Multi-Reference Video Coding Using Stillness Detection
Encoders of AOM/AV1 codec consider an input video sequence as succession of frames grouped in Golden-Frame (GF) groups. The coding structure of a GF group is fixed with a given GF group size. In the current AOM/AV1 encoder, video frames are coded usi…
Authors: Di Chen, Zoe Liu, Yaowu Xu
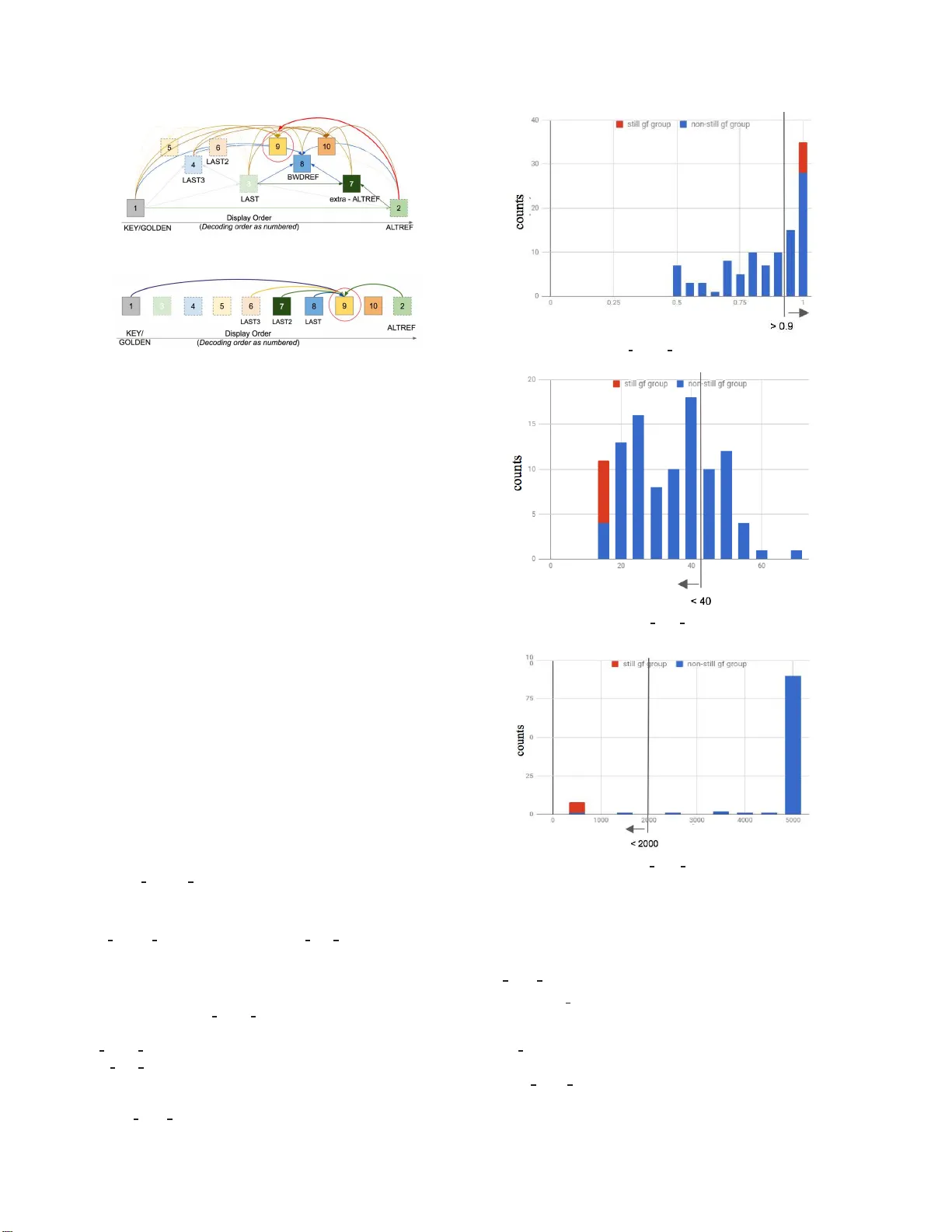
Multi-Refer ence V ideo Coding Using Still ness De tection Di Chen ⋆ , Zoe Liu † , Y aowu Xu † , Fengqing Zhu ⋆ , Edward Delp ⋆ † Google , I nc., 1600 Amphitheatre Parkway , Mountain Vie w , CA, USA 94043. ⋆ School of Electri cal an d Computer Engineering, Purdue Universi ty , West Lafa yette, Indiana, USA 47907. Abstract Encoder s of A OM/A V1 cod ec consider an input video se- quence as succession of fr ames gr ou ped in Golden-F r ame (GF) gr oups. The coding structur e of a GF gr oup is fixed with a given GF gr ou p size. In the curr ent A OM/A V1 enco der , video frames ar e coded usin g a hierar chical, multilayer coding structur e within one GF gr ou p. It has been observed that the use of multi l ayer coding structur e may r esult in worse coding pe rformance if the GF gr oup pr esents consistent stillness acr oss its frames. This paper pr o- poses a new appr oac h that adaptively designs the Golden-F ra me (GF) gr ou p coding st ructure throu gh the use of stillness detection. Our ne w appr oa ch hence develops an automatic still ness detec- tion scheme using three metrics extra cted fr om each GF gr oup. It then differ entiates those GF gr oups of stillness fr om other non- still GF gr oups and uses differ ent GF coding structur es accor d- ingly . Experimental r esult demonstrates a consistent coding gain using the new appr oach. Intr oduction The AOM /A V1 codec [1] is an open source, royalty-free video codec dev eloped by a consortium of major technolog y com- panies called Alliance for Open Media (A OM) which is jointly founded by Google. It foll o wed the VP 9 codec [2, 3], a video codec designed specifically for media on the web by Google W ebM Project [4]. The A OM/A V1 codec introduced se ve ral new features and cod ing tools such as switchable loop-restoration [5], global and locally warped motion compensation [6], and va ri- able block-size overlapped block motion compensation [7]. The A OM/A V1 is expected to achiev e generational improv ement in coding ef ficiency ov er VP9. Current A OM/A V1 codec divides the source video frames into Golden-Frame (GF) groups. The length of each GF group, i.e. the GF group interva l, may vary according to the video’ s spa- tial or t emporal characteristics and other encoder configurations, such as the key frame interval at request for the sake of random ac- cess or error resilience. The cod ing structure of each GF group is based on their interval length and the selection of reference frames buf fered for the coding of other frames. The coding structure de- termines the encoding order of each individual frame within one GF grou p. In the current implementation of the A OM/A V1 encoder , a GF group may hav e a length between 4 to 16 fr ames. V ar- ious GF coding structures may be designed depending on the encoder’s decision on t he construction of the reference frame buf fer , as shown in Figure 1a and F igure 1b. The extra-ALTREF FRAME s and the BWDREF F RAME s intro- duce hierarchical coding str ucture to t he GF groups [8]. The VP9 codec uses three referenc es for motion compensation , namely LAST F RAME , GOLDEN FRAME and AL TREF FRAME . GOLDEN FRA ME is the i ntra prediction frame. LAST FRAME is the forward reference frame. ALTREF FRAME is the backward reference frame selected from a distant future frame. It is t he last frame of each GF group. A ne w coding tool is adopted by A V1 that extends the number of reference frames by adding LAST2 FRAME , LAST3 FRAME , extra-ALTREF FRAME and BWDREF FRAME . LAST2 FRAM E and LAST3 FRAME are similar to LAST FRAME . extra-A LTREF FRAME and BWDREF FRAME are backward reference frames in a relatively shorter distance. The main differenc e is that BW DREF FRAME does not apply tempo ral fi ltering. The hierarchical cod ing structure in Figure 1a may greatly improve the coding efficiency due to its multi-layer , multi - backw ard reference design. The current A OM/A V1 encoder uses the coding structure sho wn in F igure 1a for all the GF grou ps. Howe ver , a comparison of the compression performance with ext ra-ALTREF FRAME and BWDREF FRAME enabled and disabled showed that the cod- ing efficiency for some test videos was actually w orse when these two reference frames were enabled. This means that t he mul- tilayer coding structure does not always hav e better coding ef- ficiency for all the GF groups. One such example is the GF groups with still ness feature. In this paper , we propose a ne w approach that adapti ve ly designs the Golden-Frame (GF) group coding structure through the use of stillness detection. A set of metrics are designed to determine whether t he frames in a GF group is of li t tle motion. Little work has been done that in vesti- gates the use of differenc e coding structures depending on video content. In [9], an adapti ve video coding control scheme is pro- posed that suggests using more P- and B-frame while the tem- poral correlation among the f r ames in a group of pictures (GOP) are high. A method for using differe nt GOP size based on video content is presented in [10]. Method GF Gr oup Stillness A GF group may be constructed to contain consistent charac- teristics to dif ferentiate itself from other GF groups. For instance, some GF group may present stillness across its successi v e fr ames, and other may present a zoom-in / zoom-out motion across the entire GF group. W e examined the coding efficienc y and the still - ness feature of each GF group and found that when stillness is present in one GF group, the use of multilayer coding st ructure as sho wn in Figure 1a may produce worse coding performance, as opposed to that generated by the one layer structure in Figure 1b. Automatic GF Group Stillness Detection An automatic sti llness detection of the G F groups is pro- posed in this paper which allows the GF groups to choose adap- tiv ely between two coding structure as sho wn in Figure 1a and (a) GF Group Coding Structure Using Multi layer (b) GF Group Coding Structure Us ing One Layer Figure 1. GF Group Coding Structures Figure 1b. Three metri cs are extracted from the GF group dur- ing the first coding pass of A OM/A V1 to determine the GF group stillness. The first coding pass of A OM/A V1 conducts a fast block matching with integer-pix el accuracy and use only one reference frame, the previous frame. Some motion ve ctor and motion com- pensation information are collected during t he first coding pass. Our proposed sti l lness detection method uses this information to extract three metrics as described below which requires small amount of computation. It then identifies the thresholds and de- riv es the criteria to classify GF groups into two categories: GF groups of stil lness and GF groups of non-stillness. The thresh- olds are obtained by collecting statistics of the three metrics from GF groups of eight lo w r esolution ( cif ) test vide os. W e manually labeled t he stillness or non-stillness of the GF groups. F igure 2 sho ws the histograms and the thresholds of the three metrics. W e intentionally i ncluded some test video s that