Exploring the robustness of features and enhancement on speech recognition systems in highly-reverberant real environments
This paper evaluates the robustness of a DNN-HMM-based speech recognition system in highly-reverberant real environments using the HRRE database. The performance of locally-normalized filter bank (LNFB) and Mel filter bank (MelFB) features in combina…
Authors: Jose Novoa, Juan Pablo Escudero, Jorge Wuth
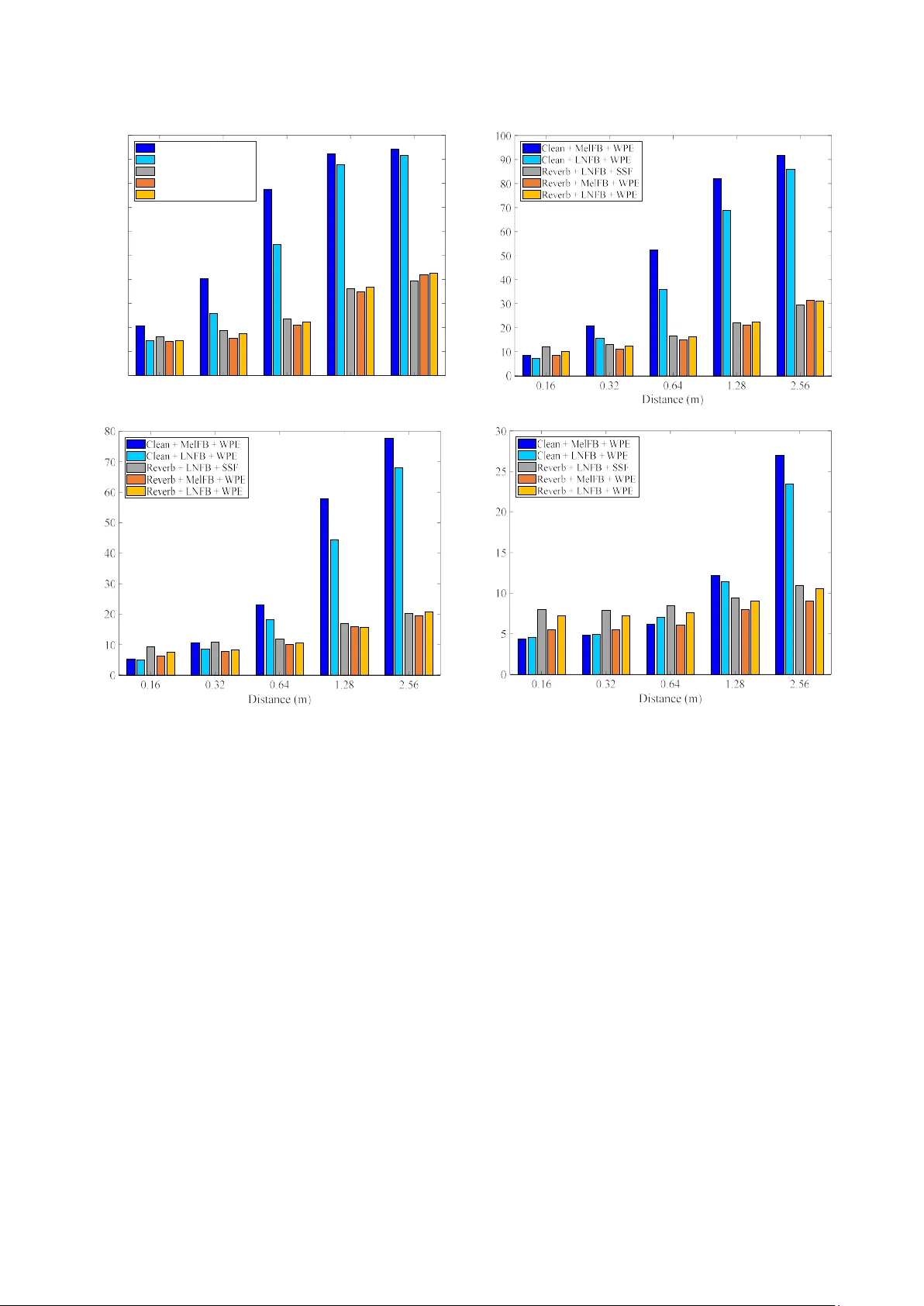
Exploring the r obustness of featu res and enhancemen t on speech rec ognition systems in highly-r everberant r eal environm ents José Novoa 1 , Juan Pablo Escudero 1 , Jorge Wuth 1 , Victor Poblete 2 , Simon King 3 , Richard Stern 4 and Néstor Becerra Yoma 1 1 Speech Processing and Transmission Laborator y, Electrica l Engineering Department, Universidad de Chile, Santiago, Chile. 2 I nstit ute of Acoustics, Universidad Austral de Chile, Valdivia , Chile. 3 Centre for Speech Technology Research, Universit y of Edi nburgh, Edinburgh, UK. 4 Department of Electrical and Computer Engineering and Language Technologies Institute, Carnegie Mellon Universit y , Pit tsburgh, USA. nbecerra@in g.uchile.cl Abstract This paper evaluates the robustness of a DNN-HMM-based speech recognition system in highly-reverberant real environments using the HRRE d atabase. The performance of locally-normalized filter bank (LNFB) and Mel filter bank (MelFB) f eatures in combination with Non-negative Matrix Factorization (NMF), Suppression o f Slowly-varying components and the Falling edge (SSF) and Weighted Prediction Error (WPE) enhancement method s are discussed and evaluated. Two traini ng conditions were considered: clean and reverberated (Reverb). With Reverb training the use o f WPE and LNFB provides WERs that are 3% and 20% low er in average than SS F and NMF, respectively. WP E and MelFB provides WERs that are 11% an d 24% lower in average th an SSF and NMF, respectively . With clean training, which represents a significant mismatch b etween testing and train ing conditions, LNFB features clearl y outperform MelFB features. The results show that different types of tr aining, parametrization, and e nhancement te chniques may work b etter for a specific combinatio n of speaker-microphone distance and reverberation time. T h is suggests that there cou ld be s o me degree of complementarity between syste ms trained with different enhancement and parametrization methods. Index Term s : speech rec ogni tion, enhancement techniqu es, reverberation, real environ ments 1. Introduction Distant automatic speech recog ni tion (ASR) represents a major challenge because the e ffects of no ise and reverberation on the speech s ignal increas e as t he distance be tween speaker and microphone increases [1]. Despite recent advances in ASR technology, successful distant speech recognition in real reverberant environments remains an important challenge [2]. Several algorith ms h ave been proposed to address the reverberation problem such as SSF , NMF and WPE. SSF is motivated by the precedence ef fect. While the precedence ef fect is clearly helpful in en abling the perceived location of a source in a reverberant environment t o remain constant, as it is dominated by the ch aracteristics of th e co mponents of th e soun d which arrive directl y fro m the soun d source while suppressing the potential impact of later-arrivi ng reflected components from other directions. It is also believed by some to improve speech intelligibility in reverberant environ ments as well [3] [4]. While hearin g researchers ha ve traditionally modeled precedence using binaur al mec h anisms [ 5], it is also possible that onset enhancement at the peripheral level ( e.g. [ 6]) may be involved instead. This co njectu re motivated the SSF algorithm, which accomplishes this type o f onset enhancement and steady - state suppression