Data Science Methodology for Cybersecurity Projects
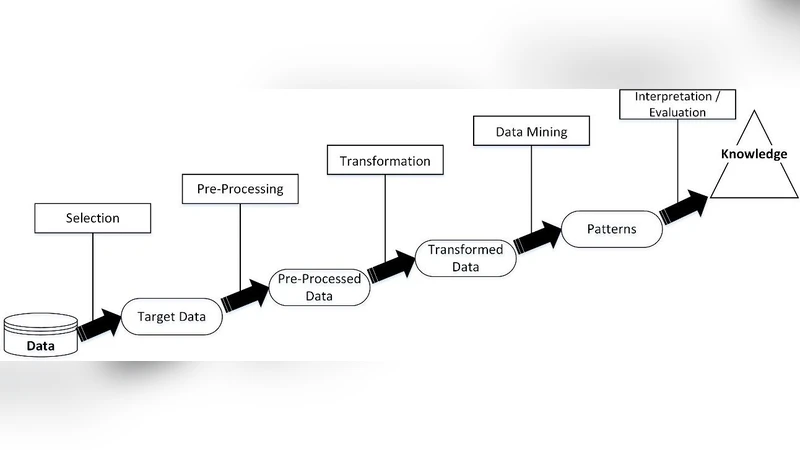
Cyber-security solutions are traditionally static and signature-based. The traditional solutions along with the use of analytic models, machine learning and big data could be improved by automatically trigger mitigation or provide relevant awareness to control or limit consequences of threats. This kind of intelligent solutions is covered in the context of Data Science for Cyber-security. Data Science provides a significant role in cyber-security by utilising the power of data (and big data), high-performance computing and data mining (and machine learning) to protect users against cyber-crimes. For this purpose, a successful data science project requires an effective methodology to cover all issues and provide adequate resources. In this paper, we are introducing popular data science methodologies and will compare them in accordance with cyber-security challenges. A comparison discussion has also delivered to explain methodologies strengths and weaknesses in case of cyber-security projects.
💡 Research Summary
The paper addresses the growing inadequacy of traditional static, signature‑based cybersecurity solutions in the face of rapidly evolving threats. It argues that a modern, intelligent defense system must leverage the full spectrum of data science capabilities—big data ingestion, high‑performance computing, machine learning, and automated mitigation—to move beyond reactive detection toward proactive, adaptive protection. To achieve this, the authors first review four widely‑adopted data‑science project methodologies: CRISP‑DM, the Knowledge Discovery in Databases (KDD) process, Microsoft’s Team Data Science Process (TDSP), and the newer AI‑Centric MLOps framework. For each methodology they map the canonical stages (business understanding, data understanding, data preparation, modeling, evaluation, deployment, and monitoring) to the specific requirements of cybersecurity projects, such as heterogeneous log and network‑traffic sources, real‑time streaming analytics, integration of external threat‑intel feeds, policy‑engine automation, regulatory compliance, and the need for explainable AI (XAI) and human‑in‑the‑loop oversight.
The analysis reveals distinct strengths and weaknesses. CRISP‑DM excels at structured documentation and iterative refinement but lacks built‑in support for continuous model retraining and streaming pipelines. KDD provides deep exploratory data analysis, which is valuable for feature engineering in anomaly detection, yet it does not prescribe systematic deployment or operational monitoring. TDSP offers an end‑to‑end Azure‑centric pipeline with native scalability and seamless integration with cloud security services (e.g., Azure Sentinel, Defender), but it is tied to a single cloud ecosystem and may be less flexible for hybrid environments. AI‑Centric MLOps delivers the most comprehensive automation—CI/CD for models, data versioning, drift detection, and automated rollback—making it ideal for maintaining robust defenses over time, though it demands higher upfront infrastructure investment and clear cross‑disciplinary collaboration.
Based on these findings, the authors propose a hybrid methodology tailored to cybersecurity. In the early discovery phase they recommend KDD‑style exploratory analysis to ingest and label diverse data sources (system logs, packet captures, endpoint telemetry, and threat‑intel indicators). For modeling and deployment they combine TDSP’s cloud‑native streaming architecture (Kafka/Event Hubs → Spark Structured Streaming → Delta Lake) with MLOps automation (Azure ML, MLflow, Kubernetes). This hybrid pipeline enables real‑time inference, automatic policy enforcement via security playbooks, and continuous performance monitoring. The paper also emphasizes the necessity of XAI techniques (e.g., SHAP) to surface the reasoning behind alerts, allowing security operations center (SOC) analysts to validate, override, or fine‑tune automated actions.
A concrete implementation example is presented: raw data is streamed through Apache Kafka to Azure Event Hubs, normalized and enriched in Spark, and fed to a suite of models (XGBoost for classification, Graph Neural Networks for lateral‑movement detection, Autoencoders for unsupervised anomaly detection). Model outputs are routed to Azure Sentinel’s playbooks, which trigger automated containment (firewall rule insertion, endpoint isolation) and generate contextual alerts. Model health metrics (accuracy, ROC‑AUC, false‑positive rate) are visualized in Azure Monitor dashboards; when drift is detected, a retraining job is automatically launched. Throughout, data governance policies enforce encryption, role‑based access, and audit logging to satisfy GDPR, ISO 27001, and other regulatory mandates.
The authors conclude that this hybrid, data‑science‑driven methodology delivers several tangible benefits over static defenses: higher detection accuracy, reduced false‑positive rates, faster response times, and sustainable model lifecycle management. Moreover, by formalizing collaboration between security experts and data scientists, the approach bridges skill gaps and builds long‑term organizational resilience against sophisticated cyber‑threats.
Comments & Academic Discussion
Loading comments...
Leave a Comment