- lution) [24], where each row in B corresponds to a 1-D filter which is jointly learned together with the other parts of the network. This is the in verse operation of the con volutional layer in Section 2.2.1. Finally we scale the reco vered signals to re verse the effect of L 2 normalization of x k discussed in Section 2.2.1. Concatenating the recov eries across all segments reconstruct the entire signal for each source. s i ( t ) = [ S i,k ] , k = 1 , 2 , . . . , K (12) 2.2.4. T raining objective Since the output of the network are the waveforms of the estimated clean signals, we can directly use source-to-distortion ratio (SDR) as our training target. Here we use scale-in variant source-to-noise ratio (SI-SNR), which is used as the ev aluation metric in place of the standard SDR in [3, 5], as the training tar get. The SI-SNR is defined as: s targ et = h ˆ s , s i s k s k 2 (13) e noise = ˆ s − s targ et (14) SI-SNR := 10 l og 10 k s targ et k 2 k e noise k 2 (15) where ˆ s ∈ R 1 × t and s ∈ R 1 × t are the estimated and tar get clean sources respectively , t denotes the length of the signals, and ˆ s and s are both normalized to have zero-mean to ensure scale-in variance. Permutation in variant training (PIT) [4] is applied during training to remedy the source permutation problem [3, 4, 5]. 3. EXPERIMENTS 3.1. Dataset W e e valuated our system on two-speaker speech separation problem using WSJ0-2mix dataset [3, 4, 5], which contains 30 hours of train- ing and 10 hours of validation data. The mixtures are generated by randomly selecting utterances from dif ferent speakers in W all Street Journal (WSJ0) training set si tr s, and mixing them at random signal-to-noise ratios (SNR) between 0 dB and 5 dB. Five hours of ev aluation set is generated in the same way , using utterances from 16 unseen speakers from si dt 05 and si et 05 in the WSJ0 dataset. T o reduce the computational cost, the w aveforms were down-sampled to 8 kHz. 3.2. Network configuration The parameters of the system include the segment length L , the num- ber of basis signals N , and the configuration of the deep LSTM sep- aration network. Using a grid search, we found optimal L to be 40 samples (5 ms at 8 kHz) and N to be 500. W e designed a 4 layer deep uni-directional LSTM network with 1000 hidden units in each layer , follo wed by a fully-connected layer with 1000 hidden units that generates two 500-dimensional mask v ectors. For the noncausal configuration with bi-directional LSTM layers, the number of hid- den units in each layer is set to 500 for each direction. An identical skip connection is added between the output of the second and last LSTM layers. During training, the batch size is set to 128, and the initial learn- ing rate is set to 3 e − 4 for the causal system (LSTM) and 1 e − 3 for the noncausal system (BLSTM). W e halve the learning rate if the accuracy on validation set is not improved in 3 consecutive epochs. T able 1 . SI-SNR (dB) and SDR (dB) for different methods on WSJ0-2mix dataset. Method Causal SI-SNRi SDRi uPIT -LSTM [4] X – 7.0 T asNet-LSTM X 7.7 8.0 DPCL++ [3] × 10.8 – D ANet [5] × 10.5 – uPIT -BLSTM-ST [4] × – 10.0 T asNet-BLSTM × 10.8 11.1 The criteria for early stopping is no decrease in the cost function on the validation set for 10 epochs. Adam [25] is used as the optimiza- tion algorithm. No further regularization or training procedures were used. W e apply curriculum training strategy [26] in a similar fashion with [3, 5]. W e start the training the network on 0.5 second long utterances, and continue training on 4 second long utterances after- ward. 3.3. Evaluation metrics For comparison with previous studies, we ev aluated our system with both SI-SNR improv ement (SI-SNRi) and SDR improv ement (SDRi) metrics used in [3, 4, 5], where the SI-SNR is defined in Section 2.2.4, and the standard SDR is proposed in [27]. 3.4. Results and analysis T able 1 shows the performance of our system as well as three state- of-art deep speech separation systems, Deep Clustering (DPCL++, [3]), Permutation Inv ariant T raining (PIT , [4]), and Deep Attractor Network (DANet, [5]). Here T asNet-LSTM represents the causal configuration with uni-directional LSTM layers. T asNet-BLSTM corresponds to the system with bi-directional LSTM layers which is noncausal and cannot be implemented in real-time. For the other systems, we show the best performance reported on this dataset. W e see that with causal configuration, the proposed T asNet sys- tem significantly outperforms the state-of-art causal system which uses a T -F representation as input. Under the noncausal configu- ration, our system outperforms all the pre vious systems, including the two-stage systems DPCL++ and uPIT -BLSTM-ST