co ntain GF groups of “stillness-like” characteristics in the non-stillness class because they are more likely to be misclassifi ed as GF group of stillness. The GF group with “still ness-like” characteristics shows either very slow motion or static background with small moving objects. W e obtained three criteria which are jointly applied to automati- cally detect stil lness. F inally , the GF group is coded using the workflo w given in Figure 3. Stillness Detection Metrics: 1. zero motion acumulator : Minimum of the per-frame percentage of zero-motion inter blocks wit hin one GF group : zer o mo t ion accumu l a t or = M I N ( pcnt zero mot i on F i | F i ∈ S ) (1) where S = { F i | i = 1 , 2 , ..., g f gr ou p in t er val } , the set of frames in the GF grou p g f gr ou p int er val : number of f r ames in the GF group pcn t zer o mo t ion : percentage of the zero-motion inter blocks out of all the inter block s 2. a vg pixel error : A verage of per-pixel sum of squared (a) zero mot ion accu mul at or (b) avg pixel er ror (c) avg er ror st d ev Figure 2. Thresholds f or Metrics errors (SSE) within one GF group: avg pixel error = M E AN ( f rame sse F i / number o f pixel s per f rame | Fi ∈ S ) (2) where f rame sse F i is the S SE of frame F i 3. avg error stdev : First ca lculate the standard deviation of the block-wise SSEs for each frame, where block SSEs are obtained from zero-motion prediction; then obtain the mean va lue Figure 3. GF Group Coding With Stillness Detection of the standard de viations of all the frames i n one GF grou p: avg error st d ev = M E AN ( ST DEV F i ( bl ock sse ( 0 , 0 ) ) | F i ∈ S ) (3) where bl ock sse ( 0 , 0 ) is the block-wise S SEs obtained from zero-motion prediction ST DEV F i is the standard dev iation of the block-wise SS Es of frame Fi W e use the abov e three metrics t o differentiate those GF groups of stillness features from other GF groups, subject to the criteria in T able 1. T able 1 Criteria for GF group stillness detection Stillne ss Detection Stillne ss Detection Metrics Crite ria (Identi fied as GF group of sti llness) zer o mo t ion accumul at or > 0.9 avg pixel er ror < 40 avg er ror s t d ev < 2000 Adaptive GF Group Structure Design Once a GF group is categorized as a GF group of stillness, no extra-ALTREF FRA ME or BWDREF FRAM E is used in t he sin- gle layer coding structure as sho wn in Figure 1b. The single layer coding structure still has multiple reference fr ames employe d f or the coding of one video frame. LAST FRAM E , LAST2 FRAME , LAST3 FRAME and GOLDEN F RAME are used as forward pre- diction reference and ALTREF FRAME i s used as backward pre- diction r eference. If a GF group is categorized as non-still GF group, we will further le verage the use of BWDREF FRAME and extra-ALTREF FRAME to help improv e the coding perfor- mance. Experimental Results W e tested the proposed method using two standard video test sets with various resolutions and spatial/temporal characteristics, as sho wn in T able 2. More specifically , the set of lowr es include s 40 videos of cif resolution, and the set of midr es includes 30 videos of 480p and 360p resolution. Each video i s coded with a single GOLDEN FRAME and a set of target bitrates. For qual- ity metrics we use the arithmetic av erage of the frame P SNR and SSIM [11]. T o compare RD curves obtained by the base A V1 codec and our proposed method, we use the BDRA T E metric [12]. Experimental results demonstrated the adv antage of the prop osed approach. The Google test set of lowr es has two video clips that contain detected still GF groups ( pamplet cif and bowing cif ) and test set midr es has one ( snow mnt ). As sho wn in T able 3, by ap- plying the proposed