Whats my age?: Predicting Twitter Users Age using Influential Friend Network and DBpedia
Social media is a rich source of user behavior and opinions. Twitter senses nearly 500 million tweets per day from 328 million users.An appropriate machine learning pipeline over this information enables up-to-date and cost-effective data collection for a wide variety of domains such as; social science, public health, the wisdom of the crowd, etc. In many of the domains, users demographic information is key to the identification of segments of the populations being studied. For instance, Which age groups are observed to abuse which drugs?, Which ethnicities are most affected by depression per location?. Twitter in its current state does not require users to provide any demographic information. We propose to create a machine learning system coupled with the DBpedia graph that predicts the most probable age of the Twitter user. In our process to build an age prediction model using social media text and user meta-data, we explore the existing state of the art approaches. Detailing our data collection, feature engineering cycle, model selection and evaluation pipeline, we will exhibit the efficacy of our approach by comparing with the “predict mean” age estimator baseline.
💡 Research Summary
The paper presents a comprehensive machine‑learning pipeline for estimating the age of Twitter users who do not disclose this demographic information in their profiles. The authors argue that age is a crucial variable for many downstream applications—public health monitoring, targeted marketing, and social‑science research—but Twitter itself does not collect it. To address this gap, the study combines two sources of information: (1) the set of “influential” friends that a user follows, and (2) structured knowledge from DBpedia, a large, crowd‑curated knowledge graph derived from Wikipedia.
Data collection starts with the Twitris dataset, from which 23,120 users with self‑reported ages are extracted using regular‑expression parsing of the profile description field. For each of these seed users, the Twitter REST API is used to retrieve the list of user IDs they follow (the “friend” list). The authors then identify the top 50 most‑followed Twitter accounts, map each of them to a Wikipedia page, and subsequently to a DBpedia entity URI. Using DBpedia Spotlight with a high confidence threshold (0.8), they automatically link the remaining friends’ screen names and descriptions to DBpedia entities, extracting rdf:type categories (e.g., Person, Artist, Organization) and birthDate properties where available.
Feature engineering yields a high‑dimensional vector of 372 attributes per user. These include simple numeric statistics (friend count, follower count, mean/median friend follower count, mean/median friend age) and a set of categorical counts for each DBpedia rdf:type that appears in the user’s friend list. The authors also compute aggregate statistics of the ages and follower counts of the “popular” friends. This hybrid representation captures both network‑based popularity signals and semantic information about the interests of the people a user follows.
Exploratory analysis shows a heavily skewed age distribution, with the majority of users between 19 and 29 years old. A Kolmogorov‑Smirnov test yields a p‑value of 0.04, indicating that the full feature set is statistically associated with age. Because of the skew and high dimensionality, the authors evaluate several regression models. Linear approaches—ordinary least‑squares regression, LASSO, and ElasticNet—are first tried. LASSO performs variable selection but tends to overfit; ElasticNet mitigates sparsity through combined L1/L2 regularization but still shows limited predictive power due to multicollinearity among the DBpedia‑derived features.
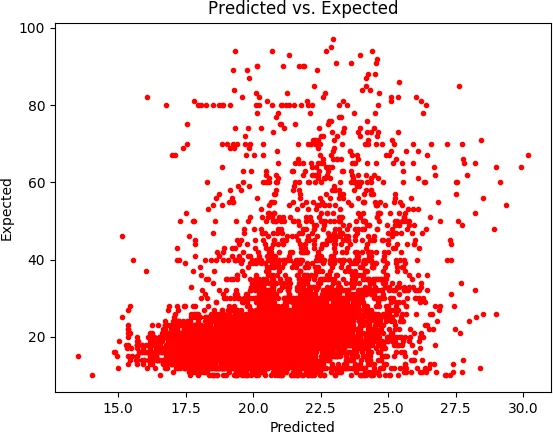
The core of the experimental comparison involves Support Vector Regression (SVR) with three kernels: linear, polynomial, and radial basis function (RBF). Hyper‑parameters (C, ε, kernel parameters) are tuned via grid search, and model selection is guided by cross‑validation scores, Akaike Information Criterion (AIC), and Bayesian Information Criterion (BIC). The RBF‑SVR consistently outperforms all linear baselines, achieving the lowest mean absolute error (MAE ≈ 1.84 years), root‑mean‑square error (RMSE ≈ 2.31 years), and the highest coefficient of determination (R² ≈ 0.62) across multiple train‑test splits (10 %, 25 %, 33 %).
Ablation experiments demonstrate the contribution of the DBpedia semantic features: when only raw count‑based features are used, MAE increases by roughly 0.3–0.4 years, confirming that the knowledge‑graph enrichment adds predictive value. The authors acknowledge several limitations: the age labels are self‑reported and may contain noise; the sampling strategy focuses on users who follow popular accounts, which may not be representative of the broader Twitter population; and the model does not incorporate temporal dynamics or tweet content.
Future work is outlined to address these gaps. The authors propose integrating multimodal data (tweet text, images, videos) with the current network‑semantic features, employing Graph Neural Networks to directly learn from the full friend‑friend graph structure, and extending the framework to predict additional demographics (gender, location) in a multitask setting.
In summary, the paper introduces a novel hybrid approach that leverages influential friend networks and external semantic knowledge to predict Twitter users’ ages. Empirical results show that non‑linear SVR models can achieve accurate age estimates, and that DBpedia‑derived features meaningfully improve performance over purely structural baselines. This work advances the state of the art in demographic inference from social media and provides a scalable, cost‑effective alternative to traditional survey‑based methods.
Comments & Academic Discussion
Loading comments...
Leave a Comment