on a band-by-band basis [7]. Onset enhancement is accomplished by no nlin ear extraction of the lower envelop e and subtracting it f ro m the ongoing env elope of components of th e input after perip heral ba ndpass f iltering, followed by suppression of the steady-state frames a fter the initial arrival of a wavef ront in a parti cular frequency b and. There is a subsequent sp ectral reshaping m odule t h at minimizes differences bet ween the power spectra representing the original and pr ocessed speech. While the or iginal description o f SSF described tw o m od es of pro cess ing, we employ only the processing referred to as SSF Type II in th is work. In speech recognition applications, SSF processing is normally applied to both training and testing data. Non-negative matrix factor ization, o r N MF, is very different in nature, in that in effect it accomplishes blind deconvolution o f the re sponse to a reverberated signal in the frequency domain [8]. I t is easy to observe tha t the presence of reverberation causes a repre sentation like a spectrogram to become blu rred or smeared along the time ax is, caused by convolution of th e response representing clean speech with the sample respo nse of th e roo m acoustics, as represented in the frequency do main. Because phase infor mation is lost in the spectrogram, blind deconvolution cannot b e accom pl ished exactly, bu t a good approximation can be achieved by exploiting t h e facts that the matrix representing the sample response in th e frequency domain would be non- negative and sparse. The implem entation of NM F that is u sed [8] differs from previous work in this area in several ways. First, p rocessing is performed using magnitude spectra rather than power spectra. We have f ound that the distortion introduced by the approximation o f non-negativit y is redu ced through the use of magnitude spectral (rather than power spectral) coefficients. A second innovation is the use o f a frequency repres entation based on Gammatone filtering (whi ch mi mics th e p eripheral frequency analysis of the hu man auditory system) rather than a conventional linear or log-based frequency di stribution. The use of the Gammatone su b-bands provid es a natural perceptual weighting to th e o ptimization process which has p roved to be helpful, and at the same time it reduces the am ou nt of computation that is required. Ty picall y, th e m atrix representing the r everberation filter is estimated on a band-by-band b asis using an objective function that includes constraints based on both sparsity and non-negativity. Furth er details may be found in [8]. Weighted Prediction Error algor ithm (WPE) [9] [10] is another enhancement technique. This method is based on robust blind deconvolution using long-term linear prediction, with the motive o f reducing the effect s of late reverberation . This method receives as input a spe ech signal in the tim e d omain. A complex STF T is p erformed to co mpute th e coefficients o f the linear prediction filters iteratively . Finally, a d e-reverberated time waveform is obtained. It has been found, unsurprisingly, th at A SR systems exhibit the best performance when training and testing conditions are matched. Correspondingly, acoustic models produce more errors if test d ata are different in nature from training d ata. This degradation can o ccur, for example, if clean d ata are used for training but test data are corrupted by noise [11] . In cases of severe mismatches between training and test con ditions, allowing the DNN s to see exampl es of represe ntative variation s during training can provide improvements in performance as the DNN can potentially e xtract useful information from t hose examples t hrough the layers of nonlinear processing. In this way, the DNN is able to general ize to similar patterns in the testing data [12] enabli ng