Fault Localization Models in Debugging
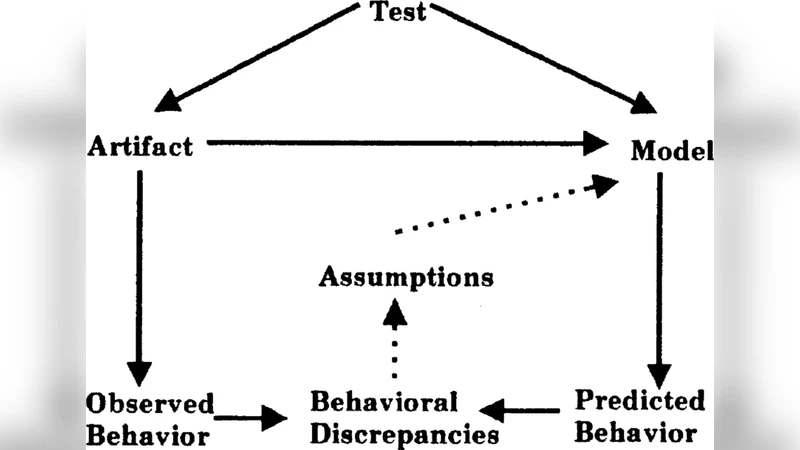
Debugging is considered as a rigorous but important feature of software engineering process. Since more than a decade, the software engineering research community is exploring different techniques for removal of faults from programs but it is quite difficult to overcome all the faults of software programs. Thus, it is still remains as a real challenge for software debugging and maintenance community. In this paper, we briefly introduced software anomalies and faults classification and then explained different fault localization models using theory of diagnosis. Furthermore, we compared and contrasted between value based and dependencies based models in accordance with different real misbehaviours and presented some insight information for the debugging process. Moreover, we discussed the results of both models and manifested the shortcomings as well as advantages of these models in terms of debugging and maintenance.
💡 Research Summary
The paper “Fault Localization Models in Debugging” provides a concise yet thorough examination of two principal approaches to pinpointing software faults: a value‑based model and a dependency‑based model, both grounded in the formal framework of diagnosis theory. After a brief introduction to software anomalies and a taxonomy of faults, the authors describe how diagnosis theory—originally developed for hardware and logical systems—can be adapted to software debugging by treating program components as a set of possible causes and observed erroneous behaviors as symptoms. Within this framework, the value‑based model collects concrete runtime values of variables and expressions, compares them against expected values derived from specifications or previous correct runs, and flags any deviation as a symptom. This approach excels at detecting simple arithmetic errors, boundary violations, and incorrect initializations because it directly measures quantitative discrepancies. However, it suffers from high false‑positive rates in contexts where values naturally fluctuate (e.g., stochastic algorithms, user‑driven input) and it struggles to isolate multi‑component faults where the causal chain is not evident from raw value differences alone.
Conversely, the dependency‑based model constructs a data‑flow and control‑flow graph that explicitly encodes the dependencies among program variables, functions, and modules. Symptoms are mapped to nodes that exhibit abnormal states, and a backward traversal of the graph yields a minimal set of predecessor nodes that could have caused the observed anomaly. This structural perspective is particularly powerful for logical bugs, incorrect conditional branches, and complex error propagation scenarios, because it captures the causal relationships that the value‑based model ignores. The main drawbacks are the overhead of building and maintaining an accurate dependency graph—especially in large, object‑oriented, or multi‑threaded codebases—and the computational cost of traversing a potentially massive graph during diagnosis.
To evaluate both models, the authors apply them to a curated set of real‑world misbehaviors, including array‑index out‑of‑bounds, faulty condition evaluation, and memory‑leak detection. The empirical results show that the value‑based model achieves rapid detection and high recall for single‑variable faults but exhibits a steep increase in false positives when faults involve multiple interacting variables. The dependency‑based model, while slower to initialize, consistently narrows the candidate fault set for composite errors and provides clearer insight into the propagation path. Nevertheless, its effectiveness is limited by incomplete or noisy dependency information, which can lead to missed faults or unnecessary candidates.
The discussion highlights that the two models are complementary rather than mutually exclusive. The authors propose a hybrid strategy: use the value‑based model for fast, coarse‑grained symptom detection, then invoke the dependency‑based analysis to refine the fault candidates and trace the root cause. They also suggest augmenting both models with machine‑learning techniques to learn typical symptom‑cause patterns from historical debugging data, and to dynamically update dependency graphs as the program evolves.
In conclusion, the paper underscores that fault localization remains a challenging aspect of software maintenance, but systematic comparison of different diagnostic models—grounded in a solid theoretical foundation—offers valuable guidance for both researchers and practitioners. By exposing the strengths and limitations of value‑centric and dependency‑centric approaches, the work paves the way for more robust, scalable, and automated debugging solutions.
Comments & Academic Discussion
Loading comments...
Leave a Comment