An improved DNN-based spectral feature mapping that removes noise and reverberation for robust automatic speech recognition
Reverberation and additive noise have detrimental effects on the performance of automatic speech recognition systems. In this paper we explore the ability of a DNN-based spectral feature mapping to remove the effects of reverberation and additive noi…
Authors: Juan Pablo Escudero, Jose Novoa, Rodrigo Mahu
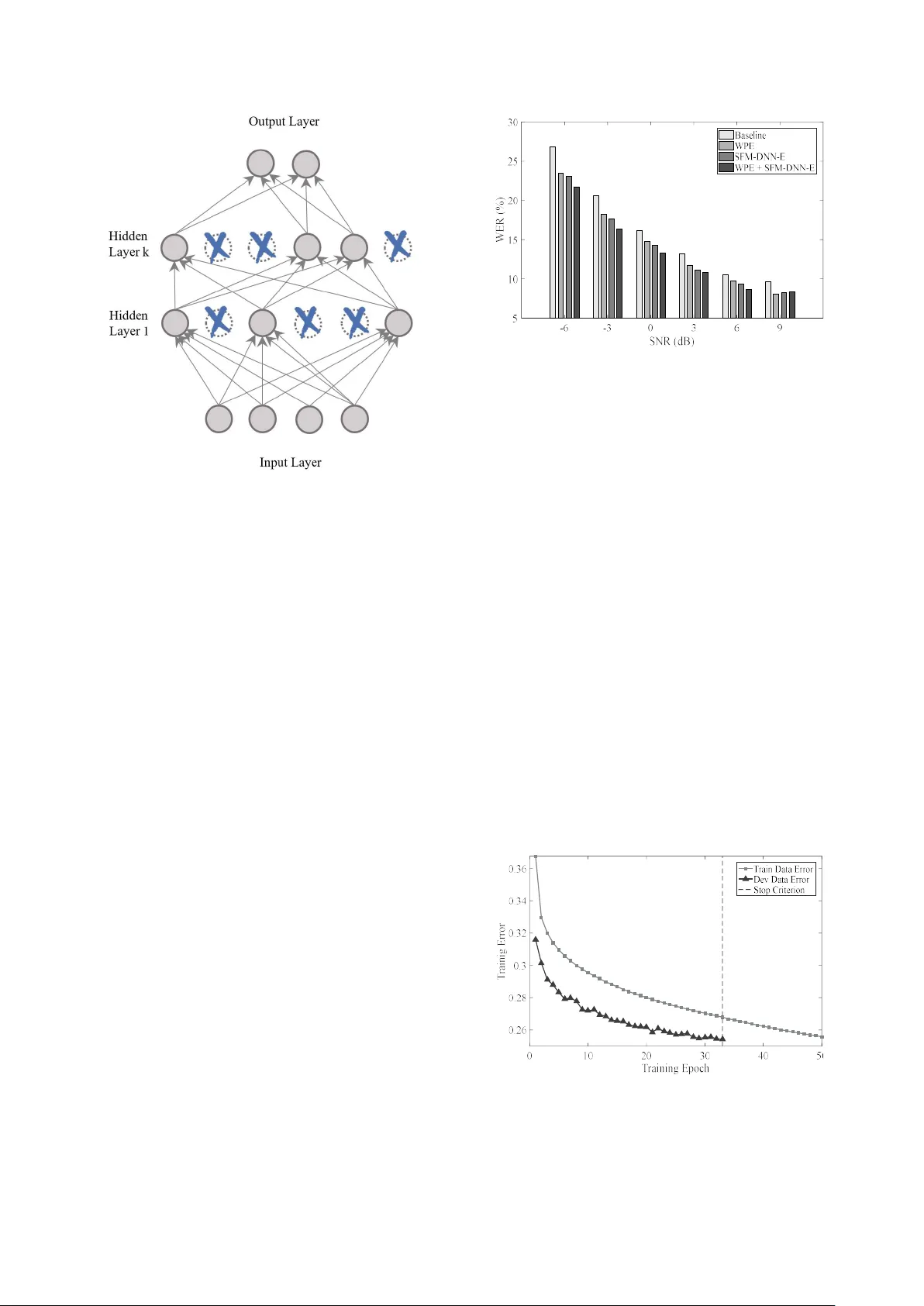
An im proved DNN-b ased spectral featur e m apping that r em oves noise and reverberat ion for r obust a utomatic speech r ecognition Juan Pablo Escudero 1 , José Novoa 1 , Rodrigo Mahu 1 , Jorge W uth 1 , Fernando Huenupán 2 , Richard Stern 3 and Néstor Becerra Yoma 1 1 Speech Processing and Transmission Laborator y, Electrica l Engineerin g Department, Universidad de Chile, Santiago, Chile. 2 Department of Electrical Engineering, Universidad de la Frontera, Temuco, Chile. 3 Department of Electrical and Computer Engineering and Language Technologies Institute, Carnegie Mellon Universit y , Pittsburgh, USA. nbecerra@in g.uchile.cl Abstract Reverberation and additive noise have detrimental effects on the performance of au tomatic speech recognitio n systems. In this paper we explore the ability of a DNN-based spectral feature mapping to rem o ve the effects of reverberat ion and additive noise. Experiments with the CHiME -2 d atabase sho w that this DNN can achieve an average reduction in WER of 4.5%, when compared to the b aseline system, at SNRs equal to -6 d B, -3 dB, 0 dB and 3 dB, and ju st 0.8% at greater SNRs of 6 dB and 9 d B. These results s uggest that th is DNN is more effective in removing add itive noise tha n reverberation. T o improve the DNN p erformance, we combine it with t he weighted prediction error (WPE) method that shows a complementary b ehavior. While this co mbination pro vided a reduction in WER o f approximately 11% when compared with the baseline, the observed improvement is no t as great as that obtained using WPE alone. However, modificatio ns to the DNN tr aining process were a pplied and an av erage reduction in WER equal to 18.3% was ach ieved when compared with the baseline system. Furthermore, the improved DNN combined with WP E achieves a redu ction in WER o f 7.9% when compared with WPE alon e. Index Terms : speech recognition, r everberation, DNN-based speech enhancement 1. Introduction In indoor en vironment, the reverberation and additive noise have detrimental effec ts on the performance of A SR systems [1]. Therefore, th e challenge is to implement methods capable of reducing or eliminating th e reverberation and the additive noise in speech signals [2] [3] . The methods are divided in three classes depending on where they are implemented in an ASR system: front-end; back-end; and, speech preprocessing [4]. The p reprocessing methods are also known as speech enhancement (SE). The use of neural networks ( NN) for SE or speech distortion removal is not n ew. In [5] a multil ayer perceptron NN in spired in the Lateral Inhibitio n pr ocess was p roposed to cancel additive noise. Som e DNN methods are focused on learning clean version of MFCC featu res using either d e- noising autoencoders [6] [ 7] or recurrent neural n etwork (RNN) [8]. Fu rthermore, spectral su btraction and a RNN based de-noising autoencoder were implemented to lea rn Mel filterbank features from the noise [9]. Particularly, in [10] a DNN-based sp ectral feature mapping (named SFM-DNN he re and after) was proposed. SFM-DNN has the capability to map spectral features on Mel filterbank features, while in the process the additive n oise and reverberation are canceled or reduced. H owever, the r esulting SFM-DNN removes addit ive n oise more effectively than reverberation. SFM-DNN w as built w ith a m ult ilayer perceptron composed of two hid den layers, each o ne with 2048 units, and one o utput layer w it h 40 units. The activation f u nctions of both h idden and output layer correspond to the sigmoid function. The input is fed with spectrograms extracted from corrupted voice samples. The reference used to train de DNN were the log Mel filterbank features extracted from th e corresponding clean speech samples. The input f e atures were normalized to zero m ean and unit variance over all f e ature vectors in th e training set. Since temporal dynamics incorporates rich information for sp eech, 10 n eighborhood frames were included to the current frame. The reference features were normalized in a ra nge of [0,1]. The DNN was trained using the backpropagation with mini-b atch sto chastic gradient descendent algorithm. The adaptive gradient descendent was used as op timization technique and the cost function was based on the mean square error . WPE is a widely emplo yed enhancement method for de- reverberation corresponds [11]. WPE has led to s ignificant improvements in ASR acc uracy under different rever b erant conditions [2]. This method is focused on th e reverberation suppression by means o f the iterative esti mation o f linear regression filter coefficients. T he techn ique performs the coefficient est imation using the short time Fourier transform (STFT). At th e end of the p rocess, a reverberation free speech time waveform is obtained. In this paper w e improve the SFM-D NN performance b y making use of WPE. Furthermore, we introduced modifications to the SFM-DNN training process to improve its effectiveness in distor tion removal. As a result, a final WER equal to 13.2% and a relative reduction in WER as h igh as 18.3% when compared to the baseline system with noisy training were achie ved. The r esults reported in th is paper are very competitive with th ose published elsewhere using the same database th at was presently e mployed [12] [ 10] [13] [1 4] [15]. Also, the reduction in WER when compared to the original SFM-DNN was 15.1% In section 2 we present and justify the combination of SFM-DN N with WPE. Section 3 describes the modifications and improvements incorporated to the SFM- DNN training p rocess. The discussio ns and conclusions are pre sented in sections 4 and 5, respectively. 2. Combining the DNN with WPE First of a ll, w e replicated the r esul ts reported in [10]. The experiment was performed usin g the CHiME-2 track 2 database [3]. DNN was implemented using th e T ensorFlow’s Python API [16]. The ASR experi ments were con ducted using t he Kaldi toolkit [17]. The ASR system is based on a DNN-HMM, which use as inpu t 40-dim entional log Mel f i lterbank with deltas and delta-delta dynamic f eatur es from an 11-frame context window. The DNN-HMM was train ed using th e tied triphone state targets o btained from a clean G M M-HMM alignment. A realign ment was performed using the trained DNN [ 18], then a retrain of the DNN was perfor med with th e new alignme nt. The DNN-HM M was improved appl ying sMBR-based sequenc e training on the DNN [19]. Table 