the DNN to b ecome less sensitive to changes of the in put [11]. For this reason, a typical wa y to achieve noise robustness of DNN is by using multi-style training. A DNN trained with several noise types and SNR levels can lead to improvements in ASR performance in noisy environments [12]. In addition to additive noise, reverberation is one of th e major so urces of mismatch be tween traini ng and te sting conditions, and hence also degrades recognition accuracy. An efficient way of mitigating th is mismatch is to t rain models using Multi-condition/Multi-style training data [13]. Multi-style training creates match ed training/test en vironments by adding background noise and/or simulated reverberations to the data used to train the models. This method is effective in compensating for the effects o f mismatch [ 14]. This approach has been repo rted by multiple res earch groups at the 2014 REVERB Ch allenge workshop [15], showing that performing Multi-condition training using a variety o f reverberation conditions usu ally improves the robustness o f acoustic models [16]. Similarly, generalized Multi-style training was used in [2], where the net work is provided with a characterization of reverberation in which t he test d ata was captured in order to build room-awareness into the model. An NMF-based m eth od was used to estimate a non-n egative representation o f the clean sp eech signal and the room impulse response directly from the reverbera nt speech. This technique also leads to significant improvement when ev aluated using the REVERB Challenge corpus. All of the r everberated speech databases (e.g. REVERB challenge [15], CHiME-2 Challenge [17], and ASpIRE [18]) that have b een employed so far attempt to use real environments and, in m ost cases, also include additive n oise . Surprisingly, the impact of reverberation time (RT) and speaker-microphone distance on the performance of ASR technolo gies has not yet been addressed methodo logically and independently o f the additive noise. This is partly bec ause there has not been a suitable d atabase for th is purpose. The HRRE database [ 19] is a response to th is need by providing speech data record ed in a controlled reverberant environment for several dif ferent speaker-microphone distances. By d oing so, we co ver a wide range o f p otential applications that include human-robot applications, m eeting r ooms, smart houses to clo se-talking microphone scenarios. An alterna tive app roach to address the reverberation problem is the design or use of robust features. In [20], Dam ped Oscillator Coefficients (DOC), Normalized Modulation Coefficients, Modulation of Medium Duration Speech Amplitudes, and Gammatone Filter Co efficients features were evaluated on the REVER B 2014 challenge data. In [21], Gammatone filterbank and DOC features were testing under reverberated conditions on the ASpIRE task [18]. A n ovel set of speech features for rob ust Speaker Verification (SV) and ASR called L ocall y-Normalized Cepstral Coefficients (LNCC) was propo sed in [22]. LNCC features are inspired by Seneff's Generalized Synchrony Detector (GSD) [23] which performs a lo cal normalization in the frequency domain in each audito ry channel, and hence is relatively invariant to changes in the frequency r esponse o f the transmission ch annel. LNCC fea t ures are an extremely si mple but effective way to instant aneously normalize speech features with respect to frequency. The ir effectiveness was demonstrated in a SV task in which LNCC features were more effective in compensating for sp ectral tilt [22] and more robust to additive noise [24] com pared to ordin ary MFCC coeff ici ents. The comparison of d ifferent robust f eatu res in combination with enhancement techniques in a controll ed high ly-variable real reverberant environment is not found in th e literature. In this paper the robustness of LNFB and MelFB features in combination with NMF, SSF and WPE e nhancement method s is discu ssed and evaluated regarding R T and speaker- microphone d istance with clean and reverberated train ing. The results presented here suggests that there m ight be some degree of complementarity bet ween systems w ith different training strategies, enhancement techniques and para m etr izations. 2. Experiments 2.1. Training data Speech recognition ex periments were per formed u sing the Kaldi Speech Recognition Toolkit [25]. The Clean train ing set from the Aurora-4 database was employed. This set conta ins 7138 uttera nces from 8 3 spe akers recorded with a Se nnheiser HMD-414 microphone. Additionally, a reverberant training set was developed by our group, referred to as “Reverb.” For Reverb training, s imulation s were made with the simulation program Ro om Impulse Response Generator [26], which use s the image method assuming a rectangular room [27]. In order to avoid potential artifacts in training be cause of potential standing wav e patterns that may de velop in rectangular rooms, the Reverb tr aining database consists o f 53 53 utt erances th at were passed through 5353 different randomly-generated room impulse responses (RIRs). The dimensions of the sim u lated rooms va ried from RI R to RIR with an average o f 7 .95 m length, 5. 68 m width and 4.5 m height, approximating the dimensions of the larger-sized reverberation chamber of the Acoustic Instit ute. The dimensions for eac h individual RIR were drawn from uniform distribu tions over the range o f plus or minus 20 percent of the n ominal value s stated above. A nominal RT was then selected by sampling a rand om variable over the range o f 0.45 to 1.87 s, and t he nominal average absorption and reflection coefficients that would provide the selected n ominal RT were ca lculated using the Sa bine equation [28]. Si x separate reflection coeff icients, one for each room surface, were drawn f ro m a uniform distribution between plus and minus 10 perc ent of the nominal reflection coefficient calculated from the Sabin e equation, resulting in a room with a reverberation th at was random, b ut close to the intended nominal value. The distance between sp eaker and microphone was drawn f ro m a un iform distribution between 0 .144 and 2.816 m. The speaker and microphone w ere placed in random locations at th e room, using the di stan ce that was selected for a particular trial, with t he constraints that both speaker and microphone are at least 1 m from any wall and betw een 1 m and 2 m from the floor. 2.2. Sy stem training Two types o f feature vectors were compared in this paper, the MelFB and LNFB features, in both cases considering a context window of 1 1 frames, in cluding 5 frames before and 5 frames after th e current frame. Each DNN in the DNN-HMM sys te m consists of seven hid den layers and 2048 units per layer. The DNN-HMM systems were train ed using alignments fro m an GMM-HMM recog niz er train ed with the same data. In t urn, the GMM-HMM systems were trained by using MFCC featu res, linear dis criminant analysis (LDA), and maximum lik elihood linear transforms (MLLT), accordi ng to the tri2b Kaldi Aurora-4 recipe. First, a m ono phone sy stem was trained; second, th e alignments from that sy stem were employed to generate an initial triphone system; and finally, the triphone alignments were employed to train the final triphon e system. The n umber o f un its of the o utput DNN layer was equ al to the number of Gaussians in th e corresponding GMM-HMM system. For decoding we used the standard 5K lexicon and trigram language model. 3. Results and disc ussion We obtained results for a total of 330 testing utterances f or each one of th e 20 reverberation conditions (four RTs and five microphone-speaker distances) available in the HRRE database [19]: RTs equal to 0.47s, 0.84s, 1.27s, and 1.77s; and, microphone-speaker distances equal to 0.16m, 0.32m, 0. 