Job Management and Task Bundling
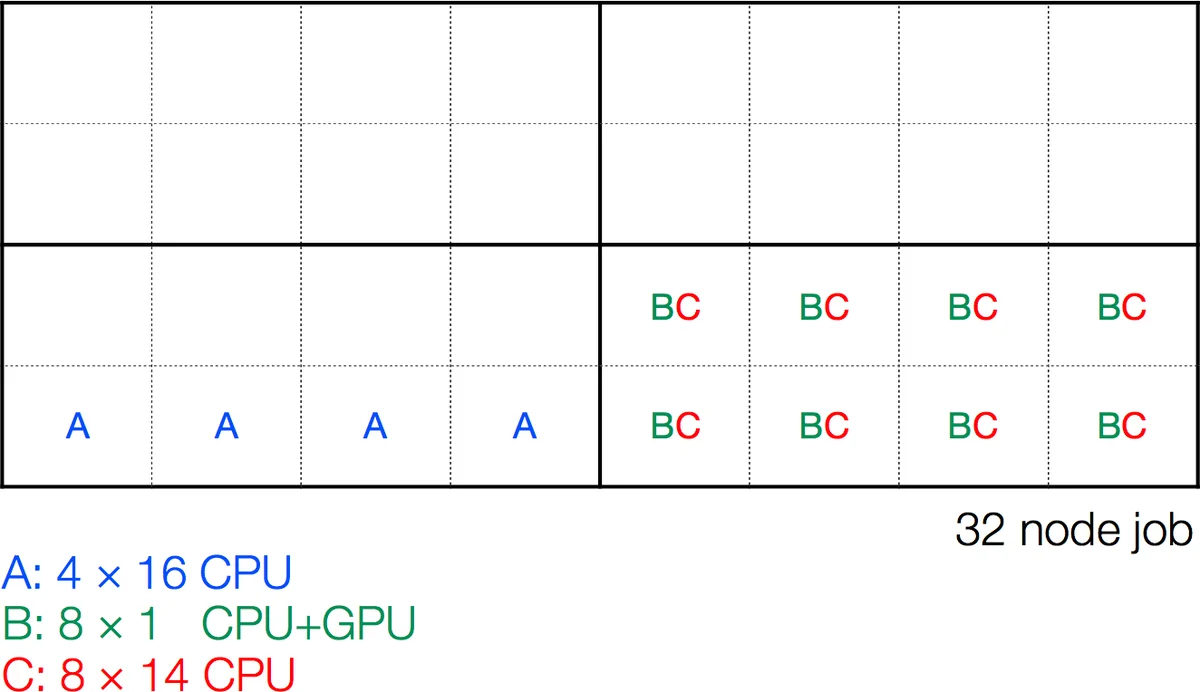
High Performance Computing is often performed on scarce and shared computing resources. To ensure computers are used to their full capacity, administrators often incentivize large workloads that are not possible on smaller systems. Measurements in Lattice QCD frequently do not scale to machine-size workloads. By bundling tasks together we can create large jobs suitable for gigantic partitions. We discuss METAQ and mpi_jm, software developed to dynamically group computational tasks together, that can intelligently backfill to consume idle time without substantial changes to users’ current workflows or executables.
💡 Research Summary
The paper addresses a common inefficiency in high‑performance computing (HPC) centers that incentivize large‑scale jobs to maximize utilization of scarce, shared resources. While such incentives (e.g., time discounts at NERSC or accelerated queue placement at OLCF) are attractive, many scientific applications—particularly Lattice QCD (LQCD) calculations—naturally decompose into many modest‑size tasks that do not scale to the thousands of nodes required to qualify for the incentives. Running these small tasks on a gigantic allocation leads to severe under‑utilization: CPUs and GPUs sit idle while communication dominates, and naïve bundling of many tasks into a single large job often leaves large gaps of idle time because individual tasks finish at different moments or have heterogeneous resource requirements.
To mitigate this waste, the authors propose “task bundling” combined with dynamic “back‑filling”. The idea is to treat each elementary computation (propagator solves, sequential propagators, contractions, etc.) as an independent unit with a known resource demand (number of nodes, wall‑clock estimate, GPU/CPU needs). A back‑filling scheduler then continuously matches the currently free resources inside a large allocation with the pending tasks, launching whichever fits best. This approach can dramatically reduce idle periods while still allowing the overall job to meet the size thresholds required for administrative incentives.
Two software systems are presented: METAQ and mpi_jm.
METAQ is a lightweight, Bash‑based prototype. Users write task scripts that contain a special #METAQ header describing the required resources. These scripts are placed in shared directories; a job script submitted to the batch system periodically scans the directories, compares each task’s declared requirements with the resources currently idle in the allocation, and launches any task that fits. METAQ’s strengths are its simplicity and its compatibility with existing workflows—no changes to executables are needed, and the same scripts can be used with SLURM, MOAB, TORQUE, etc. In practice METAQ has been used to intermix LQCD workloads from multiple collaborations on both leadership‑class machines and smaller clusters.
However, METAQ suffers from several limitations that become critical at scale:
- Trust‑based accounting – the scheduler does not enforce the declared resource usage; a dishonest or mis‑estimated script can corrupt the accounting and lead to deadlock.
- Lack of flexible sizing – a task cannot be automatically resized (e.g., run on 8 nodes if only 8 are free when 16 were requested).
- GPU/CPU binding restrictions – policies that forbid over‑subscription of GPUs prevent certain efficient configurations.
- No explicit submission step – users must manually manage where task files reside, which can become cumbersome.
- File‑system scanning overhead – repeatedly walking directories on a shared filesystem becomes a bottleneck for large task pools.
- Scheduler runs on service nodes – the back‑filling logic executes on the login/management nodes; at extreme scales this caused a crash on Titan, prompting limits on the number of concurrent monitoring processes.
mpi_jm was designed to overcome these drawbacks. Instead of relying on the batch system’s launch commands, mpi_jm spawns a lightweight daemon on each compute node when the job starts. The daemon monitors process IDs, launches new tasks via MPI_Comm_spawn, and tracks actual resource consumption. Key design elements include:
- Block partitioning: The allocated nodes are divided into user‑configurable “blocks” (e.g., groups of 8 or 32 neighboring nodes). Blocks are chosen based on network topology to ensure high‑bandwidth intra‑block communication, reducing performance variability caused by fragmented allocations.
- Two‑handshake protocol: After
MPI_Init, the daemon and the spawned executable exchange a handshake, then the daemon disconnects to prevent a failure in one task from collapsing the whole job. A second handshake afterMPI_Finalizereports exit status. - Strong resource enforcement: Because the daemon resides on the compute nodes, it can verify that a task actually uses the declared number of CPUs/GPUs, preventing the accounting errors seen in METAQ.
- Fine‑grained sharing: Within a block, tasks with complementary resource profiles (e.g., a GPU‑heavy task using 1 CPU + 1 GPU and a CPU‑heavy task using the remaining cores) can coexist, dramatically reducing idle cores.
- Python interface and YAML task description: Users define tasks as Python classes, optionally using YAML dictionaries for static parameters. This enables sophisticated pre‑ and post‑processing, conditional task generation, and integration with external databases or analysis pipelines.
- No service‑node load: All scheduling decisions are made on the compute nodes, eliminating the risk of overloading login or service nodes.
- MPI‑only communication: Because mpi_jm relies solely on MPI, it can be extended across multiple clusters connected via TCP/IP, opening possibilities for cross‑facility resource sharing or “overlapping allocations”.
The authors note that while mpi_jm still reads task description files from disk (retaining METAQ’s fifth drawback), the frequency and overhead are much lower due to the Python‑driven, in‑memory parsing. Moreover, the architecture is amenable to future enhancements such as persistent block‑configuration databases, more sophisticated network‑aware placement algorithms, or integration with graph‑based task graphs.
In the concluding section, the paper argues that as we approach the exascale era, many scientific problems will no longer require ever‑larger per‑instance resources; instead, the bottleneck will be the efficient orchestration of many modest tasks on massive machines. Dynamic, back‑filling bundlers like METAQ (as a proven prototype) and mpi_jm (as a more robust, scalable solution) provide a practical path to exploit administrative incentives without sacrificing scientific throughput. Future work includes automated block sizing, machine‑learning‑driven runtime predictions, and broader grid‑level scheduling across heterogeneous facilities.
Comments & Academic Discussion
Loading comments...
Leave a Comment