1 shows the WERs reported in [10] and the validated results with th e local system. These results suggest that SFM-DNN has the abil ity to redu ce th e effect o f add itive noise rather than reverberatio n. For this reason, we could improve the SFM-DNN p erformance by combining it with a SE method focused on reverberation reduction, i.e. WPE. The cascade configuration of enhancement method s deserves a brief d iscussion. For instance, in [2 0] it is discussed that the channel response can ef fectively be removed after th e additive noise bein g ca n celled by con sidering that the former is suppo sed time-invariant and the latter can be n on-stationary. However, in the case con sidered h ere, the r everberation and additive noise can be both assumed no n-stationary. Consequently, the order in the cascade removal would not seem relevant. However, in t he case con sidered here, the cascade sequ ence order is constrained b y the input and o utput of SFM-DNN. As a result, we proposed the scheme sho wn in Fig. 1. Figure 2 shows t he redu ctions in WER c ompared to the baseline syste m (n oisy training, Table 1) p rovided by SF M- DNN and WPE methods vs. SNR. The SF M-DNN scheme provides a r eduction in WER that decreases when SNR increases. Actually, at SNR equal to 9 dB SFM-DNN introduces a distortion. These results sugg est that SFM-DNN cancels more effectively the additive noise rather than reverberation. I n contrast, W P E provides a reduction in WER Table 1 : WER (%) corre sponding to the va lidation results of the original SFM-DNN using C HiME-2 noisy training with clean alignment [10] . System Training Test Noisy [10] SFM-DNN [10] Noisy (Local) SFM-DNN (Local) -6 dB 28.2 28.0 26.8 24.8 -3 dB 20.7 19.9 20.6 19.5 0 dB 16.3 14.8 16.2 15.7 3 dB 13.1 11.9 13.2 13.0 6 dB 9.5 10.2 10.6 10.6 9 dB 9.1 8.9 9.7 9.8 Avg. 16.1 15.6 16.2 15.6 Figure 1: Blo ck diagram of the propo sed cascade sequence of SE meth ods. 𝑥 ( 𝑡 ) , 𝑥 (𝑡 ) , 𝑋 (𝑘) and x(𝑚) represent, respectively, the speech signal in the temporal domain, the f ree reverberation speech time waveform, log spe c tral magnitud e and th e resulting M el filterbank enhanc ed speech signal. Figure 2: Reduc tion in WER with respect to th e Baseline, for WPE and S FM-DNN systems . Reduction in WER (%) Figure 3: WER ( % ) with the ba seline, WPE, SFM- DNN and WPE+SFM-DNN systems. that is relatively constant up to SNR equal to 6 dB and then increases significantly when SNR is equal to 9 dB. Figure 3 shows th e results of ASR experiments obtained with the Baseline, WPE, SFM-DNN and WPE+SFM-DNN (according to Fig.1) sy ste ms. Wh en c ompared to the baseline system, SFM-DNN and WPE+SFM-DNN provid ed reductions in WER equal to 7.3% and 10.8%, respectively, which in turn validates the pr oposed approach illustr ated in Fig. 1. However, WPE led to a higher WER reduction (11.4%) than WPE+SFM-DNN. Consequently , while SFM-DNN w as improved with the addition of WPE, the resulting WPE+SFM-DNN system i s somehow limited by th e performance of SFM-DNN. This result motivated u s to improve th e SFM-DNN effectiveness by in corporating modifications to the tr aining process. 3. DNN training modifications and improvements In order to improve the SFM-DNN effectiveness we explored the use o f dropout, cross-validation and alternative in put- reference n ormalization. Our reference w as the training procedures described in [10] and the on e employed to replicate the results in Table 1. 