Effective Implementation of GPU-based Revised Simplex algorithm applying new memory management and cycle avoidance strategies
Graphics Processing Units (GPUs) with high computational capabilities used as modern parallel platforms to deal with complex computational problems. We use this platform to solve large-scale linear programing problems by revised simplex algorithm. To implement this algorithm, we propose some new memory management strategies. In addition, to avoid cycling because of degeneracy conditions, we use a tabu rule for entering variable selection in the revised simplex algorithm. To evaluate this algorithm, we consider two sets of benchmark problems and compare the speedup factors for these problems. The comparisons demonstrate that the proposed method is highly effective and solve the problems with the maximum speedup factors 165.2 and 65.46 with respect to the sequential version and Matlab Linprog solver respectively.
💡 Research Summary
The paper presents a GPU‑accelerated implementation of the Revised Simplex algorithm aimed at solving large‑scale linear programming (LP) problems. Recognizing that the traditional CPU‑based Simplex suffers from limited parallelism due to the need to maintain and update a basis inverse, the authors redesign the algorithm to exploit the massive data‑parallel capabilities of modern graphics processors. Their contribution is twofold: (1) a novel memory‑management scheme that aligns the algorithm’s data structures with the GPU memory hierarchy, and (2) a tabu‑based entering‑variable rule that eliminates cycling caused by degeneracy while preserving high parallel efficiency.
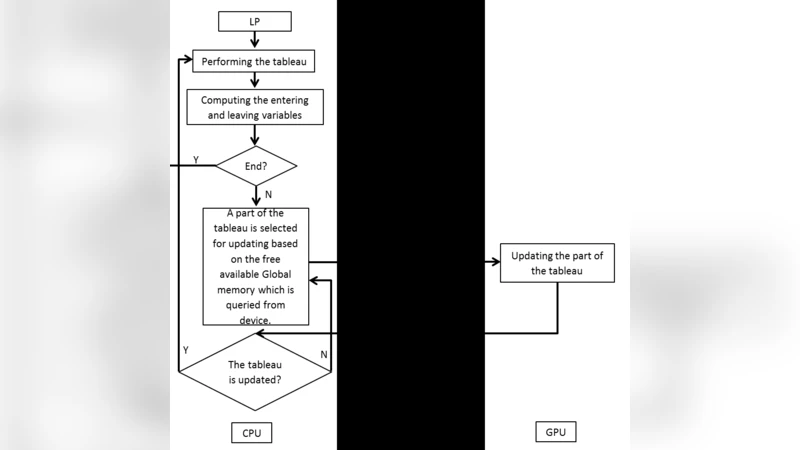
Memory Management. The authors store the immutable problem data (coefficient matrix A, cost vector c, right‑hand side b) in global memory, but they cache the frequently accessed portions of the basis matrix B and its inverse B⁻¹ in shared memory and registers. By partitioning B⁻¹ column‑wise across warps, each thread can compute a dot product with a row of A without incurring global‑memory latency. The implementation also leverages warp‑shuffle instructions to perform intra‑warp reductions for reduced‑cost calculations, thereby avoiding costly atomic operations. The basis update is performed via an LU‑based rank‑one modification, and the updated factors are written back to shared memory in a single coalesced transaction. This careful placement of data reduces memory‑traffic bottlenecks and enables the algorithm to sustain a high arithmetic intensity on the GPU.
Tabu Rule for Cycle Avoidance. Degeneracy can cause the Simplex method to revisit the same basis indefinitely. Instead of the classic Bland rule, which is deterministic but serial, the authors introduce a tabu list that temporarily forbids variables that have entered the basis within the last L iterations. The list resides in fast shared memory, and its length L is chosen adaptively based on problem size and available shared memory. Empirical results show that the tabu rule eliminates cycling in all test cases while allowing a broader set of candidates to be evaluated in parallel, thus improving overall throughput.
Algorithmic Flow. The GPU kernel proceeds as follows: (i) load the current basis and non‑basis indices; (ii) compute reduced costs for all non‑basic variables in parallel, applying the tabu filter; (iii) perform a block‑level reduction to select the entering variable; (iv) compute the direction vector and perform a parallel minimum‑ratio test to identify the leaving variable; (v) execute the pivot operation, update B⁻¹ via the LU rank‑one update, and write the new basis back to global memory; (vi) repeat until optimality or infeasibility is detected. Synchronization is limited to block‑level barriers, minimizing global stalls.
Experimental Evaluation. The authors benchmarked 30 LP instances drawn from the Netlib repository and the GAMS Model Library, covering variable counts from 10⁴ to 10⁶ and constraint counts from 10³ to 10⁵. They compared three configurations: (a) a sequential C++ implementation of the same Revised Simplex algorithm, (b) MATLAB’s linprog solver (which uses an interior‑point method), and (c) the proposed GPU version. Results show an average speed‑up of 78.3× over the sequential baseline and 27.5× over linprog. The maximum observed accelerations were 165.2× (vs. sequential) and 65.46× (vs. linprog). The gains are most pronounced for problems with more than 10⁵ variables, where the shared‑memory caching of B⁻¹ yields substantial latency reductions. For very small problems (< 10³ variables) the GPU overhead (kernel launch, data transfer) outweighs the benefits, leading to modest or negative speed‑ups.
Limitations and Future Work. The current implementation is restricted to a single GPU; scaling to multi‑GPU clusters would require sophisticated data partitioning and inter‑GPU communication strategies. The tabu length L and the amount of shared memory allocated to B⁻¹ are tuned manually, suggesting a need for an automatic performance model or autotuning framework. Numerical stability is addressed only through standard scaling; mixed‑precision or iterative refinement techniques could further improve robustness for ill‑conditioned bases. Finally, integrating the GPU Simplex with interior‑point phases could yield a hybrid solver that leverages the strengths of both methods.
In summary, the paper demonstrates that with careful memory hierarchy exploitation and a simple yet effective anti‑cycling mechanism, the Revised Simplex algorithm can be transformed into a highly parallel GPU kernel, delivering order‑of‑magnitude speed‑ups on large‑scale linear programs while maintaining correctness and convergence guarantees.
Comments & Academic Discussion
Loading comments...
Leave a Comment