which have a second-stage enhancement netw ork. Note that our system does not contain any regularizers such as recurrent dropout (DPCL++) or post-clustering steps for mask estimation (D ANet). T able 2 compares the latency of different causal systems. The la- tency of a system T tot is expressed in two parts: T i is the initial delay of the system that is required in order to receive enough samples to produce the first output. T p is the processing time for a se gment, es- timated as the a verage per -segment processing time across the entire test set. The model was pre-loaded on a Titan X Pascal GPU before the separation of the first segment started. The a verage processing speed per segment in our system is less than 0.23 ms, resulting in a total system latency of 5.23 ms. In comparison, a STFT -based system requires at least 32 ms time interval to start the processing, in addition to the processing time required for calculation of STFT , separation, and in verse STFT . This enables our system to preform in situation that can tolerate only short latency , such as hearing de vices and telecommunication applications. T o in vestigate the properties of the basis signals B , we visu- alized the magnitude of their Fourier transform in both causal and T able 2 . Minimum latency (ms) of causal methods. Method T i T p T tot uPIT -LSTM [4] 32 – > 32 T asNet-LSTM 5 0.23 5.23 noncausal networks. Figure 2 shows the frequency response of the basis signals sorted by their center frequencies (i.e. the bin index corresponding to the the peak magnitude). W e observe a continuous transition from low to high frequenc y , sho wing that the system has learned to perform a spectral decomposition of the waveform, simi- lar to the finding in [10]. W e also observe that the frequency band- width increases with center frequency similar to mel-filterbanks. In contrast, the basis signals in T asNet ha ve a higher resolution in lower frequencies compared to Mel and STFT . In fact, 60% of the basis sig- nals have center frequencies below 1 kHz (Fig. 2), which may indi- cate the importance of low-frequenc y resolution for accurate speech separation. Further analysis of the network representation and trans- formation may lead to better understanding of ho w the network sep- arates competing speakers [28]. (a) (b) Fig. 2 . Frequency response of basis signals in (a) causal and (b) noncausal networks. 4. CONCLUSION In this paper , we proposed a deep learning speech separation sys- tem that directly operates on the sound wav eforms. Using an au- toencoder framew ork, we represent the wa veform as nonnegati ve weighted sum of a set of learned basis signals. The time-domain separation problem then is solv ed by estimating the source masks that are applied to the mixture weights. Experiments showed that our system was 6 times faster compared to the state-of-art STFT - based systems, and achieved significantly better speech separation performance. Audio samples are av ailable at [29]. 5. A CKNO WLEDGEMENT This work was funded by a grant from National Institute of Health, NIDCD, DC014279, National Science F oundation CAREER A ward, and the Pew Charitable T rusts. 6. REFERENCES [1] Po-Sen Huang, Minje Kim, Mark Hasegawa-Johnson, and Paris Smaragdis, “Joint optimization of masks and deep recurrent neural networks for monaural source separation, ” IEEE/A CM T ransactions on Audio, Speech and Language Pro- cessing (T ASLP) , vol. 23, no. 12, pp. 2136–2147, 2015. [2] Xiao-Lei Zhang and DeLiang W ang, “ A deep ensemble learn- ing method for monaural speech separation, ” IEEE/A CM T ransactions on Audio, Speech and Language Processing (T ASLP) , vol. 24, no. 5, pp. 967–977, 2016. [3] Y usuf Isik, Jonathan Le Roux, Zhuo Chen, Shinji W atanabe, and John R Hershe y , “Single-channel multi-speaker separation using deep clustering, ” Interspeech 2016 , pp. 545–549, 2016. [4] Morten K olbæk, Dong Y u, Zheng-Hua T an, and Jesper Jensen, “Multitalker speech separation with utterance-le vel permuta- tion in variant training of deep recurrent neural networks, ” IEEE/A CM T ransactions on Audio, Speech, and Language Pr ocessing , vol. 25, no. 10, pp. 1901–1913, 2017. [5] Zhuo Chen, Y i Luo, and Nima Mesgarani, “Deep attractor net- work for single-microphone speaker separation, ” in Acoustics, Speech and Signal Processing (ICASSP), 2017 IEEE Interna- tional Confer ence on . IEEE, 2017, pp. 246–250. [6] Y i Luo, Zhuo Chen, and Nima Mesgarani, “Speaker - independent speech separation with deep attractor network, ” IEEE/A CM T ransactions on Audio, Speech, and Language Pr ocessing , vol. 26, no. 4, pp. 787–796, 2018. [7] Hakan Erdogan, John R Hershey , Shinji W atanabe, and Jonathan Le Roux, “Phase-sensitive and