64m, 1.28m, and 2.56m. Two types of feature extraction p rocedures (MelFB and LNFB), two sets of training d ata (Clean and Reverb) and four types of environmental compensation (none, NMF, SSF, and WPE) were combined. Table 1 describes the WERs obtained for each speaker - microphone distance averaged a cross the four RTs tha t were available in our reverberation cha mber. The lo west WER for each column is highlighted in bold in Table 1. As can be seen in Table 1, the best results are observed for Reverb trainin g with MelFB combined with WPE in most cases. The best MelFB features perform better than the best LNFB features (in conjunction with Reverb training) averaged over all RTs. Compared with the baseline system with MelFB and Clean training condition, th e optimal reductions in Table 1 are higher than 70% with all the speaker-microp hone distances. 3.1. Training procedure According to what has been mentioned abo u t m ulti -style training, the best r esults are a chieved with Reverb trainin g in most test con ditions. However, as can be seen in Fig. 1, Clean training in combination w ith W PE achieves better performance than Reverb training in four o f the tw ent y condit ions: RT eq ual to 0 .84s and 1 .27s at 2.56 m using LNFB ; and , with RT equal 0.47s in the shortest distances ( i.e. 0.16 and 0 .32 m ) using MelFB. 3.2. Effect of e nhancement techniques As discussed abo ve, th e NMF, SSF and WPE techniques were designed to r educe th e mismatch between training and testing conditions. As seen in Table 1, the app lication of this techniques is always helpful n o matter which trainin g da ta are used. Addition ally, we observe t hat SSF always outperforms NMF for the conditions that we e xamined. On the o ther hand, WPE surpasses SSF in all distances only with Reverb trainin g. The use of WPE in combination with MelFB and Reverb training, and averaging across all RTs, produ ces the best system for speaker-microphone distances greater than 0.32 m. F or the speaker-microphone distance of 0.16 m, th e best result is obtained with WPE with Clean training and using th e LNFB features. The use of W P E in combination w ith MelFB and LNFB pr ovides the best results for almost all test conditions, except for the greatest RTs at the longest distances, i. e. RT equal to 1.27s and 1.77s at a speaker-microphone distance equal to 2. 56 m, where SSF combined with LNFB and Reverb training leads to greater accuracies (see Fig. 1) . 3.3. Perfor mance of MelFB versus LNFB f eatures Figure 1 c ompare directl y the best systems obtained using the MelFB and LNFB features. M elFB achieve th e best WER in several case s. Nevertheless, as c an be seen in Fig. 1, LNFB exhibits better accuracy in some critic al RTs and distances, i.e. with RT equal to 1.27s and 1.77s at a dista nce of 2. 56 m. On the other h and, LNFB worked b etter in t he s ho rtest distance, i.e. 0.16m, for RT equal to 0.84s and 1.27s. 3.4. Complementarity betw een ASR systems Despite the fact th at on average the u se of MelFB in combination with WPE and Reverb trainin g provided the Table 1: WERs averaged across all RTs values using MelFB and LNFB for different training conditions and pre-processing techniques . Training Feature Speaker - microphone distance [m] 0.16 0.32 0.64 1.28 2.56 Baseline Clean MelFB 34.1 5 5.5 7 0.2 78.9 84.7 LNFB 18.7 3 2.6 5 3.0 69.1 79.5 Reverb MelFB 13.3 16.3 21.7 31 .1 36.4 LNFB 14.0 17.7 22.2 30 .1 34.8 NMF Clean MelFB 16.4 2 5.5 3 8.9 56.3 67.8 LNFB 14.3 2 0.8 3 0.6 49.6 62.5 Reverb MelFB 11.9 1 4.3 1 7.6 26.2 31.9 LNFB 12.6 1 5.1 1 7.9 26.0 32.0 SSF Clean MelFB 14.9 2 2.0 3 4.5 53.7 65.7 LNFB 12.3 1 8.0 2 7.2 46.2 59.8 Reverb MelFB 11.0 12.6 15.0 21.9 26.2 LNFB 11.5 12.6 15.2 21.2 25.0 WPE Clean MelFB 9.8 19.1 3 9.9 61.1 72.8 LNFB 7.9 13.9 