approach , the BDRA TE of video clips that contains GF groups of stillness has decreased by approximately 1%. The classification results of the proposed automatic still- ness detector contains no misclassification case in the videos from these two test video sets. There are mainly two reasons that the single layer coding structure has better coding efficiency on the GF groups with stil l ness feature. One is that the multil ayer coding structure in F igure 1a in vo lves more candidate reference frames thus requires more motion information to be transmitted to the decoder . T he other reason is that the multilayer coding structure uses an unbalanced bit allocation scheme which is not preferable for GF group of stillness in which t he frames are very si mi l ar . T able 2 BDRA T E Reduction Using Propo sed Method On Google T est S et test set BDRA TE(PSNR) BDRA TE(SSIM) test set of lowres -0.063 -0.045 test set of midres -0.026 -0.041 T able 3 BDRA TE Reduction Using Proposed Method On Video Clips Contain GF Group Of Sti llness video clip BDRA TE(PSNR) BDRA TE(SSIM) pamplet cif -1.395 -1.076 bowing cif -1.118 -0.735 snow mnt -0.767 -1.235 Conclusion and Future W ork W e proposed an automatic GF group stillness feature detec- tion method . Each GF groups is classified into still GF grou p and non-still GF group based on three metrics and the encoder adap- tiv ely chooses the coding structure based on optimized coding efficien cy . Experimental results sho wed coding gain for videos containing still GF group . W e also observ ed that GF groups con- taining other features, such as fast zoom-out and high motion, may also benefit from the single layer coding structure. References [1] htt p://www .aomedia.org/. [2] D. Mukherj ee, J. Bank oski, R. S. Bultje, A. Grange, J. Han, J. Kolesz ar , P . Wilk ins, and Y . Xu, “The latest open-source video codec vp9 - an ov ervie w and preliminar y results, ” Pr ocee dings of the IEEE Picture Coding Symposium , pp. 390–393, December 2013, San Jose, CA. [3] ——, “ A technica l ov ervie w of vp9 - the latest open-source video codec, ” SMPTE A nnual T echic al Conf er ence & Exhibit ion , Octo ber 2013. [4] htt p://www .webmproject.org / . [5] D. Mukh erjee, S. Li, Y . Chen, A. Anis, S. Pa rker , and J. Bankoski , “ A switcha ble loop-restorat ion with side-informati on frame w ork for the emergin g av1 video codec, ” P rocee dings of the IEEE Interna- tional Confer ence on Image Pr ocessin g , pp. 265–269, September 2017, Beijing , China. [6] S. Parker , Y . Chen, D. Barker , P . de Riv az, and D. Mukherjee , “Global and loc ally ad apti ve warped motion co mpensation in video compression, ” Pr ocee dings of the IEEE International Confer ence on Imag e Proce ssing , pp. 275–279, Sept ember 2017, Be ijing, China. [7] Y . Chen and D. Mukherjee , “V ariable block-size ov erlappe d block motion compensation in the ne xt gener ation open-source video codec, ” Pr oceedin gs of the IEEE Internati onal Confer enc e on Im- ag e Proce ssing , pp. 938–942, Sept ember 2017, Be ijing, China. [8] Z. Liu, D. Mukherjee , W . Lin, P . Wi lkins, J. Han, Y . Xu, and J. Banko ski, “ Adapt i ve multirefere nce predicti on using a symmet- ric frame work, ” Pr ocee dings of the IS&T Internat ional Symposium on Electr oni c Imagi ng, V isual Informati on Pr ocessing and Commu- nicati on VIII , pp. 65–72(8), January 2017, Burlingame, CA. [9] S. C. Hsia, “ An adapti ve video codi ng control sche me for real-time mpeg applicati ons, ” EURA SIP Journal on Advances in Signal Pr ocessing , vol. 2003, n o. 3, p . 161846, Mar 2003. [Online]. A vail able: https://do i.org/10 .1155/S1110865703210040 [10] B. Zatt, M. S. Porto, J. Scharcanski, and S. Bampi, “Gop s tructur e adapti ve to the video co ntent for effic ient h.264/avc encoding, ” Pr o- ceedi ngs of the International Confer ence on Image Pr oc essing , pp. 3053–3056, September 2010. [11] Z. W ang, A. C. Bovik, H. R. Sheikh , and E. P . Simoncell i, “Im- age quali ty assessment: from error visibili ty to structural similar - ity , ” IEEE T r ansactions on Image Pr ocessing , vol. 13, no. 4, pp. 600–612, April 2004. [12] G. Bjntegaa rd, “Calcula tion of avera ge psnr dif ferenc es between rdcurv es, ” V CEGM33, 13th VCEG meeting , March 2001, Austin, T exas. [13] D. Mukherje e, H. Su, J. Bankoski , A. Conv erse, J. Han, Z. L iu, and Y . Xu, “ An ov ervie w of video cod ing to ols unde r consid eration for vp10: the successor to vp9, ” Proc eedings of the SPIE, Applica- tions of Digital Image P r ocessing XXXVIII , vol. 9599, p. 95991E, September 2015. [14] M. Paul , W . Lin, C.-T . L au, and B. L ee, “ A long-term refere nce frame for hierarchic al b-pictu re-based vide o coding, ” IEEE Tr ans- action on Circuit s and Systems for V ideo T echnolo gy , vol. 24, no. 10, pp. 1729–1742, October 2014. [15] J. Bank oski, J. Kol eszar , L. Quillio, J . Salonen, P . W ilkins, and Y . Xu, “Vp8 data format and decodi ng guide, rfc 6386, ” http:/ /datat racker .ietf.org/doc/rfc6386/ . A uthor Biography Di Chen is a PhD candidate i n V ideo and Im age Pr ocessing Laborato ry (V I PER) at Purd ue University , W est Lafayette. Her r esear ch focuses on video analysis and compr ession. Curre ntly , she is working on textur e se gmentation based video compr ession using con volutional neural networks . Zoe Liu rece ived her Ph.D. in ECE from Pur due University . She once worked w ith corporate r esear ch institutes, pr ototyping mobile video confer encing platforms at Bell Labs (Lucent) and Nokia Resear c h Center . Zoe then devoted her effort to the design and deve lopment of F aceT ime at Apple, T ango V ideo Call with the startup of T angoMe, and Google Hangouts. She is curr ently working in the W ebM team of Google. Dr . Y aowu Xu is curr ently the T ech Lead Mana ger of the video coding r esear ch t eam at Google . Dr . Xu’s education backg r ound includes the BS de gr ee in Physics, the MS and PhD de gr ee in Nuclear Engineering fr om Tsinghua University at Beij ing, China. He also holds the MS and PhD de gr ee in Electrical and Computer Engine ering fr om University of Rochester . His curren t res ear ch focuses on advanced algorithms for digital video compr ession . F engqing Zhu is an Assistant Pr ofessor of Electrical and Computer E ngineering at Purdu e University , W est Lafayette, IN. Dr . Zhu received her Ph.D. in Electrical and C omputer Engineering fr om Pur due University in 2011. Prior t o joining Pur due in 2015, she was a Staff Resear che r at Huawei T ech- nolog ies (USA), where she received a Huawei Certification of Recognition for Core T echnolo gy Contribution in 2012. Her r esear ch inter ests include image pr ocessing and analysis, video compr ession , computer vision and computational photog raphy . Edwar d J. Delp was born in Cincinnati, Ohio. He is cur- r ently The Charles W ill iam Harrison Distinguished P rofessor of Electrical and Computer Engineering and Pro fessor of Biomedi- cal Engineering at Pur du e University . H i s r esear c h inter ests in- clude image and video pr oc essing, imag e analysis, computer vi- sion, image and video compr ession, multimedia security , medi- cal imaging , multimedia systems, communication and informa- tion theory . Dr . Delp is a Lif e F ellow of the IEEE , a F ellow of the SPIE, a F ellow of IS&T , and a F ellow of the American Institute of Medical and Biological Engineering .
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment