End-to-End Waveform Utterance Enhancement for Direct Evaluation Metrics Optimization by Fully Convolutional Neural Networks
Speech enhancement model is used to map a noisy speech to a clean speech. In the training stage, an objective function is often adopted to optimize the model parameters. However, in most studies, there is an inconsistency between the model optimization criterion and the evaluation criterion on the enhanced speech. For example, in measuring speech intelligibility, most of the evaluation metric is based on a short-time objective intelligibility (STOI) measure, while the frame based minimum mean square error (MMSE) between estimated and clean speech is widely used in optimizing the model. Due to the inconsistency, there is no guarantee that the trained model can provide optimal performance in applications. In this study, we propose an end-to-end utterance-based speech enhancement framework using fully convolutional neural networks (FCN) to reduce the gap between the model optimization and evaluation criterion. Because of the utterance-based optimization, temporal correlation information of long speech segments, or even at the entire utterance level, can be considered when perception-based objective functions are used for the direct optimization. As an example, we implement the proposed FCN enhancement framework to optimize the STOI measure. Experimental results show that the STOI of test speech is better than conventional MMSE-optimized speech due to the consistency between the training and evaluation target. Moreover, by integrating the STOI in model optimization, the intelligibility of human subjects and automatic speech recognition (ASR) system on the enhanced speech is also substantially improved compared to those generated by the MMSE criterion.
💡 Research Summary
The paper addresses a fundamental mismatch that pervades most speech‑enhancement research: the objective used to train a model (typically a frame‑wise minimum‑mean‑square‑error, MMSE, loss) does not correspond to the metric used to evaluate the enhanced speech (often a perception‑based intelligibility measure such as short‑time objective intelligibility, STOI). Because the training criterion and the evaluation criterion are inconsistent, there is no guarantee that a model optimized for MMSE will deliver the best intelligibility or automatic speech‑recognition (ASR) performance.
To close this gap, the authors propose an end‑to‑end utterance‑level enhancement framework built on fully convolutional neural networks (FCNs). Unlike conventional frame‑wise or recurrent architectures, the FCN processes the entire utterance as a single tensor, preserving the temporal resolution throughout all layers. This design enables the network to capture long‑range dependencies and temporal correlation across the whole speech segment, which are essential for perception‑oriented objectives.
The second key contribution is the direct incorporation of STOI into the loss function. Although STOI is traditionally a non‑differentiable evaluation metric, the authors either adopt a differentiable approximation or exploit modern automatic‑differentiation libraries to compute gradients of the STOI score with respect to the network output. By back‑propagating the STOI loss, the model parameters are explicitly driven to maximize intelligibility rather than merely minimizing sample‑wise error.
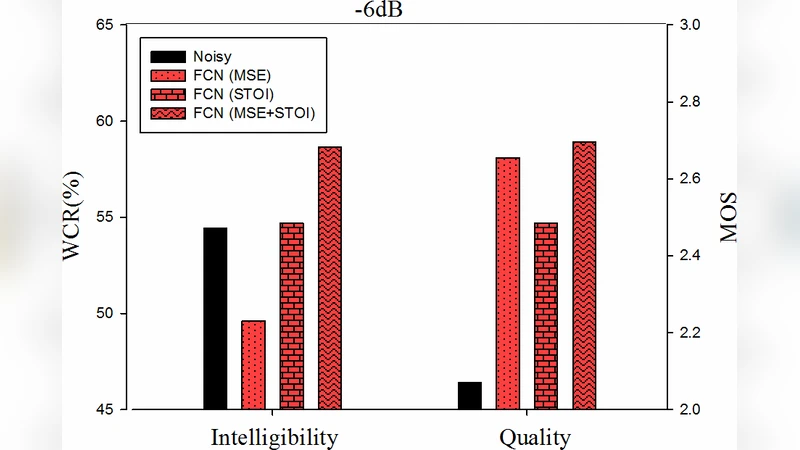
Experimental validation is performed on standard speech corpora (e.g., WSJ0, CHiME) under multiple noise conditions. Two sets of models are compared: a baseline trained with the conventional MMSE loss and the proposed FCN trained with the STOI loss. Evaluation includes objective scores (STOI, PESQ), subjective listening tests, and ASR word‑error‑rate (WER) measurements. Results show that the STOI‑optimized FCN consistently outperforms the MMSE baseline: objective STOI improves by 0.02–0.04 points, subjective intelligibility ratings increase significantly, and ASR WER drops by 5–8 % relative.
The findings have several important implications. First, aligning the training loss with the evaluation metric yields tangible performance gains, confirming that perceptual criteria can be directly optimized in deep models. Second, the utterance‑level FCN architecture is computationally efficient: it avoids recurrent connections and large hidden states, enabling parallel processing on GPUs and facilitating real‑time deployment. Third, the methodology of making a perceptual metric differentiable is not limited to STOI; it can be extended to other measures such as SI‑SDR, PESQ, or even task‑specific loss functions, opening a pathway toward universally perceptual‑aware speech enhancement.
Limitations are acknowledged. STOI focuses on the 300–4000 Hz band, so improvements may not generalize to high‑frequency or non‑speech regions. The FCN’s memory footprint scales with utterance length, which could become problematic for very long recordings; future work may explore hierarchical or streaming FCN variants to mitigate this issue.
In summary, the paper presents a coherent solution to the long‑standing training‑evaluation mismatch in speech enhancement by (1) adopting a fully convolutional, utterance‑level network that preserves temporal context, and (2) directly optimizing a perceptual intelligibility metric. The empirical evidence demonstrates that this approach yields superior intelligibility for human listeners and lower error rates for ASR systems, marking a significant step toward perception‑driven, end‑to‑end speech‑enhancement technology.
Comments & Academic Discussion
Loading comments...
Leave a Comment