Machine Speech Chain with One-shot Speaker Adaptation
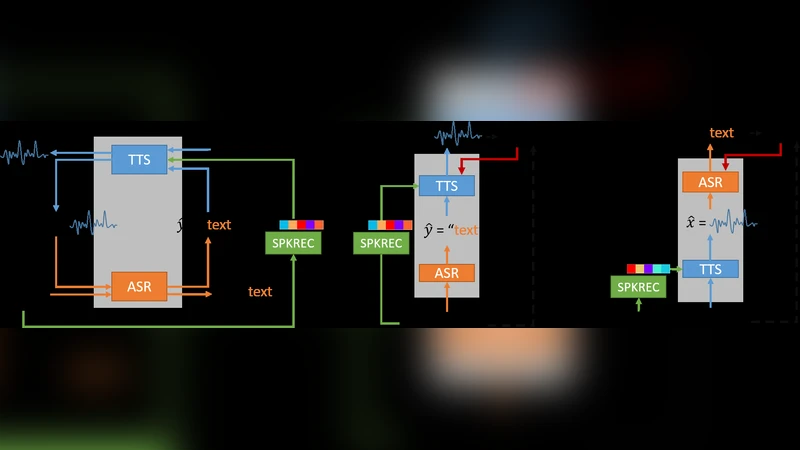
In previous work, we developed a closed-loop speech chain model based on deep learning, in which the architecture enabled the automatic speech recognition (ASR) and text-to-speech synthesis (TTS) components to mutually improve their performance. This was accomplished by the two parts teaching each other using both labeled and unlabeled data. This approach could significantly improve model performance within a single-speaker speech dataset, but only a slight increase could be gained in multi-speaker tasks. Furthermore, the model is still unable to handle unseen speakers. In this paper, we present a new speech chain mechanism by integrating a speaker recognition model inside the loop. We also propose extending the capability of TTS to handle unseen speakers by implementing one-shot speaker adaptation. This enables TTS to mimic voice characteristics from one speaker to another with only a one-shot speaker sample, even from a text without any speaker information. In the speech chain loop mechanism, ASR also benefits from the ability to further learn an arbitrary speaker’s characteristics from the generated speech waveform, resulting in a significant improvement in the recognition rate.
💡 Research Summary
The paper revisits the “speech chain” concept—a closed‑loop system where an automatic speech recognizer (ASR) and a text‑to‑speech synthesizer (TTS) teach each other—and addresses two major shortcomings of the original model: (1) poor scalability to multi‑speaker scenarios and (2) inability to handle unseen speakers. To overcome these issues, the authors integrate a speaker‑recognition module (SPKREC) into the loop and extend the TTS with one‑shot speaker adaptation using a DeepSpeaker embedding network.
The overall architecture consists of three neural components: a sequence‑to‑sequence ASR, a sequence‑to‑sequence TTS (based on Tacotron), and a speaker encoder that maps any speech waveform to a fixed‑dimensional L2‑normalized vector z. During training, three data regimes are considered: (i) paired speech‑text data, where ASR and TTS are trained with teacher‑forcing and the speaker encoder supplies z to the TTS; (ii) unpaired speech only, where ASR first predicts a transcription, the speaker encoder extracts z, and TTS reconstructs the waveform from the predicted text and z, allowing a reconstruction loss between the original and regenerated speech; (iii) unpaired text only, where a random speech sample from the training pool provides a speaker vector, TTS generates speech from the text and z, and ASR transcribes it back, yielding a text reconstruction loss. The total loss is a weighted sum of supervised (paired) and unsupervised (unpaired) terms:
L = α(L_P_ASR + L_P_TTS) + β(L_U_ASR + L_U_TTS).
α and β balance the contributions of the two learning signals.
Technical details:
- ASR uses a 3‑layer bidirectional LSTM encoder (256 units per direction) with hierarchical subsampling (factor 8) and a unidirectional LSTM decoder (512 units) with content‑based attention. Beam search (size = 5) is applied at inference.
- TTS builds on Tacotron’s CBHG encoder and adds two LSTM decoder layers (256 units each). The speaker embedding z is linearly projected and summed with the decoder’s previous output before attention. The decoder predicts mel‑spectrogram frames (4 frames per step) which are passed through a CBHG post‑net to obtain linear spectrograms. An end‑of‑speech binary classifier is also trained.
- The loss for TTS comprises (i) L2 distance on mel and linear spectrograms, (ii) binary cross‑entropy for the end‑of‑speech flag, and (iii) cosine distance between the ground‑truth speaker embedding (from real speech) and the embedding extracted from the generated speech, encouraging the synthesized voice to retain the intended speaker characteristics.
- The speaker encoder (DeepSpeaker) is trained on the WSJ SI‑84 subset (83 speakers) and then frozen; it is expected to generalize to unseen speakers.
Experiments were conducted on the Wall Street Journal (WSJ) CSR corpus. The paired set SI‑84 (≈16 h, 83 speakers) served as supervised data, while the larger SI‑200 (≈66 h, 200 distinct speakers) was used as unpaired data. Baseline supervised training on SI‑84 achieved a character error rate (CER) of 17.01 %. When the proposed semi‑supervised speech chain was applied (SI‑84 + SI‑200), CER dropped dramatically to 9.86 %, outperforming a naïve label‑propagation method (14.58 %). Using the full SI‑284 paired set yields an upper‑bound CER of about 7 %, indicating that the semi‑supervised approach recovers most of the performance gap while requiring far fewer labeled utterances. Subjective listening confirmed that the TTS could synthesize intelligible speech for speakers never seen during training, thanks to the one‑shot adaptation.
In summary, the paper makes three key contributions: (1) incorporation of a speaker‑recognition network into the speech chain to explicitly pass speaker identity, (2) a one‑shot speaker adaptation mechanism for Tacotron‑based TTS that enables zero‑shot synthesis of new voices, and (3) a unified semi‑supervised learning framework that leverages both unpaired speech and unpaired text to improve ASR and TTS simultaneously. The results demonstrate substantial gains in multi‑speaker ASR accuracy and open the door to practical systems that can quickly onboard new speakers without costly annotation.
Comments & Academic Discussion
Loading comments...
Leave a Comment