3.1. Dropout In large n eural networks it is difficult to cope with overfitting. An alternative to address th is problem, without increas ing the size of the databas e, is to apply the dropout scheme which temporarily deactivates uni ts durin g training [ 21]. Fig. 4 shows a graphic description of this method. 3.2. Cross-validation Overfitting may also be observed if th e multila yer perceptron or DNN backpropagation-based training procedure is not stopped at the right tim e [22]. T o av oid this p roblem, a cross validation m ethod can b e applied with a development set, i.e. after performing a given number of training epochs, the training is pause d and the development set is propagated to compute the corresponding cost error . If th e development set error cost increases or reaches a con vergence criterio n, the training is stopped and the n eural network parameters of th e previous epoch are retrieved. Otherwise, the training process is resumed. In this paper, the cross-validation scheme was performed in each training epoch. In our SFM-DNN implementation, cross-validation was carried out with the CHiME-2 track 2 development set. The training was sto pped if one o f th e two conditions was reached: the develop ment error cost in creases in 1% with respect t he previous epoch ; o r, the development error co st decreases by less than 0.1% with respect the previous epoc h. 3.3. Input-reference data normalization As discussed in [23] [22], the n eural network training procedure is sensitive to previous no rmalization (i.e. MVN or MN) performed to th e input and reference features durin g the DNN training stage. Also, th e results reported in [24] su ggest that the u tterance-by-utterance n ormalizations may g ive better results than, for instance , on a speaker-b y-speaker basis. Consequently, we app lied MVN to both the input and reference data on an utteranc e-by-utterance basis. Figure 4 : Graphic description of the dropout method for a typical neural ne twork architecture. Figure 5: WER (%) with the baseline, WPE, SFM- DNN-E and WPE+SFM-DNN-E systems. Figure 6: SF M- DNN-E training error fo r both training and d evelopment databases, using cross-validation method. Vertical line indicates the stop criterion. 3.4. Enhanced SFM-DNN We incorpora ted dropout, cross-validation and utterance-by- utterance MVN normalization to the SFM-DNN training procedure. The WERs pro vided b y the resulting system, SFM-DNN-E, are shown in Fig. 5. Figure 6 shows th e evolution of the error cost with both the training and development data. The early st op of th e training procedure should avoid th e overf i tting effect. 4. Discussion According to Table 1 , we were a ble to achieve similar results to those repo rted in [10] with SFM-DNN. A ccor dingly, SFM-DNN increased the WER in 0.8% when compared to th e baseline system , i.e. no isy trainin g, in cond itions where there is less presence of additive noise and more presence of reverberation, i.e. 6 and 9 dB. As mentioned above, th ese results were our motivation to include a SE method, i.e. WPE, to r educe the effect o f reverberatio n. As c an be se en in Fi g. 2, WPE presents a complementary behavior when compared to SFM-DNN with respect the improvement in recognition accuracy vs. SNR. As a result, the WPE+SFM-DNN system reduced the WER in 10 .8% when compared to the baselin e. However, WPE led to a higher WER reduction (11.4%) t han WPE+SFM-DNN. SFM-DNN was improved by incorporatin g modifications to the training procedure. As can be seen in Fig. 7, the resulting SFM-DNN-E system provided a WER that is 10.4% lower than the original SFM-DNN. When c ompared to WPE alone and the baselin e system, WPE +SFM-DNN-E le d to reductions in WER equal to 7 .9% and 18.3%, respectively. The final average WER was 13.2% a nd compares very favorably with the on e publishe d elsewhere [12] [ 10] [13] [1 4] [15] with the same database, i.e. CHiME-2. 