Asynchronous Parallel Algorithms for Nonconvex Optimization
We propose a new asynchronous parallel block-descent algorithmic framework for the minimization of the sum of a smooth nonconvex function and a nonsmooth convex one, subject to both convex and nonconvex constraints. The proposed framework hinges on successive convex approximation techniques and a novel probabilistic model that captures key elements of modern computational architectures and asynchronous implementations in a more faithful way than current state-of-the-art models. Other key features of the framework are: i) it covers in a unified way several specific solution methods; ii) it accommodates a variety of possible parallel computing architectures; and iii) it can deal with nonconvex constraints. Almost sure convergence to stationary solutions is proved, and theoretical complexity results are provided, showing nearly ideal linear speedup when the number of workers is not too large.
💡 Research Summary
The paper addresses the challenging problem of solving large‑scale nonconvex optimization tasks in modern parallel computing environments where asynchronous updates are inevitable. The authors consider a very general formulation (P) that consists of a smooth possibly nonconvex loss function f(x), a sum of block‑wise convex nonsmooth regularizers g_i(x_i), and closed constraint sets X_i that may themselves be nonconvex. This setting captures a wide range of applications such as compressed sensing, machine‑learning model fitting, and genomic data analysis.
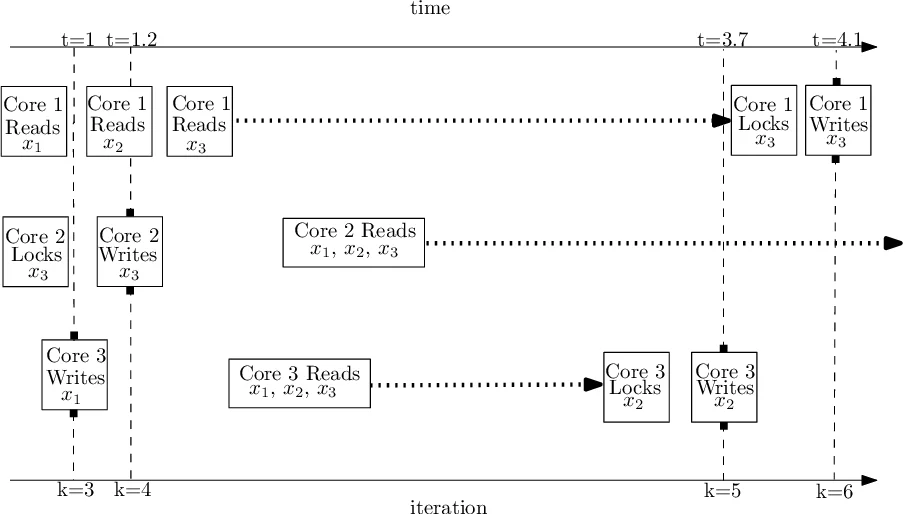
The core contribution is an asynchronous block‑coordinate descent (BCD) framework built on successive convex approximation (SCA). At iteration k a worker selects a block i_k and works with a delayed copy of the whole variable vector, denoted x_{k−d_k}, where d_k is a vector of integer delays. Unlike most prior works, the authors do not assume independence between the block index i_k and the delay vector d_k, nor do they require uniform random block selection. Instead, they introduce a joint probabilistic model for (i_k, d_k) that explicitly captures realistic dependencies observed in shared‑memory, message‑passing, and cloud‑federated systems. Empirical measurements on an Intel Xeon‑based 10‑core machine and on a two‑node cluster illustrate that delays can vary dramatically across blocks and workers, confirming the need for such a model.
Given the delayed estimate x_{k−d_k} and the chosen block i_k, the worker solves a strongly convex surrogate subproblem:
\
Comments & Academic Discussion
Loading comments...
Leave a Comment