Towards End-to-End Prosody Transfer for Expressive Speech Synthesis with Tacotron
We present an extension to the Tacotron speech synthesis architecture that learns a latent embedding space of prosody, derived from a reference acoustic representation containing the desired prosody. We show that conditioning Tacotron on this learned embedding space results in synthesized audio that matches the prosody of the reference signal with fine time detail even when the reference and synthesis speakers are different. Additionally, we show that a reference prosody embedding can be used to synthesize text that is different from that of the reference utterance. We define several quantitative and subjective metrics for evaluating prosody transfer, and report results with accompanying audio samples from single-speaker and 44-speaker Tacotron models on a prosody transfer task.
💡 Research Summary
The paper introduces a novel extension to the Tacotron end‑to‑end text‑to‑speech (TTS) architecture that enables explicit control over prosody – the intonation, stress, rhythm, and style components of speech that are not specified by plain text. The authors define prosody as the residual variation in an acoustic signal after accounting for phonetic content, speaker identity, and channel effects, and they propose to learn a latent prosody space directly from reference audio without any manual annotations.
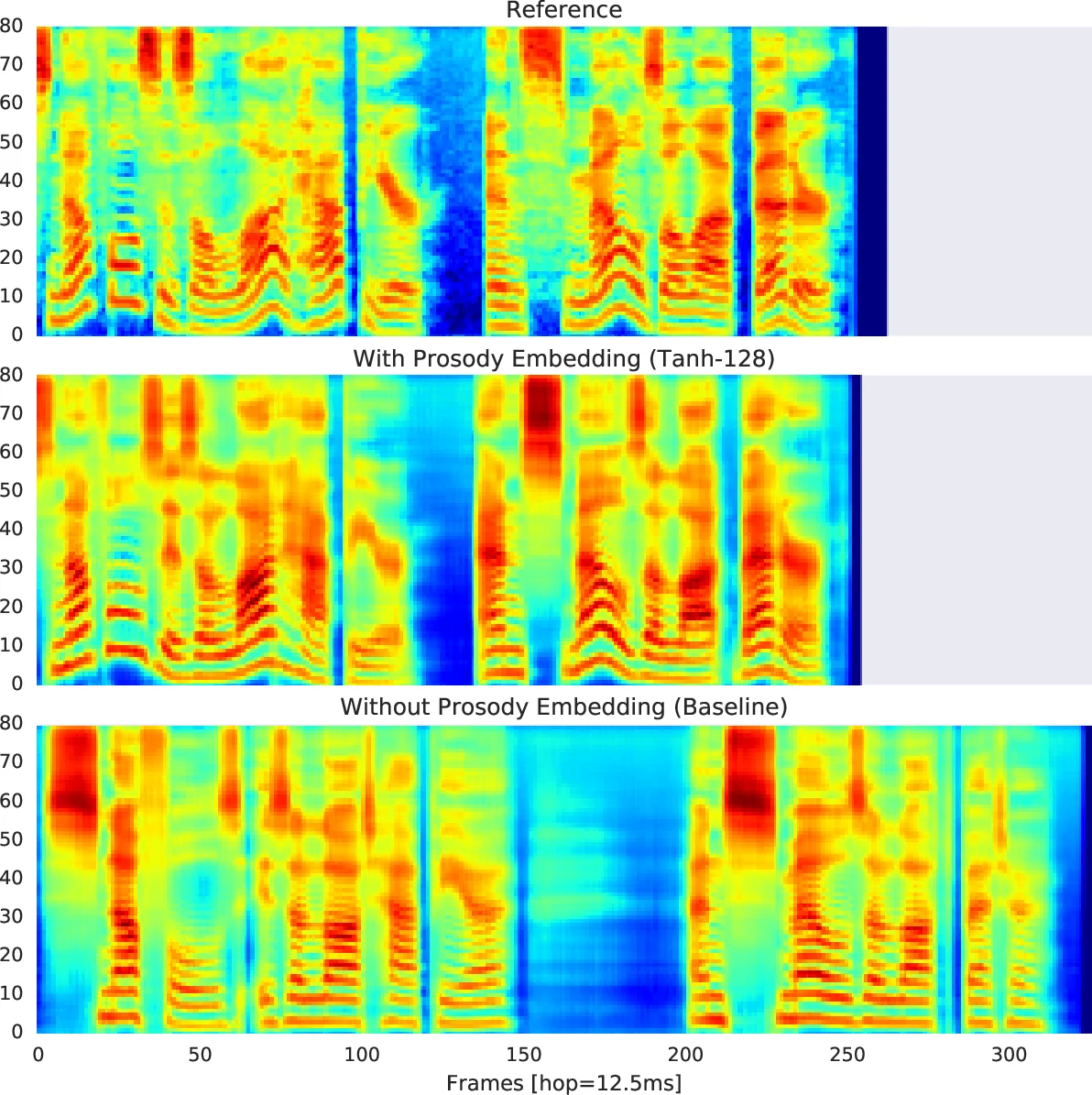
The core of the approach is a “reference encoder” that takes a reference utterance (the target audio during training) and compresses it into a fixed‑length embedding. The encoder consists of a six‑layer 2‑D convolutional stack (3×3 filters, stride 2, batch‑norm, ReLU) that reduces the mel‑spectrogram by a factor of 64 in both time and frequency, followed by a single‑layer 128‑unit GRU that pools the resulting sequence into a single vector. A fully‑connected layer with tanh activation maps this vector to a 128‑dimensional prosody embedding. This embedding is broadcast‑concatenated with the phoneme‑level transcript encoder output and a speaker embedding, forming a combined context matrix that conditions the autoregressive decoder via attention. The decoder uses GMM attention (instead of the original Bahdanau attention) to improve alignment on long utterances.
During training the reference encoder receives the ground‑truth audio, and its only supervision comes from Tacotron’s reconstruction loss (L1/L2 on mel‑spectrograms). By limiting the embedding dimensionality, the encoder is forced to capture only the information not already explained by text and speaker identity – i.e., prosodic variation. No explicit prosody labels are required, making the method applicable to any large, unannotated speech corpus.
Two datasets are used for evaluation: (1) a single‑speaker high‑quality audiobook corpus (147 h, 49 books) spoken by a single narrator, and (2) a proprietary multi‑speaker corpus (296 h) covering 44 speakers with diverse accents. Models are trained for at least 200 k steps with a batch size of 256 using Adam (initial LR = 1e‑3, decayed to 5e‑5). Baselines are identical Tacotron models without the reference encoder.
Because there is no standard metric for prosody transfer, the authors adapt several acoustic measures that correlate with prosodic attributes: Mel Cepstral Distortion (MCD), F0 root‑mean‑square error, voiced/unvoiced (V/UV) error, as well as subjective listening tests (Mean Opinion Score and a prosody similarity rating). Results show that the reference‑encoder‑augmented model reproduces the reference prosody with high fidelity: MCD improves by roughly 0.5 dB, F0 RMSE drops significantly, and listeners rate the prosody similarity above 90 % for same‑speaker cases. Crucially, when the reference audio comes from a different speaker, the model still transfers the intonation and rhythm while preserving the target speaker’s timbre, demonstrating speaker‑independent prosody transfer. In the multi‑speaker setting, the same behavior is observed across all 44 voices.
The authors also explore a variable‑length prosody embedding, where the GRU outputs at each time step are projected and fed to a second attention head. While this representation can handle very long utterances, it proved less robust to changes in text or speaker because it encodes stronger timing cues. Consequently, the paper focuses on the fixed‑length embedding for most experiments.
Key contributions include: (1) a simple yet effective reference encoder that learns a compact prosody representation without supervision, (2) demonstration that this embedding can be combined with speaker embeddings to achieve prosody transfer across speakers and texts, (3) a set of quantitative and qualitative evaluation protocols for prosody transfer, and (4) empirical evidence that the approach works both for single‑speaker high‑quality data and large multi‑speaker corpora.
The work opens several avenues for future research: predicting prosody embeddings directly from non‑acoustic context (e.g., dialogue state, sentiment labels) using sequence‑to‑sequence or transformer models; extending the embedding space to model emotion, style, or speaking rate explicitly; improving variable‑length representations for very long narratives; and integrating the method into production TTS pipelines where the compact embedding can be stored alongside text for real‑time expressive synthesis. Overall, the paper demonstrates that end‑to‑end TTS can move beyond implicit statistical prosody modeling toward controllable, expressive speech synthesis that more closely mirrors human communication.
Comments & Academic Discussion
Loading comments...
Leave a Comment