2 9.0 53.2 67.3 Reverb MelFB 8.7 10.0 13 .1 20.0 25.5 LNFB 9.8 11.4 1 4.2 21.0 26.3 lowest WER, d ifferent combinations o f features, training data and enhancement techn iques could address more effectively some testing conditions. The res ults show n in the Fig. 1 sugg est that th ere is some degree of co mplementarit y between s ystems trained with different data, enhancement, an d parametrization methods. Although we can always select the best system, we can also combine the b est engines to obtain a n ew system that could be even more accurate in different test condit ions. 4. Conclusions Two training conditions were e valuated: Clean and Reverb. The comparisons also inclu ded the NMF, SSF, and WPE environmental co mpensation algorithms. The resu lts presente d here show that the lowes t average WER is achieved using Reverb training and MelFB features combined w ith WPE. With Clean trainin g, i.e. significant mismatch between testing- training conditions, LNFB features clearly outp erform MelFB parameters. Generally, the use of the NMF, SSF and WPE compensation tech niques im pro ves WER for LNFB and MelFB features, for both t raining styles. Specifically, with Reverb training the use of WPE and L NFB provides W ERs that are 3% and 20% lower in average than SSF and NMF, respectively. WPE and MelFB pr ovides WERs that are 11% and 24% lower in average than SSF and NMF, respectively. It is worth high lighting that for so me test conditions some systems led to higher accuracies than MelFB/ WP. These res ults strongly suggest that there is com p lementarity among the different engines tested h ere, so finding the best way to combine them is proposed for future research. 5. Acknowled gements The research reported here was funded by Grants Co n icyt- Fondecyt 1151306 and ONRG N°62909-17-1-2002. José Novoa was su pported by Grant CONICYT-PCHA/Doctorado Nacional/2014-21140711. 6. References [1] J. Li, L. Deng, R. Haeb- Umbach and Y. Gong, Robust Automatic Speech Recognition: A Bridge to P ractical Applications, Pa ris, France: Academic Press, 2015. [2] R. Giri, M. L. Seltzer, J. Droppo and D. Yu, “Improving speech recognition in reverberation using a room- aware deep neural netw ork and multi-t ask learning,” in Proc. of ICASSP , Brisbane, QLD, Australia, 2015. a) b) c) d) Figure 1: Results for the best ASR systems with a) RT=1.77 s, b) RT=1.27 s, c) RT=0.84 s and d) RT=0.47s . 0.16 0.32 0.64 1.2 8 2 .56 Distance (m) 0 10 20 30 40 50 60 70 80 90 100 W E R ( % ) Clean + Mel FB + WPE Clean + L NFB + WPE Reverb + LNFB + SSF Reverb + MelFB + WPE Reverb + LNF B + WPE W E R ( % ) W E R ( % ) W E R ( % ) [3] J. S. Bra dley, H. Sato and M. Picard, “On t he importance of early r eflections for speech in r ooms,” The Jo urnal o f the Acoustical Society of America, vol. 113, no. 6, pp . 3233 - 3244, 2003. [4] H. Sato, J. S. Bra dley and M. Morimoto, “Using listening difficulty ratin gs of co nditions for speech com munication in rooms,” The Journal of the Acoustical Society of America, vol. 117, no. 3 , pp. 1157 - 1167, 2005. [5] W. LIndemann, “Extension of a binaural cross- correlation model by con tralateral inhibition. I. Simulation of lateralization for stati onary signals,” The Journal of the Acoustical So ciety of America, vol. 8 0, no. 6, pp. 1608 - 16 22, December 1986. [6] K. D. Martin, “Echo suppressio n in a co mputational model of th e precedence eff ec t,” in Proc. of WASSP , New Paltz, NY, USA, 1997. [7] C. Kim and R. M. Stern, “Nonlinear enhancement of onset for robust speech recognition,” in P ro c. o f INTERSPEECH , Makuhari, Chiba, Japan, 2010. [8] K. Kumar, R. Singh, B. Raj and R. Stern, “Gammatone sub-band magnitude- domain dereverberation for ASR,” in Proc. of ICASSP , Prague, Czech Republic, 2011. [9] T. Yoshio ka, T. Nakatani, M. Miyoshi an d H. Okuno, “Blind separation and dereverberati on of speech mixtures by joint optimization,” IEEE Transactions on Audio, Speech, and L anguage Processing, v o l. 19, no. 1, pp. 69- 84, 2011. [10] T. Yosh ika, X. Chen and M. Gales, “Impact of sin gle- microphone dereverberation on dnn- based meeting transcription sy stems,” in Proc. of ICASSP , Florence, Italy, 2014. [11] S. Yin, C. L iu, Z. Zhang, Y. Lin, D. Wang, J . Tejedor, T. F. Zheng and Y. Li, “Noisy training for deep neural networks in speech recognit ion,” EURASIP Journal on Audio, Speech, and Music Processing, vol. 2015, no. 1, pp. 1 - 14, 2015. [12] C. Weng, D. Yu, M . L. Seltzer an d J. Droppo, “Single- channel m ixed sp eech recognition using d eep neural networks,” in Proc. of ICASSP , Florence, Italy, 2014. [13] M. J. A la m, V. G upta , P . Kenny and P. D umouchel, “Use of multiple front-ends and i- vector based speaker adaptation for robust s peech recognition,” i n Proc. of REVERB Challeng e , Florence, Italy , 2 014. [14] R. J. Weiss and D. P. Ellis, “Monaural speech separation using source-adapted models,” in Proc. of WASPAA , New Paltz, NY, USA, 2007. [15] K. Kinoshita , M. Delcroix, T. Yoshio ka, T. Nakatani, A. Sehr, W. Kellermann and R. Maas, “The reverb challenge: Acommon ev alu ation framework f or dereverbe ration and recognition o f reverberant speech,” in Proc. of WASPAA , New Paltz, NY, USA, 2013. [16] K. Kinoshit a, M. Delcroix, S. Gannot, E. A. Habets, R. Haeb- Umbach, W . Ke ll ermann, V. L eutn ant, R. Maas, T. Nakatani and B. Raj, “A summary of th e REVERB challenge: state-of-the- art and remaining challenges in reverberant sp eech processing research,” EURASIP Journal on Advances in Signal Processing, no. 1, pp. 1- 16, 2016. [17] E. Vincent, J. Barker, S. Watanabe, J. Le Rou x, F. Nesta and M. Matassoni, “The second ‘ CHiME’speech separation and recognition c hallenge: Datasets, tasks and baselines,” in Proc. of ICA S SP , Vancouver, BC, C an ada, 2013. [18] M. Harper, “The auto matic speech recogitio n in reverberant environments (A SpI RE) challenge,” i n Proc. of AS RU , Scottsdale, AZ, USA, 2015. [19] J. P. Escudero, V. P oblete, J. Novoa, J. Wuth, J. Fredes, R. Mah u, R. Stern and N. Bece rra Yoma, “Highly- Reverberant Real Environment database: HRRE,” ArXiv e - prints 1801.09651, 2018. [20] V. Mitra, W. Wang and H. Franco, “Deep convolutional nets and robu st features for reverberation - robust speech recognition,” in Pro c. of SLT , South Lake Tahoe, NV , USA, 2014. [21] V. Mitra, H. Franco, R. Stern, J. Van Hout, L. Ferrer, M. Graciarena, W. Wang, D. V ergyri, A. Alwan and J. Hansen, “Robust features in Dee p Learning based Speech Recognition,” in New Era for Robust Sp eech Recognition: Exploiting Deep Learning , Sp ringer, 2017 , pp. 187 - 217. [22] V. Poblete, F . Espic, S. Kin g, R. M. Stern, F. Huen upán, J. Fr edes and N. B. Yoma, “A P erceptually- Motivated Low- Complexity Instantaneous Linear Channel Normalization Technique Appl ied to Speaker Verification,” Co mputer Speech & Languag e, vol. 31, no. 1, pp. 1 - 27, 2015. [23] S. Seneff, “A join t synchrony/mean- rate model of auditory speech processing,” J. Phonetics, vol. 16, pp. 55 - 76, 1988. [24] J. Fredes, J. Novoa, S. King, R. M. Stern and N. Becerra Yoma, “Rob ustness to Additive Noise of Locally- Normalized Cepstral Coefficients in Sp eaker Verification,” in Proc. o f INTERSPEECH , Dresden, Germany, 2015. [25] D. Po vey, A. Ghoshal, G. Boulianne, N. Goel, M. Hannemann, Y. Qian, P. Schw arz and G. Stemmer, “The Kaldi Speech Recognition Toolkit,” in Proc. of ASRU , Hawaii, USA, 2011. [26] E. Habets, “Room Impulse Response Gene rator,” 2010. [27] J. B. Allen and D. A . Berkley, “I mage m ethod f o r efficiently simulating small-room a cousti cs,” The Journal of the Acoustical So ciety of America, vol. 6 5, no. 4, pp. 943 - 950, 1979. [28] H. Kuttruff, Room Acoustics, CRC Press, 2009.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment