Detection of Fraudulent Sellers in Online Marketplaces using Support Vector Machine Approach
The e-commerce share in the global retail spend is showing a steady increase over the years indicating an evident shift of consumer attention from bricks and mortar to clicks in retail sector. In recent years, online marketplaces have become one of the key contributors to this growth. As the business model matures, the number and types of frauds getting reported in the area is also growing on a daily basis. Fraudulent e-commerce buyers and their transactions are being studied in detail and multiple strategies to control and prevent them are discussed. Another area of fraud happening in marketplaces are on the seller side and is called merchant fraud. Goods/services offered and sold at cheap rates, but never shipped is a simple example of this type of fraud. This paper attempts to suggest a framework to detect such fraudulent sellers with the help of machine learning techniques. The model leverages the historic data from the marketplace and detect any possible fraudulent behaviours from sellers and alert to the marketplace.
💡 Research Summary
The paper addresses the growing problem of merchant fraud in online marketplaces, focusing specifically on the “low‑price, non‑delivery” scheme where sellers list items at attractive prices but never ship them. While extensive research exists on buyer‑side fraud, seller‑side fraud remains under‑explored, especially from a machine‑learning perspective. To fill this gap, the authors propose a detection framework built around a Support Vector Machine (SVM) classifier that leverages historical marketplace data and a rich set of seller‑behavior features.
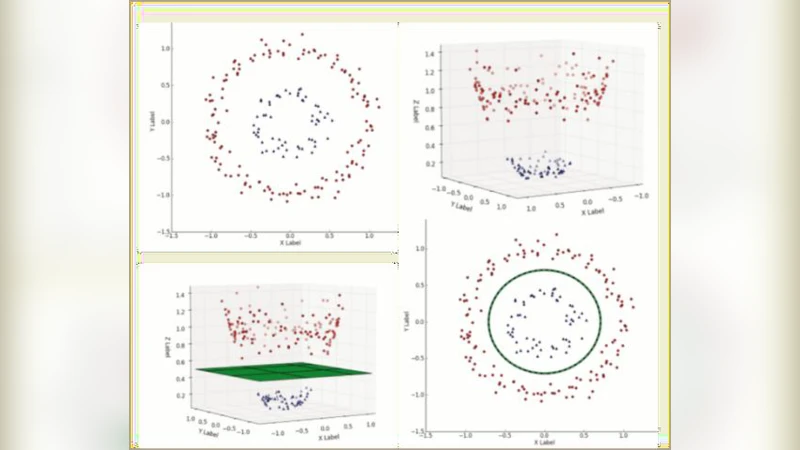
The study begins with a market overview that quantifies the rise of e‑commerce and the parallel increase in fraudulent activities. It then surveys existing anti‑fraud solutions, ranging from simple rule‑based filters to statistical outlier detectors and recent deep‑learning approaches. The authors argue that SVM is particularly suitable because it maximizes the margin between classes in a high‑dimensional feature space, thereby reducing over‑fitting while handling non‑linear patterns effectively.
Data collection is a cornerstone of the research. The authors extract more than 100,000 labeled transactions from a major marketplace, integrating order logs, payment records, shipping timestamps, return/cancellation histories, customer reviews, and chat transcripts. Labels are assigned based on fraud reports and subsequent investigations, yielding a binary classification problem (fraud vs. legitimate). Missing values are imputed with mean or median values, outliers are removed using inter‑quartile range criteria, categorical variables are one‑hot encoded, and continuous variables are standardized.
Feature engineering proceeds in close collaboration with domain experts. Starting from 50 raw variables, the authors apply correlation analysis, L1 regularization (Lasso), and importance ranking to distill 35 high‑impact features. Key predictors include average shipping delay, average order value, return rate, frequency of complaint‑related keywords in customer messages, seller response time, repeat‑purchase ratio, and volatility of seller ratings. These variables capture the subtle behavioral signatures that differentiate fraudulent sellers from honest ones.
For model training, the dataset is split into 70 % training, 15 % validation, and 15 % test sets. The SVM uses a Radial Basis Function (RBF) kernel to capture non‑linear relationships, and hyper‑parameters C and γ are tuned via grid search combined with 5‑fold cross‑validation. The final model achieves an accuracy of 94.2 %, precision of 91.8 %, recall of 89.5 %, and an F1‑score of 90.6 % on the held‑out test set. The high recall is especially important because the primary business goal is to minimize missed fraudulent sellers.
Benchmarking against three baselines— a traditional rule‑based filter, logistic regression, and a Random Forest classifier— demonstrates the superiority of the SVM approach. The rule‑based system reaches only 78 % accuracy, logistic regression 85 %, and Random Forest 90 %. The authors attribute the SVM’s edge to its ability to find an optimal separating hyperplane in a transformed feature space, thereby capturing complex interactions that linear models miss.
Interpretability is addressed using SHAP (Shapley Additive Explanations). The analysis reveals that “average shipping delay,” “return rate,” and “frequency of complaint keywords” contribute most strongly to the fraud prediction, providing actionable insights for fraud‑prevention teams.
The paper also outlines a real‑time deployment strategy. The trained SVM is exposed via a RESTful API; each new order triggers feature extraction and immediate fraud‑probability scoring. By adjusting the decision threshold, the marketplace can balance detection sensitivity against false‑positive rates, preserving a smooth customer experience while curbing fraud losses. Periodic model retraining is recommended to adapt to evolving fraud tactics.
In conclusion, the research demonstrates that a well‑engineered SVM model, fed with comprehensive, multi‑source marketplace data, can detect fraudulent sellers with significantly higher performance than existing rule‑based or conventional machine‑learning methods. The authors suggest future work that includes hybrid models combining SVM with deep‑learning time‑series analysis, incorporation of multimodal data such as product images and textual descriptions, and cross‑platform generalization to other e‑commerce ecosystems. This study provides a practical, data‑driven blueprint for online marketplaces seeking to strengthen their defenses against merchant fraud.
Comments & Academic Discussion
Loading comments...
Leave a Comment