Deep CNN based feature extractor for text-prompted speaker recognition
Deep learning is still not a very common tool in speaker verification field. We study deep convolutional neural network performance in the text-prompted speaker verification task. The prompted passphrase is segmented into word states - i.e. digits -to test each digit utterance separately. We train a single high-level feature extractor for all states and use cosine similarity metric for scoring. The key feature of our network is the Max-Feature-Map activation function, which acts as an embedded feature selector. By using multitask learning scheme to train the high-level feature extractor we were able to surpass the classic baseline systems in terms of quality and achieved impressive results for such a novice approach, getting 2.85% EER on the RSR2015 evaluation set. Fusion of the proposed and the baseline systems improves this result.
💡 Research Summary
This paper investigates the use of deep convolutional neural networks (CNNs) for text‑prompted speaker verification, a scenario where users utter a randomly generated passphrase (typically a sequence of digits) rather than a fixed phrase. While i‑vector/TV‑UBM, GMM‑SVM, and State‑PLDA have been the dominant approaches for this task, deep learning has largely been limited to phonetic‑aware front‑ends for text‑independent verification. The authors propose a novel end‑to‑end solution that directly learns speaker‑discriminative embeddings from log‑mel power spectra using a Light‑CNN architecture equipped with the Max‑Feature‑Map (MFM) activation function. MFM acts as an embedded feature selector by taking the maximum of paired feature maps, providing ReLU‑like non‑linearity while reducing dimensionality and suppressing noisy channels.
The system first segments each passphrase into individual digit states using an HMM‑Viterbi alignment, then extracts 64‑band log‑mel spectra for each digit, normalizing the time dimension to a fixed 96‑frame length (cropping or zero‑padding as needed). The CNN consists of several convolution‑MFM blocks followed by two fully‑connected layers, ending with a 1024‑dimensional embedding layer used only during training. Two training regimes are explored: (1) single‑task speaker classification and (2) multitask classification of speaker‑digit pairs (N speakers × 10 digits). The multitask setup dramatically improves performance because it forces the network to model both speaker identity and lexical content simultaneously.
During evaluation, the final soft‑max layer is removed, and embeddings for enrollment and test digits are compared with cosine similarity. Scores for all digits in a passphrase are averaged to produce the final verification score; no additional backend such as PLDA or score normalization is required.
Experiments are conducted on Part 3 of the RSR2015 database (English digits) and a newly collected STC‑Russian‑digits corpus (Russian digits). Baseline systems include GMM‑SVM, State‑GMM‑SVM, and State‑PLDA, with the best baseline (State‑GMM‑SVM) achieving 3.11 % equal error rate (EER) on pooled male‑female data. The single‑task CNN yields a relatively high 7.83 % EER, confirming that speaker‑only training is insufficient for this task. In contrast, the multitask CNN (StCNN‑MT) reaches 5.12 % EER when trained solely on RSR2015. Adding the English WSJ “WF” data and the Russian digit corpus to the training pool further reduces EER to 2.85 % on the RSR2015 evaluation set, surpassing all baselines.
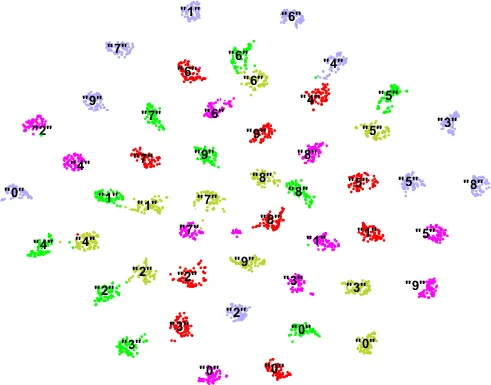
A score‑level fusion using the BOSARIS toolkit combines the proposed CNN embeddings with each baseline system. The fused system achieves an overall EER of 1.43 % (a 54 % relative reduction compared with the best single baseline) and a minimum detection cost function (minDCF) of 6.58 %. t‑SNE visualizations show that embeddings from the same speaker cluster together across different digits, confirming that the network captures speaker characteristics while preserving lexical information.
Key insights from the study include: (i) MFM provides an efficient, parameter‑light way to perform embedded feature selection, improving robustness on limited data; (ii) multitask learning of speaker and digit labels yields embeddings that are simultaneously speaker‑discriminative and passphrase‑aware, eliminating the need for separate text verification modules; (iii) incorporating out‑of‑domain data from other languages enhances the model’s ability to learn language‑independent speaker variability, suggesting a path toward multilingual verification systems; and (iv) simple cosine similarity scoring suffices, streamlining deployment.
In conclusion, the authors demonstrate that a deep CNN with MFM activation, trained in a multitask fashion, can outperform traditional statistical methods for text‑prompted speaker verification and, when fused with those methods, achieve state‑of‑the‑art performance. Future work may explore larger multilingual corpora, model compression for on‑device use, and end‑to‑end training that jointly optimizes segmentation, embedding extraction, and scoring.
Comments & Academic Discussion
Loading comments...
Leave a Comment