5. Conclusion In this paper th e effectiveness of a spec tral f eature mapping DNN is improved to remove th e effects of reverberation and additive noise. Experiments with the CHiME -2 d atabase sho w that this DNN is more effective in removing additive noise than r everberation. To counteract th is li mitation the DNN was combined w it h WPE that s h ows a com plementary behavior with respect to the improvement in r ecognition accuracy vs. SNR. Also, modifications to th e DNN training process were successfully appli ed. As a con sequence, a final avera ge WER equal to 13.2% and a relative reduction in WER as h igh as 18.3%, when compared to the baseline system with no isy training, were a chieved. These res ults are v ery competitive with those published elsew here using CHiM E-2 database. 6. Acknowle dgements The research reported h ere was funded by Grants Conicyt- Fondecyt 1 151306 and ONRG N °62909-17-1-2002. José Novoa was supported by G r ant CONICYT-PCHA/Doctorado Nacional/2014-21140711. 7. References [1] M. Delcroix, T. Yoshioka , A. Ogawa, Y. Kubo, M. Fujimoto, N. Ito, K. Kinoshita, M. Espi, S. Araki, T. Hori and T. Nakatani, “Str ategies for dist ant speech recognitionin reverberant environments,” EURASIP Journal on Advances i n Signal Processing, vol. 2015, no. 1, p. 60, 2015. [2] K. Kinoshita, M. De lcroix, T. Yoshioka, T. Nakatani, A. Sehr, W . Ke ll ermann and R. Maa s, “The reverb challenge: Acommon evaluation framework for dereverberation and recognition of reverberant sp eech,” in Proc. of WASPAA , New Paltz, NY, USA, 2013. [3] E. Vincent, J. Barker, S. Watanabe, J. Le Roux, F. Nesta and M. Matassoni, “T h e second ‘CHiME’speech separation and r ecognition ch allenge: An overview o f challenge syste ms and outcomes,” in Automatic Spee ch Recognition and Understanding (ASRU), 2013 IEEE Workshop , Olomouc, 2013. [4] A. Tsilfidis, I. Mporas, J. M ourjopoulos and N. Fakotakis, “Automatic speech recognition performance in different room acoustic environments with and without dereverberation p reprocessing,” Computer Speech & Language, p p. 380 - 395, 2013. [5] N. Yoma, F. McInnes an d M. Jack, “Lateral inhibition net and weighted matching algor ithms for speech recognition in noise,” in IEE Pr oceedings- Vision, Image and Signal Processing , 1996. [6] T. Ishii , H. Ko miyama, T. Sh inozaki, Y . Horiuchi and S. Kuroiwa, “Reverberant speech recognition b ased on denoising autoencoder,” in Proceedings of INTERSPEECH , Lyon, France, 2013. [7] X. Feng, Y. Zhang and J. Glass, “Speech feature denoising and dereverberation via deep autoencoders f o r a) b) Figure 7: WER ( %) vs. SNR: a) SFM-DNN and SFM-DNN-E; a nd, b) WPE+SFM-DNN and WPE+SFM-DNN-E. W E R ( % ) W E R ( % ) noisy reverberant sp eech recognition,” in Proceedings of ICASSP , Florence, Italy, 2014. [8] A. L. Maas, T. M. O’Neil, A. Y. Hann un and A . Y. Ng, “Recurrent neural network featu re enhancement: The 2n d CHiME challenge,” in Proceedings The 2nd CHiME Workshop on Machine Listening in Multisource Environments