recognition-boosted speech separation using deep recurrent neural networks, ” in Acoustics, Speech and Signal Pr ocessing (ICASSP), 2015 IEEE International Conference on . IEEE, 2015, pp. 708–712. [8] Donald S W illiamson, Y uxuan W ang, and DeLiang W ang, “Complex ratio masking for monaural speech separation, ” IEEE/A CM transactions on audio, speech, and language pr o- cessing , vol. 24, no. 3, pp. 483–492, 2016. [9] Y i Luo, Zhuo Chen, John R Hershey , Jonathan Le Roux, and Nima Mesgarani, “Deep clustering and con ventional networks for music separation: Stronger together , ” in Acoustics, Speech and Signal Pr ocessing (ICASSP), 2017 IEEE International Confer ence on . IEEE, 2017, pp. 61–65. [10] T ara N Sainath, Ron J W eiss, Andrew Senior, K evin W W il- son, and Oriol V inyals, “Learning the speech front-end with raw wav eform cldnns, ” in Sixteenth Annual Conference of the International Speec h Communication Association , 2015. [11] Pegah Ghahremani, V imal Manohar , Daniel Pove y , and San- jeev Khudanpur , “ Acoustic modelling from the signal domain using cnns., ” in INTERSPEECH , 2016, pp. 3434–3438. [12] Aaron van den Oord, Sander Dieleman, Heiga Zen, Karen Si- monyan, Oriol V inyals, Alex Graves, Nal Kalchbrenner , An- drew Senior , and K oray Kavukcuoglu, “W avenet: A generati ve model for raw audio, ” arXiv pr eprint arXiv:1609.03499 , 2016. [13] Soroush Mehri, Kundan Kumar , Ishaan Gulrajani, Rithesh K u- mar , Shubham Jain, Jose Sotelo, Aaron Courville, and Y oshua Bengio, “Samplernn: An unconditional end-to-end neural audio generation model, ” arXiv pr eprint arXiv:1612.07837 , 2016. [14] Santiago Pascual, Antonio Bonafonte, and Joan Serr ` a, “Segan: Speech enhancement generati ve adversarial network, ” Pr oc. Interspeech 2017 , pp. 3642–3646, 2017. [15] Fa-Y u W ang, Chong-Y ung Chi, Tsung-Han Chan, and Y ue W ang, “Nonnegativ e least-correlated component analysis for separation of dependent sources by volume maximization, ” IEEE transactions on pattern analysis and machine intelli- gence , v ol. 32, no. 5, pp. 875–888, 2010. [16] Chris HQ Ding, T ao Li, and Michael I Jordan, “Con vex and semi-nonnegati ve matrix f actorizations, ” IEEE transactions on pattern analysis and mac hine intellig ence , vol. 32, no. 1, pp. 45–55, 2010. [17] Ehsan Hosseini-Asl, Jacek M Zurada, and Olfa Nasraoui, “Deep learning of part-based representation of data using sparse autoencoders with nonnegativity constraints, ” IEEE transactions on neural networks and learning systems , vol. 27, no. 12, pp. 2486–2498, 2016. [18] Andre Lemme, Ren ´ e Felix Reinhart, and Jochen Jak ob Steil, “Online learning and generalization of parts-based image rep- resentations by non-negativ e sparse autoencoders, ” Neural Networks , vol. 33, pp. 194–203, 2012. [19] Jan Chorowski and Jacek M Zurada, “Learning understandable neural networks with nonnegati ve weight constraints, ” IEEE transactions on neural networks and learning systems , vol. 26, no. 1, pp. 62–69, 2015. [20] Paris Smaragdis and Shrikant V enkataramani, “ A neural net- work alternative to non-negati ve audio models, ” in Acoustics, Speech and Signal Processing (ICASSP), 2017 IEEE Interna- tional Confer ence on . IEEE, 2017, pp. 86–90. [21] Y ann N Dauphin, Angela Fan, Michael Auli, and David Grang- ier , “Language modeling with gated conv olutional networks, ” in International Conference on Machine Learning , 2017, pp. 933–941. [22] Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffre y E Hinton, “Layer normalization, ” arXiv pr eprint arXiv:1607.06450 , 2016. [23] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun, “Identity mappings in deep residual networks, ” in Eur opean Confer ence on Computer V ision . Springer , 2016, pp. 630–645. [24] V incent Dumoulin and Francesco V isin, “ A guide to con- volution arithmetic for deep learning, ” arXiv preprint arXiv:1603.07285 , 2016. [25] Diederik Kingma and Jimmy Ba, “ Adam: A method for stochastic optimization, ” arXiv pr eprint arXiv:1412.6980 , 2014. [26] Y oshua Bengio, J ´ er ˆ ome Louradour, Ronan Collobert, and Ja- son W eston, “Curriculum learning, ” in Pr oc. ICML , 2009, pp. 41–48. [27] Emmanuel V incent, R ´ emi Gribon val, and C ´ edric F ´ evotte, “Performance measurement in blind audio source separation, ” IEEE transactions on audio, speech, and language processing , vol. 14, no. 4, pp. 1462–1469, 2006. [28] T asha Nagamine and Nima Mesgarani, “Understanding the representation and computation of multilayer perceptrons: A case study in speech recognition, ” in International Conference on Mac hine Learning , 2017, pp. 2564–2573. [29] “ Audio samples for T asNet, ” http://naplab.ee. columbia.edu/tasnet.html .
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment