Machine learning-assisted virtual patching of web applications
Web applications are permanently being exposed to attacks that exploit their vulnerabilities. In this work we investigate the application of machine learning techniques to leverage Web Application Firewall (WAF), a technology that is used to detect and prevent attacks. We propose a combined approach of machine learning models, based on one-class classification and n-gram analysis, to enhance the detection and accuracy capabilities of MODSECURITY, an open source and widely used WAF. The results are promising and outperform MODSECURITY when configured with the OWASP Core Rule Set, the baseline configuration setting of a widely deployed, rule-based WAF technology. The proposed solution, combining both approaches, allow us to deploy a WAF when no training data for the application is available (using one-class classification), and an improved one using n-grams when training data is available.
💡 Research Summary
The paper addresses the persistent problem of web applications being exposed to attacks that exploit software vulnerabilities. While ModSecurity, an open‑source Web Application Firewall (WAF), is widely deployed and relies on the OWASP Core Rule Set (CRS) for detection, its rule‑based approach suffers from high false‑positive rates (up to 40 %) and requires labor‑intensive tuning for each protected application. To overcome these limitations, the authors propose a hybrid solution that augments ModSecurity with two complementary machine‑learning techniques: a one‑class classifier and a high‑order n‑gram language model.
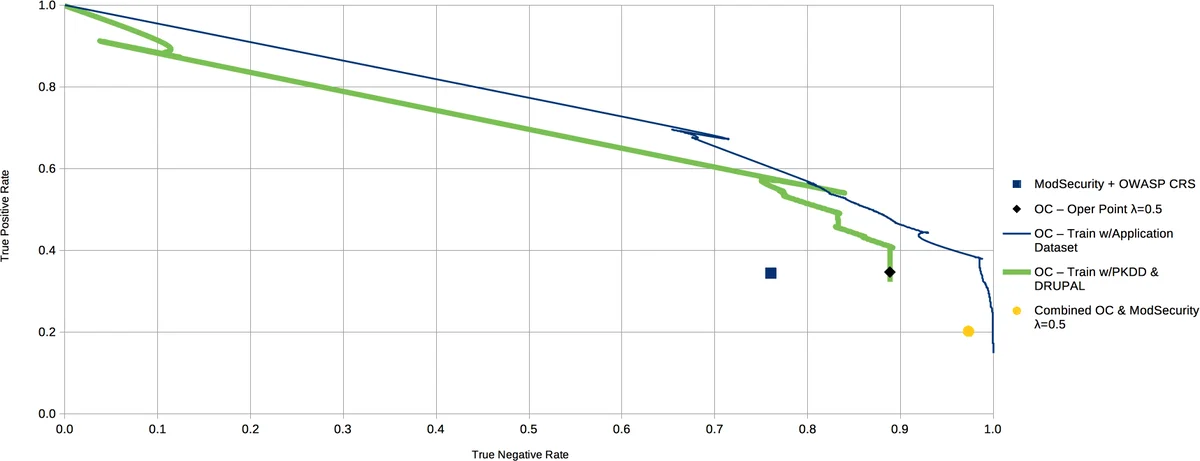
The one‑class approach is designed for scenarios where no labeled attack data are available for the target application. It learns a statistical model of normal HTTP traffic only, treating any deviation as a potential attack. This model is combined with ModSecurity’s CRS in a decision‑fusion scheme: when both classifiers agree, the shared verdict is used; when they disagree, the one‑class classifier’s output is given priority because CRS is known to generate many false positives. The authors demonstrate that this integration can be trained on generic traffic collected from other web applications and then deployed across multiple sites without per‑application customization.
The n‑gram approach targets environments where a sufficient corpus of legitimate requests can be gathered. By extracting token sequences (3‑grams, 4‑grams, etc.) from each request field, the system builds a probabilistic language model that captures the typical “signature” of each parameter. Incoming requests are transformed into the same feature space, and a distance metric (e.g., Kullback‑Leibler divergence) measures how far the request deviates from the learned distribution. Requests exceeding a predefined threshold are flagged as anomalous. Because the model reflects the actual usage patterns of the protected application, it can detect both known attack signatures and zero‑day exploits with high precision.
The authors define two operational scenarios. Scenario I (data‑scarce) relies solely on the one‑class classifier, answering the questions: (1) Can a detection system be built from training data collected from other applications? and (2) Can machine‑learning reduce ModSecurity’s false‑positive rate? Experiments show that the hybrid one‑class/CRS system reduces false positives by more than 30 % while maintaining comparable detection rates. Scenario II (data‑rich) employs the n‑gram model in addition to the one‑class component. In this setting, the hybrid system achieves an overall accuracy improvement of over 10 % relative to ModSecurity alone, with detection rates for common attacks such as XSS and SQL injection exceeding 95 %.
Methodologically, the paper outlines a five‑step pipeline: (1) collection of a representative set of normal HTTP requests; (2) preprocessing (URL decoding, optional parsing of headers and bodies); (3) feature extraction using either a fixed security‑expert token list or automatically derived n‑grams; (4) model computation, which estimates a probability distribution or hyper‑volume encompassing normal request vectors; and (5) online classification of each incoming request by computing a distance score to the model. The authors discuss design choices such as token selection criteria, the trade‑off between model granularity and computational overhead, and the handling of high‑entropy fields (e.g., passwords) where language signatures are not informative.
Limitations are acknowledged. The one‑class model may misclassify legitimate but rare request patterns as attacks if the training set does not capture sufficient variability. The n‑gram model incurs higher memory and CPU costs as the gram order and vocabulary size increase, potentially limiting scalability in high‑throughput environments. Continuous model retraining is required to adapt to evolving application behavior, which introduces operational overhead.
In conclusion, the study demonstrates that augmenting a rule‑based WAF with lightweight statistical learning techniques can substantially improve virtual patching—providing rapid, automated protection without source‑code changes. The hybrid framework offers a pragmatic path: deploy the one‑class classifier for quick protection of public or frequently changing sites, and switch to the richer n‑gram model when a stable, labeled traffic baseline is available. Future work is suggested in exploring deep‑learning sequence models, reinforcement‑learning for adaptive rule generation, and broader validation across diverse web frameworks and deployment scales.
Comments & Academic Discussion
Loading comments...
Leave a Comment