held in con junction with ICASSP , 2013. [9] F. Weninger, S. Watanabe, Y. Tachioka and B. Schuller, “Deep rec u rrent de-noising a uto-encod er a n d blind de- reverberation for reverberated speech recog nition,” in Proceedings of ICASSP , Florence, Italy, 2014. [10] K. Han, Y. He, D. Bagchi, E. Fo sler-Lus sier and D. Wang, “De ep neural n etwork based sp ectral feature mapping for robust sp eech recognition ,” in Proceedings of INTERSPEECH , Dresden, Germany, 2015. [11] T. Nakatani, T. Yoshioka, K. Kinoshita, M. Miyoshi and B. Ju ang, “Speech d ereverberation based on variance- normalized delayed linear pr ediction,” IEEE Transactions on Audio, Speech, and Language Processing, vol. 18, no. 7, pp. 1717 - 1731, 2010. [12] A. Narayanan, Computational au ditory scene analysis and robust a ut omatic speech recognition, Th e Ohio State University, 2014. [13] H. Erdogan, J. R. Hershey, S. Watanabe and J. Le Roux, “Deep Recurrent Networks for Separation and Recognition of Single- Channel Speech in Nonstationary Background Audio,” in New Era for Robust Speech Recognition , Spr inger, 2017, pp. 165 - 186. [14] K. Nathwani, E. Vincent and I. Illina, “DNN Uncertainty Propagation usin g GMM- Derived Uncertain ty Features for Noise Ro bust ASR,” IEEE S ignal Processing Letters, vol. 25, no. 3, pp. 338 - 342, 2018. [15] K. Nathwani, J. A. Mo rales- Cordovilla, S. Sivas ankaran, I. Illina and E. Vincent, “An extended experimental investigation of DNN uncertainty p ropagation for noise robust ASR,” in Proceeding s of Hands- free Speech Communications and Microphone Arrays , San Francisco, CA, USA, 2017. [16] M. A badi, P. Barham , J. Chen, Z. C hen, A . Dav is, J. Dean, M. Devin, S. Ghemawat, G. Irving, M. Isard, M. Kudlur, J. Levenb erg, R. Mon ga, S. Moore, D. M urray, B. Steiner, P. Tucker, V . Vasudevan, P. Warden, M. Wicke, Y. Yu and X. Zheng, “TensorFlow: A s yste m for large-scale m ac hine learning,” in 12th USENIX Symposium o n Operating S ystems Design , Savannah , 2016. [17] D. Pove y , A. Ghoshal, G. Bo ulianne, N. Goel, M. Hannemann, Y. Qian, P. Schwarz and G. Stemmer, “The Kaldi Sp eech Recognition Toolkit,” in IEE E 2011 Automatic Speech Recognition and Understanding Workshop , Hawaii, USA, 2011. [18] C. W eng, D. Yu, S. Watanabe and B. Juang, “Recurrent deep neural n etworks for robust speech recognition,” in ICASSP , Florence, 2014. [19] B. Kingsbury, “L atti ce-b ased optimization of seq uence classification criteria for ne ural- network acou stic modeling,” in ICASSP , Taipei, 2009. [20] N. Becerra Yo ma, F. R. McInnes and M. A. Jack, “Weighted Matchin g Algorithms an d Reliability in Noise Canceling by Spectral Subtr a ction,” in Proceedings of the IEEE International Conference on A coustics, Speech , Munich, Germany, 1997. [21] N. Srivastava, G. Hinton, A. Krizh evsky , I. Su tskever and R. Salakhutdinov, “Dropout: A simple way to prevent neural networks f rom overfitting,” The Journal of Machine Lear ning Research, vol. 15, no. 1, pp. 1929- 1958, 2014. [22] S. Haykin, Neural networks and learnin g machines, New Jersey: Pearson Upper Saddle River, 2009 . [23] D. Yu and L. Deng, Automatic Speech Recognition, Springer, 2016. [24] J. Fredes, J. Novoa, S. King, R. Stern an d N. Becerra Yoma, “Locally no rmalized filter banks applied to d eep neural-network-based robust speech r ecognition,” IEEE Signal Proce ssing Letters, vol. 24, no. 4 , pp. 377- 381, 2017.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment