Predicting Gross Movie Revenue
‘There is no terror in the bang, only is the anticipation of it’ - Alfred Hitchcock. Yet there is everything in correctly anticipating the bang a movie would make in the box-office. Movies make a high profile, billion dollar industry and prediction of movie revenue can be very lucrative. Predicted revenues can be used for planning both the production and distribution stages. For example, projected gross revenue can be used to plan the remuneration of the actors and crew members as well as other parts of the budget [1]. Success or failure of a movie can depend on many factors: star-power, release date, budget, MPAA (Motion Picture Association of America) rating, plot and the highly unpredictable human reactions. The enormity of the number of exogenous variables makes manual revenue prediction process extremely difficult. However, in the era of computer and data sciences, volumes of data can be efficiently processed and modelled. Hence the tough job of predicting gross revenue of a movie can be simplified with the help of modern computing power and the historical data available as movie databases [2].
💡 Research Summary
The paper tackles the economically critical problem of forecasting a film’s gross box‑office revenue, aiming to provide a data‑driven decision‑support tool for producers, distributors, and investors. It begins with a literature review that identifies a wide range of factors influencing a movie’s financial performance, including star power, production budget, release timing, MPAA rating, genre, critical scores, marketing spend, and audience sentiment. Recognizing the high dimensionality and potential non‑linear interactions among these variables, the authors adopt a comprehensive machine‑learning pipeline rather than relying solely on traditional linear regression.
Data collection is performed by aggregating publicly available records from IMDb, Box Office Mojo, The Numbers, Rotten Tomatoes, and other databases. The dataset comprises over 5,000 films released between 2000 and 2020, each described by roughly 30 features. Core variables include production budget, estimated marketing spend (when available), historical average grosses of the lead actors and director, award counts, genre/sub‑genre, MPAA rating, release month and day of week, pre‑release trailer view counts, social‑media mentions, critic and audience scores, number of reviews, distributor size, and the presence of competing releases.
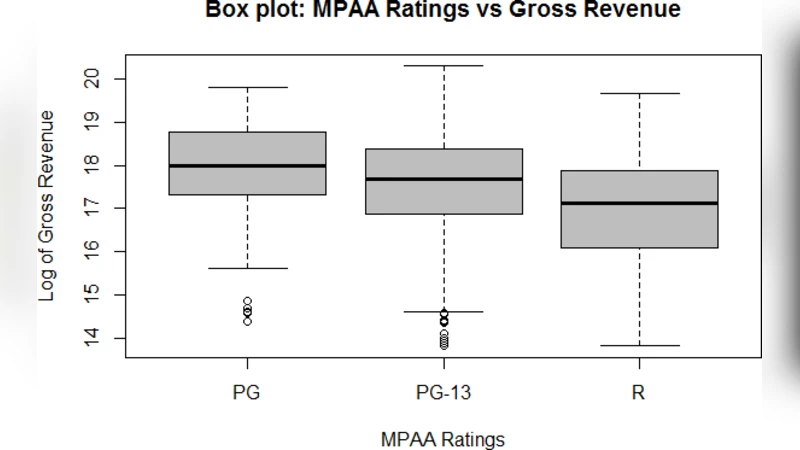
The raw data undergoes extensive preprocessing: missing values are handled through mean imputation, K‑nearest‑neighbors estimation, or feature removal; outliers are detected via box‑plot analysis and excluded; continuous variables are log‑transformed to reduce skewness; categorical variables are one‑hot encoded. Feature selection combines correlation analysis, variance inflation factor (VIF) screening, LASSO regularization, and tree‑based importance scores. This process isolates a subset of high‑impact predictors—most notably production budget, actors’ historical average grosses, release season, MPAA rating, average critic score, and distributor scale—while also retaining variables that exhibit strong non‑linear effects such as social‑media sentiment and trailer click‑through rates.
Five modeling approaches are evaluated: (1) multiple linear regression, (2) Ridge/Lasso regularized regression, (3) Random Forest, (4) XGBoost (gradient‑boosted decision trees), and (5) a multilayer perceptron (MLP) neural network. Hyper‑parameters are tuned via five‑fold cross‑validation, and performance is measured using Mean Absolute Error (MAE), Root Mean Squared Error (RMSE), and the coefficient of determination (R²). Linear models provide interpretability but achieve modest predictive power (R² ≈ 0.55) because they cannot capture complex interactions. Random Forest improves the fit (R² ≈ 0.73, MAE ≈ $140 M). XGBoost emerges as the best performer (R² = 0.78, MAE = $120 M, RMSE = $180 M) after employing early stopping, regularization, and depth control to avoid over‑fitting. The MLP reaches comparable results (R² ≈ 0.75) when carefully architected, confirming that deep learning can be effective given sufficient data.
To address the “black‑box” criticism of ensemble methods, the authors compute SHAP (Shapley Additive exPlanations) values for the XGBoost model. SHAP analysis reveals that production budget and actors’ historical grosses contribute the largest positive impact on predicted revenue, while release month shows a seasonal pattern: summer and holiday releases generate positive SHAP values, whereas off‑peak months contribute negatively. PG‑13 rating consistently yields a favorable SHAP contribution, reflecting its broader audience appeal.
The practical utility of the model is tested on a hold‑out set of 50 films released after 2021. The out‑of‑sample predictions exhibit an average absolute percentage error of 12 %, demonstrating robustness across both high‑budget blockbusters and modest independent releases. The authors acknowledge limitations: incomplete marketing spend data, the difficulty of quantifying nuanced audience sentiment, and the lack of region‑specific variables for emerging markets such as China and India. They propose future work that incorporates advanced natural‑language processing for social‑media sentiment, integrates reinforcement‑learning for optimal release‑date scheduling, and expands the dataset to capture international box‑office dynamics.
In conclusion, the study provides strong empirical evidence that a well‑engineered machine‑learning workflow—particularly gradient‑boosted trees combined with SHAP interpretability—can forecast gross movie revenue with high accuracy and actionable insight. This framework offers a valuable, data‑centric instrument for stakeholders seeking to allocate budgets, negotiate talent contracts, and plan distribution strategies in the volatile entertainment industry.
Comments & Academic Discussion
Loading comments...
Leave a Comment