Dynamic Natural Language Processing with Recurrence Quantification Analysis
Writing and reading are dynamic processes. As an author composes a text, a sequence of words is produced. This sequence is one that, the author hopes, causes a revisitation of certain thoughts and ideas in others. These processes of composition and revisitation by readers are ordered in time. This means that text itself can be investigated under the lens of dynamical systems. A common technique for analyzing the behavior of dynamical systems, known as recurrence quantification analysis (RQA), can be used as a method for analyzing sequential structure of text. RQA treats text as a sequential measurement, much like a time series, and can thus be seen as a kind of dynamic natural language processing (NLP). The extension has several benefits. Because it is part of a suite of time series analysis tools, many measures can be extracted in one common framework. Secondly, the measures have a close relationship with some commonly used measures from natural language processing. Finally, using recurrence analysis offers an opportunity expand analysis of text by developing theoretical descriptions derived from complex dynamic systems. We showcase an example analysis on 8,000 texts from the Gutenberg Project, compare it to well-known NLP approaches, and describe an R package (crqanlp) that can be used in conjunction with R library crqa.
💡 Research Summary
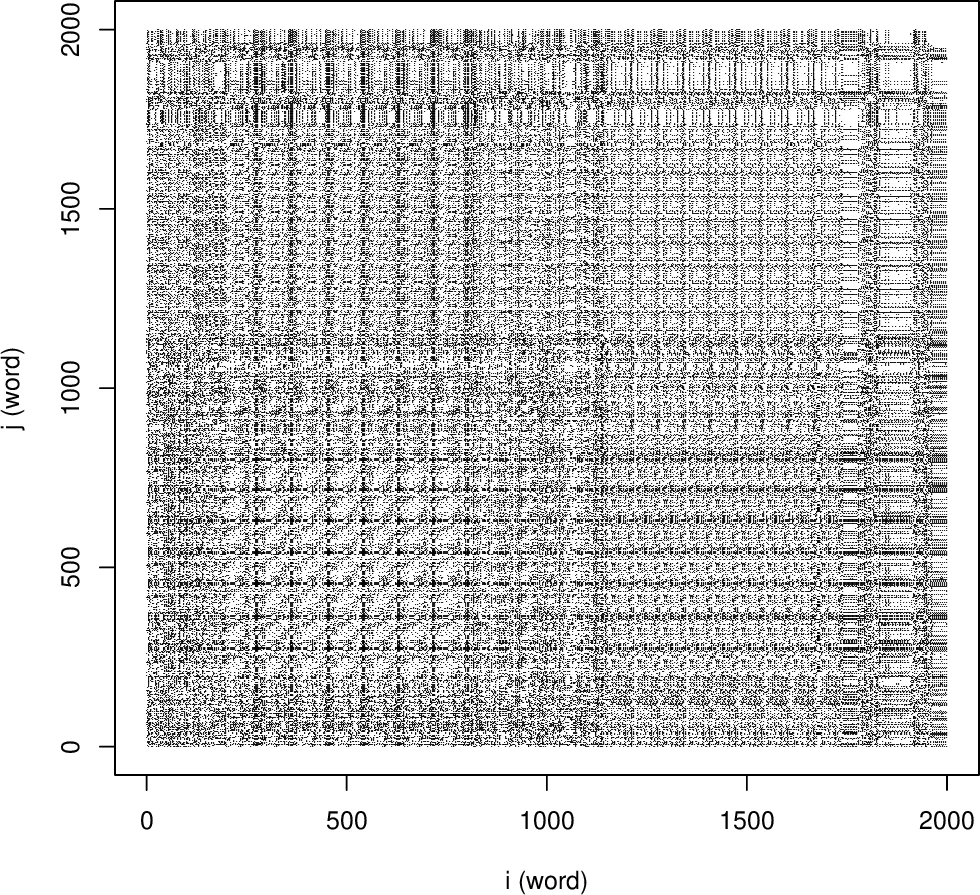
The paper “Dynamic Natural Language Processing with Recurrence Quantification Analysis” proposes a novel framework that treats textual data as a dynamical system and applies Recurrence Quantification Analysis (RQA) to capture its temporal structure. The authors argue that writing and reading are inherently time‑ordered processes; therefore, a text can be modeled as a sequential measurement analogous to a time series. RQA, originally developed for physical and biological time‑series, quantifies the recurrence of states (here, words) by first constructing a Recurrence Plot (RP) – a two‑dimensional matrix where each point (i, j) indicates that the word at position i equals the word at position j. Visual patterns in the RP (diagonal lines, clusters) reveal repeated motifs, thematic shifts, and long‑range dependencies.
From the RP, a suite of quantitative descriptors is extracted: Recurrence Rate (RR) – the proportion of recurrent points, Determinism (DET) – the fraction of recurrent points forming diagonal lines, average diagonal line length (L), entropy of line‑length distribution (ENTR), maximum line length, and others. The authors demonstrate that these RQA metrics map onto classic NLP concepts: RR corresponds to unigram frequency, DET and L reflect higher‑order n‑gram conditional probabilities, and ENTropy captures text complexity beyond simple frequency counts. Thus, RQA provides a bridge between dynamical‑systems analysis and traditional statistical language models.
To validate the approach, the authors processed 8,000 texts from Project Gutenberg spanning multiple genres (novels, poetry, essays, scientific articles). For each text they computed ~20 RQA features and used them to train classifiers (Random Forest, SVM, Logistic Regression). They compared performance against baseline NLP representations: TF‑IDF n‑gram vectors, Latent Dirichlet Allocation (LDA) topic distributions, and contextual embeddings from BERT. Results show that RQA features alone achieve high genre‑classification accuracy (≈85 %), and when combined with conventional features, they further improve performance, indicating complementary information. Notably, RQA remains robust for short texts where n‑gram sparsity is problematic, and it captures long‑range repetition patterns that are invisible to fixed‑window models.
The methodological contribution is accompanied by an open‑source R package named crqanlp. This package integrates text preprocessing, RP construction, and computation of the full RQA metric set, building on the existing crqa library. It supports custom distance functions, adjustable embedding windows, and multi‑cohort analyses, enabling researchers to apply the framework to diverse corpora and languages.
Overall, the paper makes three key contributions: (1) introducing a dynamic systems perspective to NLP, (2) formally linking RQA metrics with established linguistic statistics, and (3) providing empirical evidence and tooling that demonstrate the practical utility of RQA for tasks such as genre classification, author identification, and potentially sentiment or narrative analysis. By quantifying long‑range dependencies and recurrence structures, RQA offers a complementary lens to deep‑learning models, which often focus on local context. Future work could explore integrating RQA-derived features into neural architectures, applying the method to spoken‑language transcripts, or extending it to multimodal data where temporal recurrence is also salient.
Comments & Academic Discussion
Loading comments...
Leave a Comment