A comparison of recent waveform generation and acoustic modeling methods for neural-network-based speech synthesis
Recent advances in speech synthesis suggest that limitations such as the lossy nature of the amplitude spectrum with minimum phase approximation and the over-smoothing effect in acoustic modeling can be overcome by using advanced machine learning app…
Authors: Xin Wang, Jaime Lorenzo-Trueba, Shinji Takaki
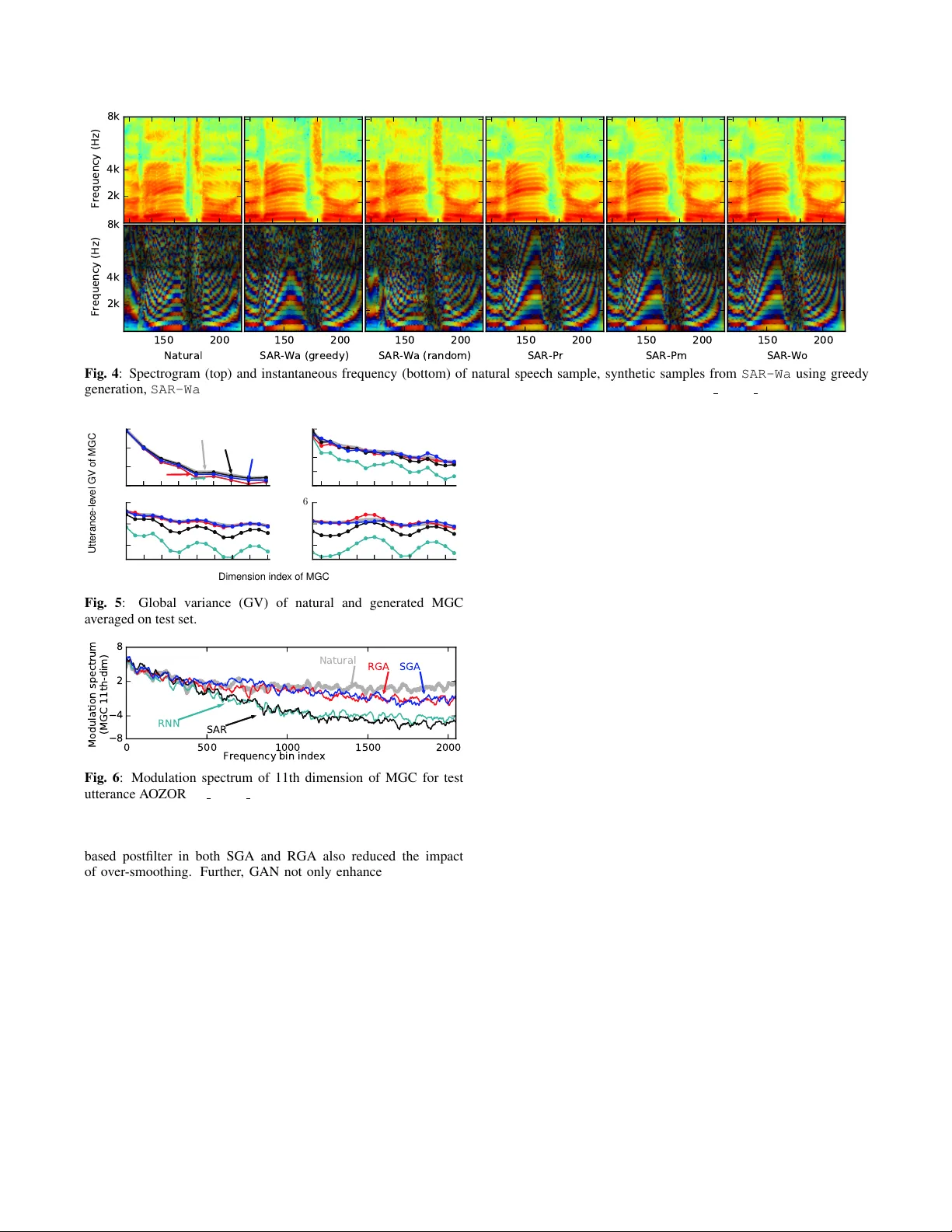
IEEE Copyright Notice ©2018 IEEE. Personal use of this material is permitted. Permission from IEEE must be obtained for all other uses, in any current or future media, including reprinting/republishing this material for advertising or promotional purposes, creating new collecti ve w orks, for resale or redistrib ution to servers or lists, or reuse of any cop yrighted component of this work in other works. Accepted to be published in: Proceedings of the 2018 IEEE International Conference on Acoustics, Speech, and Signal Processing, April 16-20, 2018, Calgary , Canada A COMP ARISON OF RECENT W A VEFORM GENERA TION AND A COUSTIC MODELING METHODS FOR NEURAL-NETWORK-B ASED SPEECH SYNTHESIS Xin W ang 1 , J aime Lor enzo-T rueba 1 , Shinji T akaki 1 , Lauri J uvela 2 , J unichi Y amagishi 1 ∗ 1 National Institute of Informatics, Japan 2 Aalto Uni versity , Finland wangxin@nii.ac.jp, jaime@nii.ac.jp, takaki@nii.ac.jp, lauri.juvela@aalto.fi, jyamagis@nii.ac.jp ABSTRA CT Recent adv ances in speech synthesis suggest that limitations such as the lossy nature of the amplitude spectrum with minimum phase approximation and the ov er-smoothing effect in acoustic modeling can be o vercome by using advanced machine learning approaches. In this paper, we build a frame work in which we can fairly compare new vocoding and acoustic modeling techniques with conv entional approaches by means of a large scale cro wdsourced ev aluation. Results on acoustic models showed that generative adversarial networks and an autoregressi ve (AR) model performed better than a normal recurrent network and the AR model performed best. Evaluation on vocoders by using the same AR acoustic model demonstrated that a W avenet v ocoder outperformed classical source- filter-based v ocoders. Particularly , generated speech wa veforms from the combination of AR acoustic model and W av enet vocoder achiev ed a similar score of speech quality to vocoded speech. Index T erms — speech synthesis, deep learning, W avenet, general adversarial network, autore gressive neural netw ork 1. INTR ODUCTION T ext-to-speech (TTS) synthesis aims at conv erting a text string into a speech w aveform. A con ventional TTS pipeline normally includes a frond-end te xt-analyzer and a back-end speech synthesizer , each of which may include multiple modules for specific tasks. For example, the back-end based on statistical parametric speech synthesis (SPSS) uses statistical acoustic models to map linguistic features from the text-analyzer into compact acoustic features. It then uses a v ocoder to generate a wa veform from the acoustic features. Recent TTS systems have well adopted to the impact of deep learning. First, frameworks dif ferent from the established TTS pipeline are defined. One frame work merges the text-analyzer and acoustic models into a single neural network (NN), where the input text is directly mapped into acoustic features, e.g., by T actron [1] and Char2wa v [2]. Another frame work is the unified back- end represented by W av enet [3] that directly conv erts the linguistic features into a wa veform. There are also novel NN back-ends without the use of normal acoustic features, vocoders [4, 5], or duration model [6]. In parallel to these new frameworks, modules for the con ventional TTS pipeline ha ve also been developed. For instance, acoustic models based on the generativ e adversarial network (GAN) [7] and autoregressiv e (AR) NN [8] ha ve been reported to alleviate the ov er-smoothing effect in acoustic modeling. ∗ This work was partially supported by MEXT KAKENHI Grant Numbers (15H01686, 16H06302, 17H04687), and JST A CT -I Grant Number (JPMJPR16UG). minimum phase 10/ 20/ 17 1 Wavenet PML Phase recovery SAR RNN DAR SAR - Wa SAR - Pm SAR - Pr SAR - Wo SGA - Wo RGA - Wo RNN - Wo Waveform generators Acoustic models Linguistic features F0 MGC GAN WORLD Fig. 1 : Flowchart for seven speech synthesis methods compared in this study . This figure hides the band aperiodicity (B AP) features and RNN that generates noise mask for PML vocoder . There is also the W av enet-based vocoder [9] that uses deep learning rather than signal processing methods to attain waveform generation. Giv en the recent progress with TTS, we think it is important to understand the pros and cons of the new methods on the basis of common conditions. As an initial step, we compared the new methods that could easily be plugged into the SPSS-based back- end of the classical TTS pipeline. These methods were di vided into two groups, and thus the comparison included two parts. The first part compared acoustic models based on four types of NN, including the normal recurrent neural network (RNN), shallo w AR- based RNN (SAR), and two GAN-based postfilter networks [7] that were attached to the RNN and SAR. The second part compared wa veforms generation techniques, including the high-quality source- filter v ocoder WORLD [10], another synthesizer based on the log- domain pulse model (PML) [11], WORLD plus the Griffin-Lim algorithm for phase recov ery [12], and the W av enet-based vocoder . Section 2 explains the details on the selected methods used for comparison. Section 3 explains the experiments and Section 4 draws conclusions. 2. SPEECH SYNTHESIS METHODS This comparison study was based on perceptual ev aluation of synthetic speech. The selected acoustic models and waveform generation methods were combined into the sev en speech synthesis methods giv en in Fig. 1, where SAR-Wa , SAR-Pm , SAR-Pr , and SAR-Wo use the same acoustic models but different waveform generation modules, while SAR-Wo , GAS-Wo , GAR-Wo , and RNN-Wo use the same WORLD vocoder but dif fer in the acoustic model to generate the Mel-generalized coef ficients (MGC) and band aperiodicity (BAP). The F0 for all the methods is generated by a deep AR (DAR) model [13]. The oracle duration is used for all the methods. Neither formant enhancement nor MLPG [14] was used. 2.1. W avef orm generation 2.1.1. Relationship between acoustic featur es and waveforms A vocoder in a conv entional speech synthesis method synthesizes the wav eform gi ven the generated acoustic features by the acoustic model. Howev er, the synthesized waveform may be unnatural ev en if the acoustic model is perfect because the acoustic features may be imperfectly defined. For example, to extract cepstral features from the wav eform, the first step is to apply discrete Fourier transform (DFT) to the windowed wav eform and then acquire the complex spectrum, s n = [ s n, 1 , · · · , s n,F ] ∈ C F . Here, s n,f = a n,f + ib n,f ∈ C is a complex number , n is the index of a speech frame, and f ∈ [1 , F ] is the index of a frequency bin. The next step is to compute the po wer spectrum, p n = [ p n, 1 , · · · , p n,F ] = diag ( s H n s n ) , where p n ∈ R F . Note that H is the Hermitian transpose, and then p n,f = | s n,f | 2 = a n,f 2 + b n,f 2 ∈ R . Finally , cepstral feature c n ∈ R M , where M < F , is acquired after in verse DFT plus filtering and frequency warping on log-amplitude spectrum [log √ p n, 1 , · · · , log √ p n,F ] . Notice that p n encodes the amplitude of s n while ignoring the phase. Therefore, s n and the wa veform cannot be accurately reproduced only given c n . Con ventional vocoders assume that s n has a minimum phase in order to approximately recover s n from c n . Howe ver , the speech wa veform is not merely a minimum-phase signal. One solution is to model the phase as additional acoustic features [15, 16]. Another way is to directly model complex-valued s n by using comple x- valued NN [17] or restricted Boltzman machine [18]. Alternativ ely , a statistical model such as the W av enet-based vocoder [9] can be used rather than using a deterministic v ocoder . Such a vocoder may learn the phase information not encoded by the acoustic features. This work used a con ventional vocoder called WORLD [10] as the baseline. It then included a phase-recovery technique [12], a wav eform synthesizer based on a log-domain pulse model [11], and a W av enet-based vocoder for comparison. Complex-v alued approaches may be included in future work. 2.1.2. Deterministic vocoders The WORLD v ocoder [10] is similar to the legac y STRAIGHT vocoder [19] and uses a source-filter -based speech production model with mixed excitation. It also assumes a minimum phase for the spectrum. By using the procedure in Sec. 2.1.1 rev ersely , WORLD con verts the cepstral features, c n , given by the acoustic model into a linear amplitude spectrum. Then, WORLD creates the excitation signal by mixing a pulse and a noise signal in the frequenc y domain, where each frequency band is weighted by a BAP value. Finally , it generates a speech wa veform based on the source-filter model. Since W ORLD assumes a minimum phase, this work included a phase-recov ery method that may enhance the phase of the generated wa veform by WORLD. This method re-computes the amplitude spectrum given the generated wa veform and then applies the Grif fin- Lim phase-recovery algorithm. Note that this method is different from that in our previous work [5, 20] where phase-recovery was directly conducted on the generated amplitude spectrum. This w ork also included the pulse model in the log-domain (PML) [11] as another wa veform generator . One advantage of PML is that it avoids voicing decision per frame and may alleviate the perceptual degradation caused by voicing decision errors. In addition, PML may better represent noise in voiced segments. The PML and WORLD in this work used the same generated spectrum as input. The noise mask used by PML is generated by another RNN giv en input linguistic features, which it is not indicated in Fig. 1. 2.1.3. Data-driven vocoder Besides the deterministic vocoders, this work included a statistical vocoder based on W avenet [9, 21]. Suppose o t is a one-hot vector representing the quantized wav eform sampling point at time t , the W avenet vocoder infers the distribution P ( o t | o t − R : t − 1 , a t ) given the acoustic feature a t and previous observations o t − R : t − 1 = { o t − R , · · · , o t − 1 } , where R is the receptiv e field of the network. In this work, a t contained the F0 and MGC. Note that, while natural a t is used to train the vocoder , b a t generated by the acoustic model is used for wa veform generation. During generation, b o t is usually obtained by random sampling, i.e., b o t ∼ P ( o t | b o t − R : t − 1 , b a t ) . Ho wever , we found that the synthetic wa veform sounded better when samples in the voiced segments were generated as b o t = arg max o t p ( o t | b o t − R : t − 1 , b a t ) . This method is referred to as the gr eedy generation method. Fig. 4 plots the spectrogram and the instantaneous frequency (IF) [22, 23] of generated wav eforms from the two methods, i.e., SAR-Wa (greedy) and SAR-Wa (random). Compared with random sampling, the greedy method generated more re gular IF patterns in v oiced segments. It perceptually made the w aveforms sound less trembling. One reason for this may be that the ‘best’ generated b o t was temporally more consistent with b o t − R : t − 1 . Note that samples in the un voiced parts were still randomly drawn, and the voiced/un voiced state for each time could be inferred from the F0 in b a t . 2.2. Neural network acoustic models The NN-based acoustic models included in this work aims at inferring the distribution of the acoustic feature sequence a 1: N = { a 1 , · · · , a N } conditioned on the linguistic feature l 1: N = { l 1 , · · · , l N } in N frames. The baseline RNN, whether it has a recurrent output layer or not, defines the distribution as p ( a 1: N | l 1: N ) = N Y n =1 p ( a n | l 1: N ) = N Y n =1 N ( a n ; h n , I ) , (1) where N ( · ) is the Gaussian distribution, I is the identity matrix, h n = H Θ ( l 1: N , n ) is the outcome of the output layer at frame n , and Θ is the netw ork’ s weight. For generation, b a 1: N can be acquired by using a mean-based method that sets b a 1: N = h 1: N . A shortcoming of RNN is that the across-frame dependency in a 1: N is ignored. Hence, this work included a model that takes into account the dependency in a causal direction [8]. This model, which is called shallow AR (SAR), defines the distrib ution as: p ( a 1: N | l 1: N ) = N Y n =1 p ( a n | a n − K : n − 1 , l 1: N ) (2) = N Y n =1 N ( a n ; h n + F Φ ( a n − K : n − 1 ) , I ) . (3) This model uses F Φ ( a n − K : n − 1 ) = P K k =1 β k a n − k + γ to merge the acoustic features in the previous K frames and then changes the distribution for frame n , which builds the causal across-frame dependency . Another deep AR (DAR) model similar to SAR can be defined [13]. DAR in this work was only used to model the quantized F0 for all the experimental methods, and thus is not e xplained here. As RNN and SAR are trained by using the maximum-likelihood criterion and then generate by using the mean-based method, they may not produce acoustic features with natural textures. Therefore, this work also included the GAN-based postfilter [7] to enhance RNN and SAR. The GAN discriminators in this work did not crop the input acoustic features into small patches, which is different from original work. Instead, the y made a true-false judgment e very frame. linear bi - LSTM bi - LSTM FF MGC GMM linear bi - LSTM bi - LSTM FF FF MGC H-softmax linear un - LSTM bi - LSTM FF FF F0 FF RNN SAR DAR CNN+FF SAR/RNN GAN noise CNN+FF CNN+FF + + + linear MGC FF+CNN FF+CNN FF+CNN sigmoid 0/1 scaling Linguistic features Fig. 2 : Structure of acoustic models. Linear, FF , H-softmax, and un- and bi-LSTM correspond to linear transformation, feedforward layer using tanh , hierarchical softmax [13], and uni- and bi-directional LSTM layers. GMM is Gaussian mixture model. Scaling layer in GAN scales each dimension of input features. 3. EXPERIMENTS 3.1. Corpus and featur es This work used a Japanese speech corpus [24] of neutral reading speech uttered by a female speaker . The duration is 50 hours, and the number of utterance is 30,016, out of which 500 were randomly selected as a validation set and another 500 were used as a test set. Linguistic features were extracted by using OpenJT alk [25]. The dimension of these features vectors was 389. Acoustic features were extracted at a frame rate of 200 Hz (5 ms) from the 48 kHz wa veforms. MGC and BAP were extracted by using WORLD. The dimensions for MGC were 60 and those for BAP were 25. The F0 was extracted by an assembly of multiple pitch trackers and then quantized into 255 lev els for quantized F0 modeling [13]. 3.2. Neural network configuration The network structures of the acoustic models are plotted in Fig. 2. In D AR, RNN and SAR, the size of feedforward (FF), bi- and uni- directional LSTM layer was 512, 256, and 128. The size of the linear layer depended on the output features’ dimensions. For SAR, the output layer included a Gaussian distribution for MGC with the AR parameter K = 1 and another Gaussian for B AP with K = 0 . In GAN, all the CNN layers had 256 output channels and conducted 1D conv olution. Each FF layer in the GAN generator changed the dimension of a CNN’ s output before skip-add operation. T o reduce instability in low-dimensional MGCs, the input MGC to the discriminator was scaled element-wisely . The scaling weight was 0 . 001 for the first fi ve MGC dimensions, 0 . 01 for the next five dimensions, and 1 for the rest. The weight was 0 for BAP . The W avenet vocoder works at a sampling rate of 16kHz. The µ -law companded wav eform is quantized into 10 bits per sample. Similar to the literature [9], the network consists of a linear proje ction input layer, 40 blocks for dilated con volution, and a post-processing block. The k -th dilation block has a dilation size of 2 mod( k , 10) , where mod( · ) is modulo operation. The acoustic features, which are fed to ev ery dilated conv olution block, contains MGC and quantized F0. Natural acoustic features are used for training while generated MGC and F0 are used during generation. All the acoustic models and W avenet are implemented on a modified CURRENNT toolkit [26]. This toolkit and training recipes can be found online ( http://tonywangx.github.io ). Natural Abs-Pm Abs-Wo SAR-Wa SAR-Pr SAR-Pm SAR-Wo SGA-Wo RGA-Wo RNN-Wo 1.5 2.0 2.5 3.0 3.5 4.0 4.5 5.0 MOS score Speech quality 1.5 2.0 2.5 3.0 3.5 4.0 4.5 5.0 MOS score Speaker similarity 16kHz 48kHz Fig. 3 : Results in MOS scale. AbS-Pm and AbS-Wo correspond to vocoded speech by using PML and WORLD vocoders. Error bars represent two-tailed Student 95% confidence interv als. 3.3. Evaluation en vironment The se ven speech synthesis methods in Fig.1 were ev aluated in terms of speech quality and speaker similarity . Natural and vocoded speech from WORLD and PML were also included in the e valuation. All the systems except for the W av enet-based SAR-Wa were rated at sampling rates of 48 and 16 kHz. The speech samples of these systems were natural or generated at 48 kHz, and the 16 kHz samples were do wn-sampled from these 48 kHz samples. SAR-WA only generated samples of 16 kHz. All samples were normalized to -26 dBov , and a total of 19 groups of speech samples were ev aluated. The ev aluation was crowdsourced online. Each ev aluation set had 19 screens, i.e., one for each system. The order of systems in each set was randomly shuffled. The ev aluators must answer two questions on each screen. First, they listened to a sample of the system under evaluation and rated the naturalness on a 1-to-5 MOS scale. They then rated the similarity of that test sample to the natural 48 kHz sample on a 1-to-5 MOS scale. The participants were allowed to replay the samples. The samples in one set were synthesized for the same text randomly selected from the test set. 3.4. Results and discussion W e collected a total of 1500 evaluation sets, i.e., 1500 scores for each system. A total of 235 nativ e Japanese listeners participated, with an av erage of 6.4 sets per person. The statistical analysis was based on unpaired t-tests with a 95% confidence margin and Holm-Bonferroni compensation. The results are plotted in Fig. 3. On acoustic modeling, the comparisons of the speech quality score among RNN-Wo , RGA-Wo , SAR-Wo , and SGA-Wo indicated that SAR (3.03) > SGA (2.82) ∼ RGA (2.81) > RNN (2.53) for both 48 kHz and 16 kHz. The same ordering can be seen in terms of speaker similarity . RNN’ s unsatisfactory performance may be due to the over -smoothing effect on the generated MGC, which muffled the synthetic speech. This effect is indicated by the global variance (GV) plotted in Fig. 5, where the GV of the generated MGC from RNN was smaller than that of the other models. The performance of SAR is consistent with that in our previous work [8], which indicated 2k 4k 8k Frequency (Hz) 150 200 Natural 2k 4k 8k Frequency (Hz) 150 200 SAR-Wa (greedy) 150 200 SAR-Wa (random) 150 200 SAR-Pr 150 200 SAR-Pm 150 200 SAR-Wo Fig. 4 : Spectrogram (top) and instantaneous frequency (bottom) of natural speech sample, synthetic samples from SAR-Wa using greedy generation, SAR-Wa using random sampling, SAR-Pr , SAR-Pm and SAR-Wo . T est utterance ID is A OZORAR 03372 T01. 0 1 2 3 4 5 6 7 8 − 2 − 1 0 1 Natural RNN RGA SAR SGA 10 12 14 16 18 20 22 24 − 3 . 5 − 3 . 0 − 2 . 5 − 1 . 5 26 28 30 32 34 36 38 40 42 − 4 . 0 − 3 . 6 − 3 . 0 − 2 . 4 44 46 48 50 52 54 56 58 − 4 . 2 − 3 . 8 − 3 . 2 − 2 . 6 Dimension inde x of MGC Utterance-le v el GV of MGC Fig. 5 : Global variance (GV) of natural and generated MGC av eraged on test set. 0 500 1000 1500 2000 8 4 2 8 Natural RNN RGA SAR SGA Frequency bin index Modulation spectrum (MGC 11th-dim) Fig. 6 : Modulation spectrum of 11th dimension of MGC for test utterance A OZORAR 03372 T01. that the AR model alleviated the ov er-smoothing ef fect. The GAN- based postfilter in both SGA and RGA also reduced the impact of over -smoothing. Further , GAN not only enhanced GV but also compensated for the modulation spectrum (MS) of the generated MGC throughout the whole frequency band, which can be seen from Fig. 6. Ho wever , neither SGA nor RGA outperformed SAR even though SAR did not boost the MS in the high frequenc y bands. After listening to the samples, we found that, while the samples of SGA and RGA had better spectrum details, they contained more artifacts. This indicated that generators in SGA and RGA may not optimally learn the distribution of natural MGC. Future work will look into details on SGA and RGA. On waveform generation methods, the comparison among SAR-Wa , SAR-Pr , SAR-Pm , SAR-Wo , and vocoded speech showed that SAR-Wa significantly outperformed other wav eform generation methods in terms of speech quality . More interestingly , SAR-Wa ’ s quality was e ven judged to be better than other synthetic methods by using a 48 kHz sampling rate. The quality of SAR-Wa was also close to the 16 kHz vocoded samples from Abs-Pm and Abs-Wo . A closes inspection of the samples showed that the W avenet v ocoder in SAR-Wa had fe wer artifacts, such as amplitude modulation in the wa veform and other ef fects possibly due to con ventional v ocoders. Howe ver , the gap between SAR-Wa and Abs-Wo / Abs-Pm was still large in terms of speaker similarity . One reason may be that, while the W avenet vocoder trained by using natural acoustic features may well learn the mapping from acoustic features to wa veforms, during wa veform generation it cannot compensate for the degradation of generated acoustic features caused by the imperfect acoustic model SAR . Note that this problem may not be resolved by training the W av enet vocoder using generated acoustic features if the acoustic model is not good enough. Among other wav eform generation methods, the PML vocoder , while being similar to WORLD for analysis-by-synthesis, it lagged behind when using the generated acoustic features. This result is somewhat different from that in [11], and future work will in vestigate the reasons for this. Comparison between SAR-Pr and SAR-Wo indicated that the phase recov ery method did not improve the quality or similarity score. W e suspect that this is because the iterativ e process in the Grif fin-Lim algorithm may introduce some artifacts that degraded speech quality . 4. CONCLUSION This work was our initial step in building a framework in which recent acoustic modeling and wav eform generation methods could be compared on a common ground by using a lar ge-scale perceptual ev aluation. This work only considered a few methods that could easily be plugged into the common TTS pipeline. On acoustic models, the results showed that the autoregressive model SAR could achie ve a better performance than a normal RNN. This SAR was also easier to train than a GAN-based model. On wa veform generation methods, this work demonstrated the potential of the W avenet vocoder and the advantage of statistical wav eform modeling compared with con ventional deterministic approaches. W e intend to in vestigate the reasons for the experiments’ results in more detail in future work. Meanwhile, we recently v alidated that SAR is a simple case of using normalizing flow [27] to transform the density of target data. W e will try to improve SAR and the overall performance of speech synthesis system. Complex-valued models that support the modeling of wa veform phases may also be included. 5. REFERENCES [1] Y uxuan W ang, R.J. Skerry-Ryan, Daisy Stanton, Y onghui W u, Ron J. W eiss, Navdeep Jaitly , Zongheng Y ang, Y ing Xiao, Zhifeng Chen, Samy Bengio, Quoc Le, Y annis Agiomyrgiannakis, Rob Clark, and Rif A. Saurous, “T acotron: T owards end-to-end speech synthesis, ” in Pr oc. Interspeech , 2017, pp. 4006–4010. [2] Jose Sotelo, Soroush Mehri, Kundan Kumar , Jo ˜ ao Felipe Santos, Kyle Kastner , Aaron Courville, and Y oshua Bengio, “Char2wa v: End-to-end speech synthesis, ” in Pr oc. ICLR (W orkshop T rac k) , 2017. [3] Aaron van den Oord, Sander Dieleman, Heiga Zen, Karen Simonyan, Oriol V inyals, Alex Gra ves, Nal Kalchbrenner, Andrew Senior , and K oray Kavukcuoglu, “W avenet: A generative model for raw audio, ” arXiv preprint arXiv:1609.03499 , 2016. [4] Felipe Espic, Cassia V alentini Botinhao, and Simon King, “Direct modelling of magnitude and phase spectra for statistical parametric speech synthesis, ” in Pr oc. Interspeech , 2017, pp. 1383–1387. [5] Shinji T akaki, Hirokazu Kameoka, and Junichi Y amagishi, “Direct modeling of frequency spectra and waveform generation based on phase recovery for DNN-based speech synthesis, ” in Proc. Interspeech , 2017, pp. 1128–1132. [6] Srikanth Ronanki, Oliver W atts, and Simon King, “ A hierarchical encoder-decoder model for statistical parametric speech synthesis, ” in Proc. Interspeech , 2017, pp. 1133–1137. [7] T akuhiro Kaneko, Hirokazu Kameoka, Nobukatsu Hojo, Y usuke Ijima, Kaoru Hiramatsu, and K unio Kashino, “Generativ e adversarial network-based postfilter for statistical parametric speech synthesis, ” in Pr oc. ICASSP , 2017, pp. 4910–4914. [8] Xin W ang, Shinji T akaki, and Junichi Y amagishi, “ An autoregressi ve recurrent mixture density network for parametric speech synthesis, ” in Pr oc. ICASSP , 2017, pp. 4895–4899. [9] Akira T amamori, T omoki Hayashi, Kazuhiro Kobayashi, Kazuya T akeda, and T omoki T oda, “Speaker -dependent W aveNet vocoder , ” in Pr oc. Interspeech , 2017, pp. 1118–1122. [10] Masanori Morise, Fumiya Y okomori, and Kenji Ozawa, “WORLD: A vocoder-based high-quality speech synthesis system for real-time applications, ” IEICE T rans. on Information and Systems , vol. 99, no. 7, pp. 1877–1884, 2016. [11] Gilles Degotte x, Pierre Lanchantin, and Mark Gales, “ A log domain pulse model for parametric speech synthesis, ” IEEE/A CM T ransactions on Audio, Speech, and Language Pr ocessing , 2017. [12] Daniel Griffin and Jae Lim, “Signal estimation from modified short-time Fourier transform, ” IEEE T rans. ASSP , vol. 32, no. 2, pp. 236–243, 1984. [13] Xin W ang, Shinji T akaki, and Junichi Y amagishi, “ An RNN- based quantized F0 model with multi-tier feedback links for text-to-speech synthesis, ” in Proc. Interspeech , 2017, pp. 1059–1063. [14] T okuda K eiichi, Y oshimura T akayoshi, Masuko T akashi, K obayashi T akao, and Kitamura T adashi, “Speech parameter generation algorithms for HMM-based speech synthesis, ” in Pr oc. ICASSP , 2000, pp. 936–939. [15] Ranniery Maia, Masami Akamine, and Mark J.F . Gales, “Complex cepstrum as phase information in statistical parametric speech synthesis, ” in Pr oc. ICASSP , 2012, pp. 4581–4584. [16] Gilles Degottex and Daniel Erro, “ A uniform phase representation for the harmonic model in speech synthesis applications, ” EURASIP J ournal on Audio, Speech, and Music Pr ocessing , vol. 2014, no. 1, pp. 38, Oct 2014. [17] Qiong Hu, Junichi Y amagishi, Korin Richmond, Katrick Subramanian, and Y annis Stylianou, “Initial in vestigation of speech synthesis based on complex-valued neural networks, ” in Pr oc. ICASSP , March 2016, pp. 5630–5634. [18] T oru Nakashika, Shinji T akaki, and Junichi Y amagishi, “Complex-v alued restricted Boltzmann machine for direct learning of frequency spectra, ” in Pr oc. Interspeech , 2017, pp. 4021–4025. [19] Hideki Kawahara, Ikuyo Masuda-Katsuse, and Alain de Chev eigne, “Restructuring speech representations using a pitch-adaptive time-frequency smoothing and an instantaneous-frequency- based F0 extraction: Possible role of a repetitive structure in sounds, ” Speech Communication , vol. 27, pp. 187–207, 1999. [20] T akuhiro Kaneko, Shinji T akaki, Hirokazu Kameoka, and Junichi Y amagishi, “Generativ e adversarial network-based postfilter for STFT spectrograms, ” in Pr oc. Interspeech , 2017, pp. 3389–3393. [21] Y ajun Hu, Chuang Ding, Li Juan Liu, Zhen Hua Ling, and Li Rong Dai, “The USTC system for Blizzard Challenge 2017, ” in Proc. Blizzard Challenge W orkshop , 2017. [22] Boualem Boashash, “Estimating and interpreting the instantaneous frequency of a signal. ii. algorithms and applications, ” Proceedings of the IEEE , vol. 80, no. 4, pp. 540–568, 1992. [23] Jesse Engel, Cinjon Resnick, Adam Roberts, Sander Dieleman, Mohammad Norouzi, Douglas Eck, and Karen Simon yan, “Neural audio synthesis of musical notes with WaveNet autoencoders, ” in Proc. ICML , 2017, pp. 1068–1077. [24] Hisashi Kawai, T omoki T oda, Jinfu Ni, Minoru Tsuzaki, and Keiichi T okuda, “XIMERA: A new TTS from A TR based on corpus-based technologies, ” in Pr oc. SSW5 , 2004, pp. 179– 184. [25] The HTS W orking Group, “The Japanese TTS System ‘Open JT alk’, ” 2015. [26] Felix W eninger , Johannes Bergmann, and Bj ¨ orn Schuller , “Introducing CURRENT: The Munich open-source CUD A recurrent neural network toolkit, ” The J ournal of Machine Learning Resear ch , vol. 16, no. 1, pp. 547–551, 2015. [27] Danilo Rezende and Shakir Mohamed, “V ariational inference with normalizing flows, ” in Pr oc. ICML , 2015, pp. 1530–1538.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment