Multilayer bootstrap networks
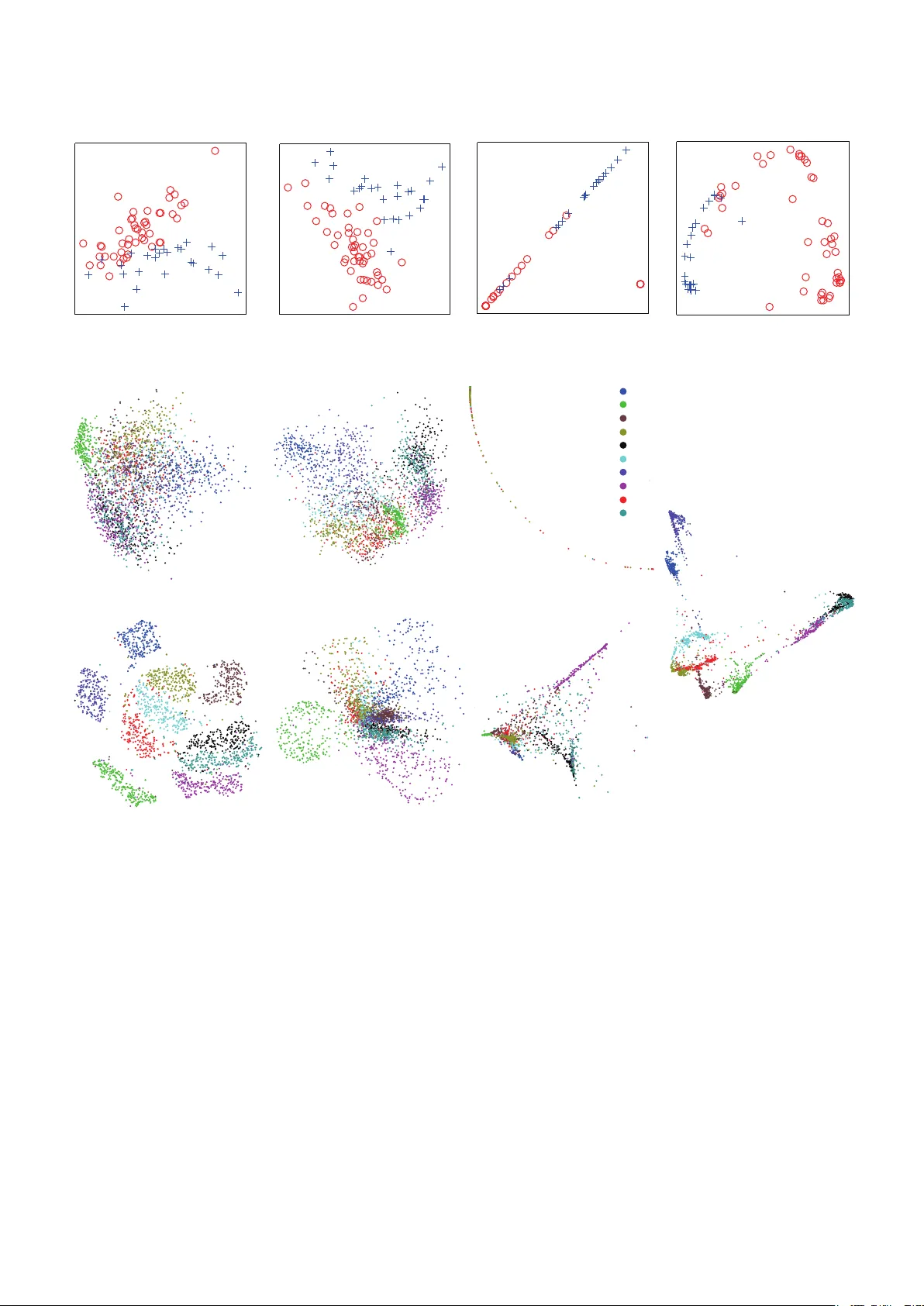
Multilayer bootstrap network builds a gradually narrowed multilayer nonlinear network from bottom up for unsupervised nonlinear dimensionality reduction. Each layer of the network is a nonparametric density estimator. It consists of a group of k-cent…
Authors: Xiao-Lei Zhang
Multilayer Bootstrap Networks Xiao-Lei Zhang ∗ Center for Intelligent Acoustics and Immersive Communications, Sc hool of Marine Science and T echnology , Northwestern P olytechnical University , China Abstract Multilayer bootstrap network builds a gradually narrowed multilayer nonlinear network from bottom up for unsupervised nonlinear dimensionality reduction. Each layer of the network is a nonparametric density estimator . It consists of a group of k-centroids clusterings. Each clustering randomly selects data points with randomly selected features as its centroids, and learns a one-hot encoder by one-nearest-neighbor optimization. Geometrically , the nonparametric density estimator at each layer projects the input data space to a uniformly-distributed discrete feature space, where the similarity of two data points in the discrete feature space is measured by the number of the nearest centroids they share in common. The multilayer network gradually reduces the nonlinear variations of data from bottom up by b uilding a v ast number of hierarchical trees implicitly on the original data space. Theoretically , the estimation error caused by the nonparametric density estimator is proportional to the correlation between the clusterings, both of which are reduced by the randomization steps. K e ywor ds: Resampling, ensemble, nearest neighbor, tree 1. Introduction Principal component analysis (PCA) ( Pearson , 1901 ) is a simple and widely used unsupervised dimensionality reduc- tion method, which finds a coordinate system in the original Euclidean space that the linearly uncorrelated coordinate axes (called principal components) describe the most v ariances of data. Because PCA is insu ffi cient to capture highly-nonlinear data distributions, many dimensionality reduction methods are explored. Dimensionality reduction has two core steps. The first step finds a suitable feature space where the density of data with the new feature representation can be well discovered, i.e. a density estimation problem. The second step discards the noise components or small v ariations of the data with the ne w feature representation, i.e. a principal component reduction problem in the new feature space. Dimensionality reduction methods are either linear ( He & Niyogi , 2004 ) or nonlinear based on the connection between the data space and the feature space. This paper focuses on non- linear methods, which can be categorized to three classes. The first class is kernel methods. It first projects data to a kernel- induced feature space, and then conducts PCA or its variants in the ne w space. Examples include kernel PCA ( Schölkopf et al. , 1998 ), Isomap ( T enenbaum et al. , 2000 ), locally linear em- bedding (LLE) ( Roweis & Saul , 2000 ), Laplacian eigenmaps ( Shi & Malik , 2000 ; Ng et al. , 2002 ; Belkin & Niyogi , 2003 ), t -distributed stochastic neighbor embedding (t-SNE) ( V an der ∗ Corresponding author Email addr ess: xiaolei.zhang9@gmail.com, xiaolei.zhang@nwpu.edu.cn (Xiao-Lei Zhang) URL: www.xiaolei-zhang.net (Xiao-Lei Zhang) Maaten & Hinton , 2008 ), and their generalizations ( Y an et al. , 2007 ; Nie et al. , 2011 ). The second class is probabilistic mod- els. It assumes that data are generated from an underlying prob- ability function, and takes the posterior parameters as the fea- ture representation. Examples include Gaussian mixture model and latent Dirichlet allocation ( Blei et al. , 2003 ). The third class is autoassociativ e neural networks ( Hinton & Salakhutdinov , 2006 ). It learns a piece wise-linear coordinate system explic- itly by backpropagation, and uses the output of the bottleneck layer as the new representation. Howe ver , the feature representations produced by the afore- mentioned methods are defined in continuous spaces. A funda- mental weakness of using a continuous space is that it is hard to find a simple mathematical form that transforms the data space to an ideal continuous feature space, since a real-world data dis- tribution may be non-uniform and irregular . T o overcome this di ffi culty , a large number of machine learning methods hav e been proposed, such as distance metric learning ( Xing et al. , 2002 ) and kernel learning ( Lanckriet et al. , 2004 ) for kernel methods, and Dirichlet process prior for Baysian probabilis- tic models ( T eh et al. , 2005 ), in which advanced optimization methods have to be applied. Recently , learning multiple layers of nonlinear transforms, named deep learning, is a trend ( Hin- ton & Salakhutdinov , 2006 ). A deep network contains more than one nonlinear layers. Each layer consists of a group of nonlinear computational units in parallel. Due to the hierar - chical structure and distrib uted representation at each layer , the representation learning ability of a deep network is exponen- tially more powerful than that of a shallo w network when giv en the same number of nonlinear units. Howe ver , the de v elopment of deep learning was mostly supervised, e.g. ( Schmidhuber , 2015 ; Hinton et al. , 2012 ; W ang & Chen , 2017 ; He et al. , 2016 ; Pr eprint submitted to Neural Networks Mar ch 7, 2018 Zhou & Feng , 2017 ; W ang et al. , 2017 ). T o our knowledge, deep learning for unsupervised dimensionality reduction seems far from explored ( Hinton & Salakhutdino v , 2006 ). T o overcome the aforementioned weakness in a simple way , we revisit the definition of frequentist probability for the den- sity estimation subproblem of dimensionality reduction. F r e- quentist pr obability defines an event’ s pr obability as the limit of its r elative fr equency in a larg e number of trials ( Wikipedia , 2017 ). In other words, the density of a local region of a prob- ability distribution can be approximated by counting the ev ents that fall into the local region. This paper focuses on exploring this idea. T o generate the ev ents, we resort to random resam- pling in statistics ( Efron , 1979 ; Efron & Tibshirani , 1993 ). T o count the events, we resort to one-nearest-neighbor optimiza- tion and binarize the feature space to a discrete space. T o further reduce the small variations and noise components of data, i.e. the second step of dimensionality reduction, we ex- tend the density estimator to a gradually narrowed deep archi- tecture, which essentially builds a vast number of hierarchical trees on the discrete feature space. The overall simple algorithm is named multilayer bootstrap networks (MBN). T o our knowledge, although ensemble learning ( Breiman , 2001 ; Freund & Schapire , 1995 ; Friedman et al. , 2000 ; Diet- terich , 2000 ; T ao et al. , 2006 ), which was triggered by random resampling, is a large family of machine learning, it is not very prev alent in unsupervised dimensionality reduction. Further- more, we did not find methods that estimate the density of data in discrete spaces by random resampling, nor their extensions to deep learning. This paper is organized as follows. In Section 2 , we describe MBN. In Section 3 , we give a geometric interpretation of MBN. In Section 4 , we justify MBN theoretically . In Section 5 , we study MBN empirically . In Section 6 , we introduce some re- lated work. In Section 7 , we summarize our contributions. 2. Multilayer bootstrap networks 2.1. Network structur e MBN contains multiple hidden layers and an output layer (Fig. 1 ). Each hidden layer consists of a group of mutually independent k -centroids clusterings; each k -centroids cluster- ing has k output units, each of which indicates one cluster; the output units of all k -centroids clusterings are concatenated as the input of their upper layer . The output layer is PCA. The netw ork is gradually narrowed from bottom up, which is implemented by setting parameter k as large as possible at the bottom layer and be smaller and smaller along with the increase of the number of layers until a predefined smallest k is reached. 2.2. T raining method MBN is trained layer-by-layer from bottom up. For training each layer giv en a d -dimensional input data set X = { x 1 , . . . , x n } either from the lower layer or from the original data space, we simply need to focus on training each k -centroids clustering, which consists of the following steps: (a) ( k =6) ( k =3) ( k =2) Cyclic-shift W 1 W 2 W 3 Layer 1 Layer 2 Layer 3 PCA (b) W 1 W 2 W 3 Figure 1: Network structure. The dimension of the input data for this demo network is 4. Each colored square represents a k -centroids clustering. Each layer contains 3 clusterings. Parameters k at layers 1, 2, and 3 are set to 6, 3, and 2 respectively . The outputs of all clusterings in a layer are concatenated as the input of their upper layer . • Random sampling of features. The first step randomly selects ˆ d dimensions of X ( ˆ d ≤ d ) to form a subset of X , denoted as ˆ X = { ˆ x 1 , . . . , ˆ x n } . • Random sampling of data. The second step randomly selects k data points from ˆ X as the k centroids of the clus- tering, denoted as { w 1 , . . . , w k } . • One-nearest-neighbor learning. The new representation of an input ˆ x produced by the current clustering is an in- dicator vector h which indicates the nearest centroid of ˆ x . For example, if the second centroid is the nearest one to ˆ x , then h = [0 , 1 , 0 , . . . , 0] T . The similarity metric between the centroids and ˆ x at the bottom layer is customized, e.g. the squared Euclidean distance arg min k i = 1 k w i − ˆ x k 2 , and set to arg max k i = 1 w T i ˆ x at all other hidden layers. 2.3. Novelty and advantag es T wo no vel components of MBN distinguish it from other di- mensionality reduction methods. The first component is that each layer is a nonparametric den- sity estimator based on resampling, which has the follo wing major merits: • It estimates the density of data correctly without any pre- defined model assumptions. As a corollary , it is insensitiv e to outliers. • The representation ability of a group of k -centroids clus- terings is e xponentially more powerful than that of a single k -centroids clustering. • The estimation error introduced by binarizing the feature space can be controlled to a small value by simply increas- ing the number of the clusterings. The second component is that MBN reduces the small vari- ations and noise components of data by an unsupervised deep ensemble architecture, which has the following main merits: • It reduces larger and larger local variations of data gradu- ally from bottom up by building as many as O ( k L 2 V ) hier- archical trees on the data space (instead of on data points) 2 4000x400 2000x400 1000x400 500x400 250x400 125x400 65x400 30x400 15x400 78 4 5 10 Prediction of training data Input 78 4 2048 2048 10 Step 2: Application Step 1: MBN training Step 3: NN training output Figure 2: Principle of compressive MBN. The numbers are the dimensions of representations. implicitly , where L is the total number of layers, k L is pa- rameter k at the L -th layer, V is the number of the cluster- ings at the layer , and function O ( · ) is the order in mathe- matics. • It does not inherit the problems of deep neural networks such as local minima, ov erfitting to small-scale data, and gradient vanishing, since it is trained simply by random resampling and stacking. As a result, it can be trained with as many hidden layers as needed and with both small-scale and large-scale data. See Sections 3 and 4 for the analysis of the abov e properties. 2.4. W eaknesses The main weakness of MBN is that the size of the network is large. Although MBN supports parallel computing, its predic- tion process is ine ffi cient, compared to a neural network. T o overcome this weakness, we propose compressive MBN (Fig. 2 ). Compressiv e MBN uses a neural network to learn a mapping function from the training data to the output of MBN at the training stage, and uses the neural network for prediction. More generally , if MBN is applied to some specific task, then we can use compressiv e MBN to learn a mapping function from the input data to the output of the task directly . 3. Geometric interpretation In this section, we analyze the two components of MBN from the geometric point of view . 3.1. F eatur e learning by a nonparametric density estimator based on r esampling As presented in Section 1 , a core problem of machine learn- ing is to find a suitable similarity metric that maps the original data space to a uniformly-distributed feature space. Here we giv e an example on its importance. As shown in Fig. 3 , the similarity between the data points that are far apart in a distri- bution with a large variance (e.g., x 1 and x 2 in a distribution P 1 ) might be the same as the similarity between the data points that are close to each other in a distribution with a small variance (e.g., x 3 and x 4 in a distribution P 2 ). If we use the Euclidean distance as the similarity metric, then the similarity between x 1 and x 2 is smaller than that between x 3 and x 4 , which is not true. The proposed method provides a simple solution to the above similarity metric learning problem. It outputs a new feature rep- resentation of x 1 as follows. Each k -centroids clustering con- tributes a neighboring centroid of x 1 . The centroid partitions the local region of x 1 to two disconnected parts, one contain- ing x 1 and the other not. The data point x 1 owns a local region supported by the centroids of all clusterings that are closest to the data point. 1 These centroids partition the local region to as many as O (2 V ) fractions. Each fraction is represented as a unique binary code at the output space of the estimator in a way illustrated in Fig. 4 . 2 The new representation of x 1 in the output feature space is a binary code that represents the local fraction of the data space where x 1 is located. W ith the new representation, the similarity between two data points is calculated by counting the number of the nearest cen- troids they share in common—a method in frequentist method- ology . In Fig. 3 , (i) if the local re gion in P 1 is partitioned in the same way as the local region in P 2 , and if the only di ff erence between them is that the local re gion in P 1 is an amplification of the local region in P 2 , then the surf aces of the two local re gions are the same in the discrete feature space. (ii) x 1 and x 2 share 5 common nearest centroids, and x 3 and x 4 also share 5 common nearest centroids, so that the similarity between x 1 and x 2 in P 1 equals to the similarity between x 3 and x 4 in P 2 . Note that because V k -centroids clusterings are able to parti- tion the data space to O ( k 2 V ) fractions at the maximum, its rep- resentation ability is e xponentially more po werful than a single k -centroids clustering. 3.2. Dimensionality r eduction by a deep ensemble arc hitectur e The nonparametric density estimator captures the v ariances of the input data, howe v er , it is not responsible for reducing the small v ariances and noise components. T o reduce the nonlinear variations, we build a gradually narrowed deep network. The network essentially reduces the nonlinear variations of data by building a vast number of hierarchical trees on the data space (instead of on data points) implicitly . W e present its geometric principle as follows. Suppose MBN has L layers, parameters k at layers 1 to L are k 1 , k 2 , . . . , k L respectiv ely , and k 1 > k 2 > . . . > k L . From Fig. 4 , we know that the l -th layer partitions the input data space to O ( k l 2 V ) disconnected small fractions. Each fraction is encoded as a single point in the output feature space. The points in the output feature space are the nodes of the trees. Hence, the l -th layer has O ( k l 2 V ) nodes. The bottom layer has O ( k 1 2 V ) leaf nodes. The top layer has O ( k L 2 V ) root nodes, which is the number of the trees that MBN builds. 1 It is important to keep parameter k of the k -centroids clusterings in a layer the same. Otherwise, the density of the centroids between the clusterings are di ff erent, that is to say , if we regard the centroids as the coordinates axes of the local region, then the coordinate axes are b uilt in di ff erent data spaces. 2 A small fraction should not hav e to contain data points as sho wn in Fig. 4 . 3 (b) (a) X 1 X 2 X 3 X 4 Figure 3: Illustration of the similarity metric problem at the data space. (a) The similarity problem of two data points x 1 (in red color) and x 2 (in blue color) in a distribution P 1 . The local re gion of x 1 (or x 2 ) is the area in a colored circle that is centered at x 1 (or x 2 ). The small hollo w points that lie in the cross area of the two local regions are the shared centroids by x 1 and x 2 . (b) The similarity problem of two data points x 3 and x 4 in a distribution P 2 . 001 01 0 10 0 (a ) ( b) (c) 00 1 00 1 00 1 10 0 001 010 10 0 00 1 10 0 10 0 100 010 01 0 00 1 01 0 10 0 010 010 (b) (a) 1 0 0 1 0 1 1 0 0 1 1 0 0 1 1 0 0 0 0 1 1 1 0 1 1 0 1 0 1 0 1 0 1 0 x 1 x 1 x 1 Figure 4: Encoding the local region of a data point x 1 (in blue color) by (a) one k -centroids clustering, (b) two k -centroids clusterings, and (c) three k -centroids clusterings. The centroids of the three k -centroids clusterings are the points colored in red, black, and green respectively . The local region of a centroid is the area in the circle around the centroid. The centroid itself and the edge of its local region are drawn in the same color . For two adjacent layers, because k l − 1 < k l , it is easy to see that O ( k l − 1 / k l ) neighboring child nodes at the ( l − 1)-th layer will be merged to a single father node at the l -th layer on average. T o generalize the above property to the entire MBN, a single root node at the L -th layer is a merging of O ( k 1 / k L ) leaf nodes at the bottom layer , which means that the nonlinear variations among the leaf nodes that are to be merged to the same root node will be reduced completely . Because k L k 1 , we can conclude that MBN is highly in v ariant to the nonlinear v ariations of data. One special case is that, if k L = 1, the output feature spaces of all k -centroids clusterings at the top layer are just a single point. Howe ver , in practice, we nev er set k L = 1; instead, we usually set the termination condition of MBN as k L ≥ 1 . 5 c where c is the ground-truth number of classes. The termination condition makes each k -centroids clustering stronger than random guess ( Schapire , 1990 ). Note that because O ( k 2 V ) n , the data points are distributed sparsely in the output feature space. Hence, MBN seldom merges data points. In other words, MBN learns data repre- sentations instead of doing agglomerativ e data clustering. 4. Theoretical analysis Although MBN estimates the density of data in the discrete feature space, its estimation error is small and controllable. Specifically , as shown in Fig. 4 c, V k -centroids clusterings can partition a local region to O (2 V ) disconnected small fractions at the maximum. It is easy to imagine that, for any local re- gion, when V is increasing and the diversity between the cen- troids is still reserved, an ensemble of k -centroids clusterings approximates the true data distrib ution. Because the div ersity is important, we hav e used two randomized steps to enlar ge it. In the following, we analyze the estimation error of the pro- posed method formally: Theorem 1. The estimation err or of the building block of MBN E ensemble and the estimation err or of a single k-centr oids cluster - ing E single have the following r elationship: E ensemble = 1 V + 1 − 1 V ! ρ ! E single (1) wher e ρ is the pairwise positive corr elation coe ffi cient between the k-centr oids clusterings, 0 ≤ ρ ≤ 1 . Pr oof. W e prove Theorem 1 by first transferring MBN to a su- pervised regression problem and then using the bias-variance 4 decomposition of the mean squared error to get the bias and variance components of MBN. The detail is as follo ws. Suppose the random samples for training the k -centroids clusterings are identically distributed but not necessarily in- dependent, and the pairwise positive corr elation coe ffi cient between two random samples (i.e., { w v 1 , i } k i = 1 and { w v 2 , j } k j = 1 , ∀ v 1 , v 2 = 1 , . . . , V and v 1 , v 2 ) is ρ , 0 ≤ ρ ≤ 1. W e focus on analyzing a giv en point x , and assume that the true local coordinate of x is s which is an in variant point around x and usually found when the density of the nearest centroids around x goes to infinity (i.e. n → ∞ , V → ∞ , { w v } V v = 1 are identically and independently distributed, and parameter k is unchanged). W e also suppose that x is projected to ˆ s when given a finite number of nearest centroids { w v } V v = 1 . The correlation coe ffi cient between the centroids { w v } V v = 1 is ρ . Note that s is used as an in v ariant reference point for studying ˆ s . The e ff ectiv eness of MBN can be ev aluated by the estimation error of the estimate ˆ s to the truth s . The estimation error is defined by E ( k s − ˆ s k 2 ) where E ( · ) is the expectation of a random variable. From the geometric interpretation, we kno w that each w v owns a local space S v , and moreover , both s and ˆ s are in S v . When parameter k → n , S v is small enough to be locally linear . Under the abo ve fact and an assumption that the features of w v , i.e. w v , 1 , . . . , w v , d , . . . , w v , D , are uncorrelated, we are able to as- sume that w v follows a multiv ariate normal distribution around s : w v ∼ MN ( s , σ 2 I ) where I is the identity matrix, σ describes the variance of w v and σ 2 I is the cov ariance matrix. W e can further derive E ( k s − ˆ s k 2 ) = P D d = 1 E (( s d − ˆ s d ) 2 ) where we denote s = [ s 1 , . . . , s D ] T and ˆ s = [ ˆ s 1 , . . . , ˆ s D ] T . In the following, we focus on analyzing the estimation error at a single dimension E (( s d − ˆ s d ) 2 ) and will omit the inde x d for clarity . It is kno wn that the mean squared error of a regression problem can be decomposed to the summation of a squared bias component and a variance component ( Hastie et al. , 2009 ): E (( s − ˆ s ) 2 ) = ( s − E ( ˆ s )) 2 + E ( ˆ s − E ( ˆ s )) 2 = Bias 2 ( ˆ s ) + V ar ( ˆ s ) (2) Because w v follows a univ ariate normal distribution, it is easy to obtain: E ( w v ) = s (3) E ( w 2 v ) = σ 2 + s 2 (4) E ( w v 1 w v 2 ) = ρσ 2 + s 2 (5) For a single estimate w v , we hav e ˆ s v = w v . For a set of estimates { w v } V v = 1 , we have ˆ s Σ = 1 V P V v = 1 w v . Based on Eqs. ( 3 ) to ( 5 ), we can deriv e: Bias 2 ( ˆ s v ) = 0 (6) σ 2 single = V ar ( ˆ s v ) = σ 2 (7) and Bias 2 ( ˆ s Σ ) = 0 (8) σ 2 ensemble = V ar ( ˆ s Σ ) = σ 2 V + 1 − 1 V ! ρσ 2 . (9) Substituting Eqs. ( 6 ) and ( 7 ) to Eq. ( 2 ) gets: E single = σ 2 (10) and substituting Eqs. ( 8 ) and ( 9 ) to Eq. ( 2 ) gets: E ensemble = σ 2 V + 1 − 1 V ! ρσ 2 . (11) Theorem 1 is prov ed. From Theorem 1 , we can get the follo wing corollaries easily: Corollary 1. When ρ is r educed fr om 1 to 0 , E ensemble is r educed fr om E single to E single / V accordingly . Corollary 2. When V → ∞ , E ensemble r eaches a lower bound ρ E single . From Corollary 1 , we know that increasing parameter V and reducing ρ can help MBN reduce the estimation error . From Corollary 2 , we know that it is important to reduce ρ . W e have adopted two randomization steps to reduce ρ . Ho w- ev er , although decreasing parameters a and k can help MBN reduce ρ , it will also cause E single rise. In other words, reducing E single and reducing ρ is a pair of contradictory factors, which needs a balance through a proper parameter setting. 5. Empirical evaluation In this section, we first introduce a typical parameter set- ting of MBN, then demonstrate the density estimation ability of MBN on synthetic data sets, and finally apply the low dimen- sional output of MBN to the tasks of visualization, clustering, and document retriev al. 5.1. P arameter setting When a data set is small-scale, we use the linear-kernel-based kernel PCA ( Schölkopf et al. , 1998 ; Canu et al. , 2005 ) as the PCA toolbox of MBN. When a data set is middle- or large- scale, we use the expectation-maximization PCA (EM-PCA) ( Roweis , 1998 ). 3 MBN is insensiti ve to parameters V and a as if V > 100 and a ∈ [0 . 5 , 1]. If not specified, we used V = 400 and a = 0 . 5 as the default v alues. W e denote parameter k at layer l as k l . T o control k l , we introduce a parameter δ defined as k l + 1 = δ k l , δ ∈ (0 , 1). MBN is relativ ely sensiti ve to parameter δ : if data are highly-nonlinear , then set δ to a large value, otherwise, set δ to a small value; if the nonlinearity of data is unknown, set δ = 0 . 5 which is our default. Finally , if k L + 1 < 1 . 5 c , then we stop MBN training and use the output of the L -th nonlinear layer for PCA. This terminating 3 The word “large-scale” means that the data cannot be handled by tradi- tional kernel methods on a common personal computer . 5 T able 1: Hyperparameters of MBN. Parameter Description δ A parameter that controls the network structure by k l + 1 = δ k l , ∀ l = 1 , . . . , L a Fraction of randomly selected dimensions (i.e., ˆ d ) over all dimensions (i.e., d ) of input data. V Number of k -centroids clusterings per layer . k 1 A parameter that controls the time and storage complexities of the network. For small-scale problems, k 1 = 0 . 5 n . For lar ge-scale problems, k 1 should be tuned smaller to fit MBN to the computing power . Gaussian data Jain data Pathbased data Compound data MBN on Gaussian data MBN on J ain data MBN on pathbased data MBN on compound data Figure 5: Density estimation by MBN on synthetic data sets. The data points in di ff erent classes are drawn in di ff erent colors. condition guarantees the v alidness of data resampling which re- quires each random sample of data to be stronger than random guess ( Schapire , 1990 ). The h yperparameters of MBN are sum- marized in T able 1 . In the following experiments, we adopted the above default parameter setting of MBN, unless otherwise specified. 5.2. Density estimation 5.2.1. Density estimation for nonlinear data distributions Four synthetic data sets with non-uniform densities and non- linear v ariations are used for ev aluation. They are Gaussian data, Jain data ( Jain & Law , 2005 ), pathbased data ( Chang & Y eung , 2008 ), and compound data ( Zahn , 1971 ), respectively . Parameter a was set to 1. The visualization result in Fig. 5 shows that the synthetic data in the new feature spaces produced by MBN not only are distributed uniformly but also do not contain many nonlinear variations. 5.2.2. Density estimation in the pr esence of outliers A data set of two-class Gaussian data with a randomly gen- erated outlier is used for ev aluation. The results of PCA and MBN are show in Fig. 6 . From the figure, we observe that MBN is robust to the presence of the outlier . 5.3. Data visualization 5.3.1. V isualizing AML-ALL biomedical data The acute myeloid leukemia and acute lymphoblastic leukemia (AML-ALL) biomedical data set ( Golub et al. , 1999 ) is a two-class problem that consists of 38 training examples (27 ALL, 11 AML) and 34 test examples (20 ALL, 14 AML). Each example has 7,129 dimensions produced from 6,817 hu- man genes. W e compared MBN with PCA and 2 nonlinear dimension- ality reduction methods which are Isomap ( T enenbaum et al. , 2000 ) and LLE ( Roweis & Saul , 2000 ). W e tuned the hyperpa- rameters of Isomap and LLE for their best performance. 4 The visualization result is shown in Fig. 7 . 5.3.2. V isualizing MNIST digits The data set of the MNIST digits ( Lecun et al. , 2004 ) con- tains 10 handwritten integer digits ranging from 0 to 9. It con- 4 It is di ffi cult and sometimes unable to tune the hyperparameters in practice. 6 -5 0 5 10 -5 0 5 10 Data wi t hout out li ers -5 0 5 -5 0 5 PCA on the data w ithout out liers -100 0 100 -100 0 100 MBN on the data w ithout out liers 0 5 10 15 x 1 0 5 0 5 10 15 x 1 0 5 D a ta wi th a n o u tl ie r 0 10 20 x 1 0 5 -4 -2 0 2 4 PCA on the data w ith an outlier -100 0 100 -100 -50 0 50 100 MBN on the data w ith an outlier Amplification Figure 6: Density estimation by MBN on a Gaussian data with the presence of an outlier. The red cross denotes the outlier . Because the outlier is far from the Gaussian data, the resolution of the sub-figure in the top-right corner is not high enough to di ff erentiate the two classes of the Gaussian data. sists of 60,000 training images and 10,000 test images. Each image has 784 dimensions. W e compared MBN with PCA, Isomap ( T enenbaum et al. , 2000 ), LLE ( Roweis & Saul , 2000 ), Spectral ( Ng et al. , 2002 ), deep belief networks ( Hinton & Salakhutdinov , 2006 ) (DBN), and t-SNE ( V an der Maaten & Hinton , 2008 ). W e tuned the hy- perparameters of the 5 nonlinear comparison methods for their best performance. Because the comparison nonlinear methods are too costly to run with the full MNIST data set except DBN, we randomly sampled 5,000 images with 500 images per digit for ev alua- tion. The visualization result in Fig. 8 sho ws that the low- dimensional feature produced by MBN has a small within-class variance and a lar ge between-class distance. T o demonstrate the scalability of MBN on larger data sets and its generalization ability on unseen data, we further trained MBN on all 60,000 training images, and e v aluated its e ff ectiv e- ness on the 10,000 test images, where k 1 was set to 8000 to re- duce the training cost. The visualization result in Fig. 9 shows that MBN on the full MNIST provides a clearer visualization than that on the small subset of MNIST . 5.4. Clustering T en benchmark data sets were used for ev aluation. They cov er topics in speech processing, chemistry , biomedicine, im- age processing, and text processing. The details of the data sets are given in T able 2 . The data set “20-Ne wsgroups”, which originally has 20,000 documents, was post-processed to a cor- pus of 18,846 documents, each belonging to a single topic. W e compared MBN with PCA and Spectral ( Ng et al. , 2002 ). W e applied k -means clustering to the low-dimensional out- puts of all comparison methods as well as the original high- dimensional features. T o prev ent the local minima problem of k -means clustering, we ran k -means clustering 50 times and picked the clustering result that corresponded to the optimal ob- jectiv e v alue of the k -means clustering among the 50 candidate objectiv e values as the final result. W e ran each comparison method 10 times and reported the av erage performance. The parameter settings on the data sets with IDs from 1 to 9 are as follows. For PCA, we preserved the top 98% largest eigen v alues and their corresponding eigen vectors. For Spec- tral, we set the output dimension to the ground-truth number of classes and adopted the RBF kernel. W e reported the re- sults with a fixed kernel width 2 − 4 A which behav es averagely the best over all data sets, as well as the best result by searching the kernel width from { 2 − 4 A , 2 − 3 A , . . . , 2 4 A } on each data set, where A is the av erage pairwise Euclidean distance between data. The two parameter selection methods of Spectral are de- noted as Spectral no _ tuning and Spectral o pt imal respectiv ely . For MBN, we set the output dimension to the ground-truth number of classes. W e reported the results with δ = 0 . 5, as well as the best results by searching δ from { 0 . 1 , 0 . 2 , . . . , 0 . 9 } on each data set. The two parameter selection methods of MBN are denoted as MBN no _ tuning and MBN o pt imal respectiv ely . The parameter settings on the 20-Ne wsgroups are as follows. For PCA, we set the output dimension to 100. For all compar- ison methods, we used the cosine similarity as the similarity metric. W e ev aluated the clustering result in terms of normalized mutual information (NMI) and clustering accuracy . The clus- tering results in T ables 3 and 4 show that (i) MBN no _ tuning achiev es better performance than Spectral no _ tuning and PCA, and (ii) MBN o pt imal achiev es better performance than Spectral o pt imal . Besides the data sets in T able 2 , we hav e also conducted ex- periments on the following data sets: Lung-Cancer biomedical data, COIL20 images, USPS images, Extended-Y aleB images, Reuters-21578 text corpus, and TDT2 text corpus. The exper- imental conclusions are consistent with the results in T ables 3 and 4 . 5.4.1. E ff ect of hyperparameter δ W e showed the e ff ect of parameter δ on each data set in Fig. 10 . From the figure, we do not observe a stable interval of δ where MBN is supposed to achie ve the optimal performance across the data sets; if the data are highly v ariant, then set- ting δ to a large v alue yields good performance, and vise v ersa. Generally , if the nonlinearity of data is unknown, then setting δ = 0 . 5 is safe. 5.4.2. E ff ects of hyperparameters a and V Theorem 1 has guaranteed that the estimation error can be reduced by enlar ging parameter V , and may also be reduced by 7 Isomap LLE PCA MBN Figure 7: V isualizations of AML-ALL produced by MBN and 3 comparison methods. Isomap LLE DBN MBN Spectral 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 3- di m ens i o nal f eat ur e 0 1 2 3 4 5 6 7 8 9 0. 2 0. 3 0. 4 0. 5 0. 6 0. 7 0. 8 0. 9 1 Ac c u r a c y 2- di m ens i onal f eat ur e 0 1 2 3 4 5 6 7 8 9 5- di m ens i onal f e at ur e 10- d i m ens i onal f eat ur e 20- di m ens i onal f eat ur e 30- di m ens i onal f eat ur e Number of layers Number of layers Number of layers B t-SNE PCA Figure 8: V isualizations of a subset (5,000 images) of MNIST produced by MBN and 6 comparison methods. For clarity , only 250 images per digit are dra wn. decreasing parameter a . In this subsection, we focus on in ves- tigating the stable working interv als of V and a . Because the experimental phenomena on all data sets are similar , we reported the phenomena on the small subset of MNIST as a representative in Fig. 11 . From the figure, we know that (i) we should pre vent setting a to a very small value. Empirically , we set a = 0 . 5. (ii) W e should set V ≥ 100. Em- pirically , we set V = 400. 5.5. Document r etrieval W e applied MBN to document retriev al and compared it with latent semantic analysis (LSA) ( Deerwester et al. , 1990 ), a doc- ument retriev al method based on PCA, on a larger data set— Reuters newswire stories ( Lewis et al. , 2004 ) which consist of 804,414 documents. The data set of the Reuters newswire sto- ries are di vided into 103 topics which are grouped into a tree structure. W e only preserved the 82 leaf topics. As a result, there were 107,132 unlabeled documents. W e preprocessed each document as a vector of 2,000 commonest word stems by the rainbow software ( McCallum , 1998 ) where each entry of a vector was set to the w ord count. W e randomly selected half of the data set for training and the other half for test. W e recorded the av erage accuracy ov er all 402,207 queries in the test set at the document retriev al set- ting, where a query and its retrie ved documents were di ff erent documents in the test set. If an unlabeled document was re- triev ed, it was considered as a mistake. If an unlabeled doc- ument was used as a query , no relev ant documents would be retriev ed, which means the precisions of the unlabeled query at all lev els were zero. Because the data set is relatively large, we did not adopt the default setting of MBN where k 1 = 201103. Instead, we set k 1 8 T able 2: Description of data sets. ID Name # data points # dimensions # classes Attribute 1 Isolet1 1560 617 26 Speech data 2 W ine 178 13 3 Chemical data 3 New-Th yroid 215 5 3 Biomedical data 4 Dermathology 366 34 6 Biomedical data 5 COIL100 7200 1024 100 Images 6 MNIST(small) 5000 768 10 Images (handwritten digits) 7 MNIST(full) 70000 768 10 Images (handwritten digits) 8 UMIST 575 1024 20 Images (faces) 9 ORL 400 1024 40 Images (faces) 10 20-Newsgroups 18846 26214 20 T ext corpus T able 3: NMI on 10 data sets. The numbers after ± are the standard deviations. Raw feature PCA Spectral no _ tuning MBN no _ tuning Spectral o ptimal MBN o ptimal 1 Isolet1 77.21% ± 0.92% 56.74% ± 0.75% 75.51% ± 0.58% 77.89% ± 0.81% 79.66% ± 0.58% 77.97% ± 0.64% 2 Wine 42.88% ± 0.00% 40.92% ± 0.00% 41.58% ± 0.00% 55.49% ± 4.07% 43.02% ± 0.00% 76.96% ± 3.24% 3 New-Thyroid 49.46% ± 0.00% 49.46% ± 0.00% 39.63% ± 0.00% 68.80% ± 5.03% 43.20% ± 0.00% 75.78% ± 2.75% 4 Dermathology 9.11% ± 0.11% 59.50% ± 0.10% 51.04% ± 0.15% 82.40% ± 2.24% 51.04% ± 0.15% 92.79% ± 1.09% 5 COIL100 76.98% ± 0.27% 69.64% ± 0.45% 89.28% ± 0.59% 81.66% ± 0.59% 89.28% ± 0.59% 90.37% ± 0.65% 6 MNIST(small) 49.69% ± 0.14% 27.86% ± 0.08% 62.06% ± 0.04% 77.12% ± 0.35% 62.06% ± 0.04% 78.50% ± 0.84% 7 MNIST(full) 50.32% ± 0.12% 28.05% ± 0.07% T imeout 91.36% ± 0.07% T imeout T imeout 8 UMIST 65.36% ± 1.21% 66.25% ± 1.10% 81.83% ± 0.58% 74.48% ± 1.91% 84.66% ± 2.38% 84.84% ± 1.98% 9 ORL 75.55% ± 1.36% 75.81% ± 1.17% 80.21% ± 1.13% 79.22% ± 0.84% 83.62% ± 1.13% 81.73% ± 1.19% 10 20-Newsgroups Timeout 22.49% ± 1.41% 27.03% ± 0.05% 41.61% ± 0.05% 27.03% ± 0.05% 42.23% ± 0.46% manually to 500 and 2000 respectiv ely , V = 200, and kept other parameters unchanged, i.e. a = 0 . 5 and δ = 0 . 5. Experimental results in Fig. 12 sho w that the MBN with the small network reaches an accuracy curve of ov er 8% higher than LSA; the MBN with the large network reaches an accu- racy curve of over 13% higher than LSA. The results indicate that enlarging the network size of MBN improv es its general- ization ability . 5.6. Empirical study on compr essive MBN This subsection studies the e ff ects of the compressiv e MBN on accelerating the prediction process of MBN. W e first studied the generalization ability of the compressi v e MBN on the 10,000 test images of MNIST , where the models of MBN and the compressi ve MBN are trained with the 60,000 training images of MNIST . The neural netw ork in the compres- siv e MBN contains 2 hidden layers with 2048 rectified linear units per layer . It projects the data space to the 2-dimensional feature space produced by MBN. The visualization results in Fig. 13 show that the compressi ve MBN produces an identical 2-dimensional feature with MBN on the training set and gener- alizes well on the test set. The prediction time of MBN and the compressiv e MBN is 4857.45 and 1.10 seconds, respecti vely . W e then studied the generalization ability of the compressi v e MBN in retrieving the Reuters newsware stories. The neural network here has the same structure with that on MNIST . It projects the data space to the 5-dimensional representation pro- duced by MBN. The result in Fig. 14 shows that the compres- siv e MBN produces an almost identical accuracy curve with MBN. The prediction time of MBN and the compressive MBN is 190,574.74 and 88.80 seconds, respectiv ely . 6. Discussions MBN is related to many methods in statistics and machine learning. Here we introduce its connection to histogram-based density estimators, bootstrap methods, clustering ensemble, vector quantization, product of experts, sparse coding, and un- supervised deep learning. 9 T able 4: Clustering accuracy on 10 data sets. Raw feature PCA Spectral no _ tuning MBN no _ tuning Spectral o ptimal MBN o ptimal 1 Isolet1 61.47% ± 1.93% 38.62% ± 0.99% 49.63% ± 1.88 61.13% ± 2.52% 72.29% ± 1.92% 62.50% ± 1.14% 2 Wine 70.22% ± 0.00% 78.09% ± 0.00% 61.24% ± 0.00 81.91% ± 2.61% 70.79% ± 0.00% 93.20% ± 1.77% 3 New-Thyroid 86.05% ± 0.00% 86.05% ± 0.00% 79.49% ± 0.94 93.02% ± 1.60% 82.79% ± 0.00% 94.51% ± 0.93% 4 Dermathology 26.17% ± 0.28% 61.67% ± 0.26% 50.38% ± 0.35 82.81% ± 7.67% 50.38% ± 0.35% 96.07% ± 0.79% 5 COIL100 49.75% ± 1.31% 43.42% ± 1.21% 61.83% ± 2.27 57.38% ± 1.85% 61.83% ± 2.27% 68.29% ± 1.58% 6 MNIST(small) 52.64% ± 0.14% 34.49% ± 0.10% 53.30% ± 0.01 82.36% ± 0.46% 56.55% ± 0.20% 87.06% ± 1.75% 7 MNIST(full) 53.48% ± 0.11% 35.14% ± 0.11% T imeout 96.64% ± 0.04% T imeout Timeout 8 UMIST 43.20% ± 1.66% 43.44% ± 1.92% 70.99% ± 2.19 56.96% ± 3.73% 70.99% ± 2.19% 73.22% ± 4.02% 9 ORL 54.37% ± 2.41% 54.55% ± 2.81% 57.33% ± 2.37 59.68% ± 1.58% 68.85% ± 2.48% 64.25% ± 3.50% 10 20-Newsgroups Timeout 22.61% ± 1.29% 28.52% ± 0.03 46.57% ± 1.10% 28.52% ± 0.03% 47.69% ± 0.92% 0 1 2 3 4 5 6 7 8 9 Figure 9: V isualization of the 10,000 test images of MNIST produced by the MBN at layer 8. For clarity , only 250 images per digit are drawn. See Appendix D for the visualizations produced by other layers. 6.1. Histogram-based density estimator s Histogram-based density estimation is a fundamental density estimation method, which estimates a probability function by accumulating the events that fall into the intervals of the func- tion ( Freedman et al. , 2007 ) where the interv als may have an equiv alent length or not. Our proposed density estimator is es- sentially such an approach. An interval in our approach is de- fined as the data space between two data points. The accumu- lated events in the interval are the shared centroids by the two data points. 6.2. Bootstrap methods Bootstrap resampling ( Efron , 1979 ; Efron & Tibshirani , 1993 ) has been applied successfully to machine learning. It re- samples data with r eplacement . MBN does not adopt the stan- dard bootstrap resampling. In fact, MBN uses random subsam- pling without r eplacement , also known as delete-d jackknife r e- sampling in statistics ( Efron & Tibshirani , 1993 ). The reason why we do not adopt the standard bootstrap resampling is that the resampling in MBN is used to build local coordinate sys- tems, hence, if a data point is sampled multiple times, the du- plicated data points are still viewed as a single coordinate axis. Moreov er , it will cause the k -centroids clusterings built in dif- ferent data spaces. Ho wev er , MBN was motiv ated from and shares many common properties with the bootstrap methods, such as building each base clustering from a random sample of the input and de-correlating the base clusterings by the random sampling of features ( Breiman , 2001 ) at each base clustering, hence, we adopted the phrase “bootstrap” in MBN and clarify its usage here for prev enting confusion. 6.3. Clustering ensemble Clustering ensemble ( Strehl & Ghosh , 2003 ; Dudoit & Fridlyand , 2003 ; Fern & Brodley , 2003 ; Fred & Jain , 2005 ; Zheng et al. , 2010 ; V ega-Pons & Ruiz-Shulcloper , 2011 ) is a clustering technique that uses a consensus function to aggre- gate the clustering results of a set of mutually-independent base clusterings. Each base clustering is usually used to classify data to the ground-truth number of classes. An exceptional cluster- ing ensemble method is ( Fred & Jain , 2005 ), in which each base k -means clustering produces a subclass partition by assigning the parameter k to a random value that is slightly lar ger than the ground-truth number of classes. Each layer of MBN can be re garded as a clustering ensemble. Howe ver , its purpose is to estimate the density of data instead of producing an aggregated clustering result. Moreov er , MBN has clear theoretical and geometric explanations. W e have also found that setting k to a random value does not work for MBN, particularly when k is also small. 6.4. V ector quantization Each layer of MBN can be regarded as a vector quantizer to the input data space. The codebook produced by MBN is ex- ponentially smaller than that produced by a traditional k -means clustering, when they hav e the same level of quantization errors. A similar idea, named pr oduct quantization , has been explored in ( Jegou et al. , 2011 ). If product quantization uses random 10 0.1 0.3 0.5 0.7 0.9 0.6 0.7 0.8 NMI Isolate1 0.1 0.3 0.5 0.7 0.9 0.2 0.4 0.6 0.8 Wine 0.1 0.3 0.5 0.7 0.9 0.2 0.4 0.6 0.8 New-Thyroid 0.1 0.3 0.5 0.7 0.9 0.4 0.6 0.8 1 NMI Dermathology 0.1 0.3 0.5 0.7 0.9 0.6 0.8 1 COIL100 0.1 0.3 0.5 0.7 0.9 0.2 0.4 0.6 0.8 MNIST(small) 0.1 0.3 0.5 0.7 0.9 / 0.4 0.6 0.8 1 NMI UMIST 0.1 0.3 0.5 0.7 0.9 / 0.7 0.75 0.8 0.85 ORL 0.1 0.3 0.5 0.7 0.9 / 0 0.2 0.4 0.6 20-Newsgroups Figure 10: E ff ect of decay factor δ on 9 benchmark data sets. 0 0. 1 0. 2 0. 3 0. 4 0. 5 0. 6 0. 7 0. 8 0. 9 1 P aram et er a NM I E f f ec t of paramet er a 0. 05 0. 1 0. 2 0. 5 1 Traini ng ac c urac y Te st accu ra cy 0 0. 1 0. 2 0. 3 0. 4 0. 5 0. 6 0. 7 0. 8 0. 9 1 1 5 10 20 30 50 100 200 400 Para m ete r V NMI Effec t of pa ramete r V Figure 11: E ff ect of parameters a and V on the subset of MNIST . sampling of features instead of a fixed non-overlapping parti- tion of features in ( Jegou et al. , 2011 ), and uses random sam- pling of data points to train each k -means clustering instead of the e xpectation-maximization optimization, then product quan- tization equals to a single layer of MBN. W e are also aware of the hierarchical product quantizer ( W ichert , 2012 ), which builds multiple sets of sub-quantizers (where the name “hier- archy” comes) on the original feature. Our MBN builds each layer of sub-quantizers on the output sparse feature of its lo wer layer which is fundamentally di ff erent from the hierarchical product quantization method. An important di ff erence between existing vector quantization methods (e.g. binarized neural networks and binary hashing) and MBN is that the former are designed for reducing the com- putational and storage complexities, while MBN is not dev el- oped for this purpose. MBN aims at providing a simple way to overcome the di ffi culty of density estimation in a continu- ous space. Hence, it generates larger codebooks than common vector quantization methods and does not transform the sparse codes to compact binary codes. 6.5. Pr oduct of e xperts PoE aims to combine multiple indi vidual models by multi- plying them, where the indi vidual models have to be a bit more complicated and each contains one or more hidden variables ( Hinton , 2002 ). Its general probability framew ork is: p ( x ) = Q V v = 1 g v ( x ) P x 0 Q V v = 1 g v ( x 0 ) (12) where x 0 index es all possible vectors in the data space, and g v is called an expert . A major merit of PoE is that, a func- tion that can be fully expressed by a mixture of experts with N experts (i.e. mixtures), such as Gaussian mixture model or k - means clustering, can be expressed compactly by a PoE with only log 2 N experts at the minimum, with the expense of the optimization di ffi culty of the partition function P x 0 Q V v = 1 g v ( x 0 ) which consists of an exponentially lar ge number of compo- nents. The connection between MBN and PoE is as follows: Theorem 2. Each layer of MBN is a P oE that does not need to optimize the partition function. 11 0 0. 05 0. 1 0. 15 0. 2 0. 25 0. 3 0. 35 0. 4 0. 45 0. 5 0. 55 1 3 7 15 31 63 127 255 511 1023 Number of ret riev ed doc ument s LSA MBN ( k 1 = 500) at l ay er 1 MBN ( k 1 = 500) at l ay er 2 MBN ( k 1 = 500) at l ay er 3 0 0. 05 0. 1 0. 15 0. 2 0. 25 0. 3 0. 35 0. 4 0. 45 0. 5 0. 55 1 3 7 15 31 63 127 255 511 1023 Number of ret riev ed doc ument s LSA MBN ( k 1 =2 0 00 ) a t la ye r 1 MBN ( k 1 =2 0 00 ) a t la ye r 2 MBN ( k 1 =2 0 00 ) a t la ye r 3 MBN ( k 1 =2 0 00 ) a t la ye r 4 MBN ( k 1 =2 0 00 ) a t la ye r 5 Accu ra cy Accu ra cy Figure 12: A verage accuracy curves of retrie ved documents on the test set (82 topics) of the Reuters ne wswire stories. Visualizing training data Generalization on test data 0 1 2 3 4 5 6 7 8 9 Visualizing training data (With random reconstruction) Generalization on test data (With random reconstruction) CD Figure 13: V isualizations of the training data (left) and test data (right) of MNIST produced by the compressiv e MBN. Pr oof. See Appendix B for the proof. 6.6. Sparse coding Giv en a learned dictionary W , sparse coding typically aims to solv e min h i P n i = 1 k x i − Wh i k 2 2 + λ k h i k 1 1 , where k · k q represents ` q -norm, h i is the sparse code of the data point x i , and λ is a hyperparameter controlling the sparsity of h i . Each column of W is called a basis vector . T o understand the connection between MBN and sparse cod- ing, we may vie w λ as a hyperparameter that controls the num- ber of clusterings. Specifically , if we set λ = 0, it is likely that h i contains only one nonzero element. Intuitively , we can un- derstand it as that we use only one clustering to learn a sparse code. A good value of λ can make a small part of the elements of h i nonzero. This choice approximates to the method of parti- tioning the dictionary to several (probably overlapped) subsets and then grouping the basis vectors in each subset to a base clustering. Motiv ated by the above intuiti ve analysis, we intro- duce the connection between sparse coding and MBN formally as follows: Theorem 3. The ` 1 -norm spar se coding is a con ve x r elaxation of the building bloc k of MBN when given the same dictionary . Pr oof. See Appendix C for the proof. 0 0. 05 0. 1 0. 15 0. 2 0. 25 0. 3 0. 35 0. 4 0. 45 0. 5 0. 55 1 3 7 1 5 3 1 6 3 127 255 511 1023 N u m ber of r e t r i e v e d doc um ent s A ccu r a cy LS A DNN appr ox i m at i on of LS A 0 0. 05 0. 1 0. 15 0. 2 0. 25 0. 3 0. 35 0. 4 0. 45 0. 5 0. 55 1 3 7 1 5 3 1 6 3 127 255 511 1023 N u m b er of r e t r i e v ed doc um ent s A ccu r a cy MB N a t la y e r 1 C o m p r e ssi ve M B N a t l a ye r 1 0 0. 05 0. 1 0. 15 0. 2 0. 25 0. 3 0. 35 0. 4 0. 45 0. 5 0. 55 1 3 7 1 5 3 1 6 3 127 255 511 1023 N u m b er of r e t r i e v ed doc u m ent s Ac c u r a c y MB N a t la y e r 2 C o m p r e ssi ve M B N a t l a ye r 2 0 0. 05 0. 1 0. 15 0. 2 0. 25 0. 3 0. 35 0. 4 0. 45 0. 5 0. 55 1 3 7 1 5 3 1 6 3 127 255 511 1023 N u m ber of r e t r i e v e d doc u m ent s Ac c u r a c y MB N a t la y e r 3 Co m p re s s i v e M B N a t l a y e r 3 0 0. 05 0. 1 0. 15 0. 2 0. 25 0. 3 0. 35 0. 4 0. 45 0. 5 0. 55 1 3 7 1 5 3 1 6 3 127 255 511 1023 N u m ber of r e t r i e v e d doc u m ent s A c cu r a cy MB N a t la y e r 4 C o m p r e ssi ve M B N a t l a ye r 4 0 0. 05 0. 1 0. 15 0. 2 0. 25 0. 3 0. 35 0. 4 0. 45 0. 5 0. 55 1 3 7 15 31 63 127 255 511 1023 Number of ret riev ed doc um ent s Accu r a cy MBN a t layer 5 C o mp r essi ve M BN at la yer 5 Figure 14: Comparison of the generalization ability of MBN and the compres- siv e MBN on retrieving the Reuters ne wsware stories. 6.7. Unsupervised deep learning Learning abstract representations by deep networks is a re- cent trend. From the geometric point of view , the abstract rep- resentations are produced by reducing larger and larger local variations of data from bottom up in the frame work of trees that are built on data spaces. 5 For example, con volutional neural network merges child nodes by pooling. Hierarchical Dirichlet process ( T eh et al. , 2005 ) builds trees whose f ather nodes gener- ate child nodes according to a prior distribution. DBN ( Hinton & Salakhutdinov , 2006 ) merges child nodes by reducing the number of the nonlinear units gradually from bottom up. Sub- space tree ( Wichert & Moreira , 2015 ) merges nodes by reduc- ing the dimensions of the subspaces gradually . PCANet ( Chan et al. , 2015 ) merges nodes by reducing the output dimensions of the local PCA associated with its patches gradually . Our MBN merges nodes by reducing the number of the randomly sampled centroids gradually . A fundamental di ff erence between the methods is how to build e ff ectiv e local coordinate systems in each layer . T o our knowledge, MBN is a simple method and needs little assump- tion and prior knowledge. It is only more complicated than 5 Some recent unsupervised deep models for data augmentation are out of the discussion, hence we omit them here. 12 random projection which is, to our knowledge, not an e ff ec- tiv e method for unsupervised deep learning to date. Moreov er , MBN is the only method working in discrete feature spaces, and it works well. 7. Conclusions In this paper , we hav e proposed multilayer bootstrap net- work for nonlinear dimensionality reduction. MBN has a nov el network structure that each expert is a k -centroids clustering whose centroids are randomly sampled data points with ran- domly sampled features; the network is gradually narrowed from bottom up. MBN is composed of two nov el components: (i) each layer of MBN is a nonparametric density estimator by random re- sampling. It estimates the density of data correctly without any model assumption. It is exponentially more powerful than a single k -centroids clustering. Its estimation error is proven to be small and controllable. (ii) The network is a deep ensemble model. It essentially reduces the nonlinear variations of data by building a vast number of hierarchical trees on the data space. It can be trained as many layers as needed with both lar ge-scale and small-scale data. MBN performs robustly with a wide range of parameter set- tings. Its time and storage complexities scale linearly with the size of training data. It supports parallel computing naturally . Empirical results demonstrate its e ffi ciency at the training stage and its e ff ectiv eness in density estimation, data visualization, clustering, and document retriev al. W e hav e also demonstrated that the high computational complexity of MBN at the test stage can be eliminated by the compressiv e MBN—a framework of unsupervised model compression based on neural networks. A problem left is on the selection of parameter δ which con- trols the network structure. Although the performance of MBN with δ = 0 . 5 is good, there is still a large performance gap between δ = 0 . 5 and the best δ . Hence, how to select δ auto- matically is an important problem. Acknowledgement The author thanks Prof. DeLiang W ang for providing his computing resources. The author also thanks the action editor and revie wers for their comments which improv ed the quality of the paper . This work was supported by the National Natural Science Foundation of China under Grant 61671381. References References Belkin, M., & Niyogi, P . (2003). Laplacian eigenmaps for dimensionality re- duction and data representation. Neural Comput. , 15 , 1373–1396. Bishop, C. M. et al. (2006). P attern Recognition and Machine Learning . Springer New Y ork:. Blei, D. M., Ng, A. Y ., & Jordan, M. I. (2003). Latent dirichlet allocation. J. Mach. Learn. Res. , 3 , 993–1022. Boyd, S. P ., & V andenberghe, L. (2004). Conve x Optimization . Cambridge Univ ersity Press. Breiman, L. (2001). Random forests. Machine Learning , 45 , 5–32. Canu, S., Grandvalet, Y ., Guigue, V ., & Rakotomamonjy , A. (2005). SVM and kernel methods Matlab toolbox. http://asi.insa- rouen.fr/ enseignants/~arakoto/toolbox/index.html . Chan, T .-H., Jia, K., Gao, S., Lu, J., Zeng, Z., & Ma, Y . (2015). Pcanet: A simple deep learning baseline for image classification? IEEE T ransactions on Image Pr ocessing , 24 , 5017–5032. Chang, H., & Y eung, D.-Y . (2008). Robust path-based spectral clustering. P at- tern Recognition , 41 , 191–203. Deerwester , S. C., Dumais, S. T ., Landauer, T . K., Furnas, G. W ., & Harshman, R. A. (1990). Indexing by latent semantic analysis. J ournal of the American Society for Information Science , 41 , 391–407. Dietterich, T . G. (2000). Ensemble methods in machine learning. In Multiple Classifier Systems (pp. 1–15). Cagliari, Italy: Springer . Dudoit, S., & Fridlyand, J. (2003). Bagging to improve the accuracy of a clus- tering procedure. Bioinformatics , 19 , 1090–1099. Efron, B. (1979). Bootstrap methods: another look at the jackknife. Annals of Statistics , 7 , 1–26. Efron, B., & Tibshirani, R. (1993). An Intr oduction to the Bootstrap . CRC press. Fern, X. Z., & Brodley , C. E. (2003). Random projection for high dimensional data clustering: A cluster ensemble approach. In Proceedings of the 20th International Confer ence on Machine Learning (pp. 186–193). volume 3. Fred, A. L., & Jain, A. K. (2005). Combining multiple clusterings using e vi- dence accumulation. IEEE Tr ansactions on P attern Analysis and Machine Intelligence , 27 , 835–850. Freedman, D., Pisani, R., & Purves, R. (2007). Statistics (4th edition). Freund, Y ., & Schapire, R. E. (1995). A decision-theoretic generalization of on-line learning and an application to boosting. In Pr oceedings of the 2nd European Confer ence on Computational Learning Theory (pp. 23–37). Barcelona, Spain. Friedman, J., Hastie, T ., Tibshirani, R. et al. (2000). Additive logistic regres- sion: A statistical view of boosting (with discussion and a rejoinder by the authors). Annals of Statistics , 28 , 337–407. Golub, T . R., Slonim, D. K., T amayo, P ., Huard, C., Gaasenbeek, M., Mesirov , J. P ., Coller , H., Loh, M. L., Downing, J. R., Caligiuri, M. A. et al. (1999). Molecular classification of cancer: class discovery and class prediction by gene expression monitoring. Science , 286 , 531–537. Hastie, T ., Tibshirani, R., & Friedman, J. (2009). The Elements of Statistical Learning . Springer . He, K., Zhang, X., Ren, S., & Sun, J. (2016). Deep residual learning for im- age recognition. In Proceedings of 2016 IEEE International Conference on Computer V ision and P attern Recognition (pp. 770–778). Las V egas, NV . He, X., & Niyogi, X. (2004). Locality preserving projections. In Advances in Neural Information Pr ocessing Systems 17 (pp. 153–160). V ancouver , British Columbia, Canada volume 16. Hinton, G., Deng, L., Y u, D., Dahl, G. E., Mohamed, A.-r ., Jaitly , N., Senior, A., V anhoucke, V ., Nguyen, P ., Sainath, T . N. et al. (2012). Deep neural networks for acoustic modeling in speech recognition: The shared views of four research groups. IEEE Signal Pr ocessing Magazine , 29 , 82–97. Hinton, G. E. (2002). T raining products of experts by minimizing contrastiv e div ergence. Neural Computation , 14 , 1771–1800. Hinton, G. E., & Salakhutdinov , R. R. (2006). Reducing the dimensionality of data with neural networks. Science , 313 , 504–507. Jain, A. K., & Law , M. H. (2005). Data clustering: A user’ s dilemma. Lecture Notes in Computer Science , 3776 , 1–10. Jegou, H., Douze, M., & Schmid, C. (2011). Product quantization for near- est neighbor search. IEEE transactions on pattern analysis and machine intelligence , 33 , 117–128. Lanckriet, G. R. G., Cristianini, N., Bartlett, P ., Ghaoui, L. E., & Jordan, M. I. (2004). Learning the kernel matrix with semidefinite programming. J. Mach. Learn. Res. , 5 , 27–72. Lecun, Y ., Cortes, C., & Burges, C. J. C. (2004). THE MNIST DA T ABASE of handwritten digits. http://yann.lecun.com/exdb/mnist/index. html . Lewis, D. D., Y ang, Y ., Rose, T . G., & Li, F . (2004). RCV1: a new benchmark collection for text categorization research. Journal of Machine Learning Resear ch , 5 , 361–397. V an der Maaten, L., & Hinton, G. E. (2008). V isualizing data using t-sne. Journal of Mac hine Learning Resear ch , 9 , 2579–2605. McCallum, A. (1998). Rainbow . http://www.cs.cmu.edu/~mccallum/ 13 bow/rainbow . Ng, A. Y ., Jordan, M. I., & W eiss, Y . (2002). On spectral clustering: Analysis and an algorithm. In Advances in Neural Information Pr ocessing Systems 14 (pp. 849–856). V ancouver , British Columbia, Canada. Nie, F ., Zeng, Z., Tsang, I. W ., Xu, D., & Zhang, C. (2011). Spectral em- bedded clustering: A framework for in-sample and out-of-sample spectral clustering. IEEE T ransactions on Neur al Networks , 22 , 1796–1808. Pearson, K. (1901). On lines and planes of closest fit to systems of points in space. Philosophical Magazine , 2 , 559–572. Roweis, S. T . (1998). EM algorithms for PCA and SPCA. In Advances in Neural Information Pr ocessing Systems 10 (pp. 626–632). Denver , CO. Roweis, S. T ., & Saul, L. K. (2000). Nonlinear dimensionality reduction by locally linear embedding. Science , 290 , 2323–2326. Schapire, R. E. (1990). The strength of weak learnability . Machine Learning , 5 , 197–227. Schmidhuber , J. (2015). Deep learning in neural networks: An overvie w . Neu- ral Networks , 61 , 85–117. Schölkopf, B., Smola, A., & Müller, K.-R. (1998). Nonlinear component anal- ysis as a kernel eigen v alue problem. Neural Computation , 10 , 1299–1319. Shi, J., & Malik, J. (2000). Normalized cuts and image segmentation. IEEE T r ans. P attern Anal. Machine Intell. , 22 , 888–905. Strehl, A., & Ghosh, J. (2003). Cluster ensembles—a knowledge reuse frame- work for combining multiple partitions. Journal of Machine Learning Re- sear ch , 3 , 583–617. T ao, D., T ang, X., Li, X., & W u, X. (2006). Asymmetric bagging and random subspace for support vector machines-based relev ance feedback in image retriev al. IEEE T ransactions on P attern Analysis and Machine Intelligence , 28 , 1088–1099. T eh, Y . W ., Jordan, M. I., Beal, M. J., & Blei, D. M. (2005). Sharing clusters among related groups: Hierarchical dirichlet processes. In Pr oc. Adv . Neur al Inform. Pr ocess. Syst. (pp. 1385–1392). T enenbaum, J. B., De Silva, V ., & Langford, J. C. (2000). A global geomet- ric framework for nonlinear dimensionality reduction. Science , 290 , 2319– 2323. V ega-Pons, S., & Ruiz-Shulcloper , J. (2011). A surve y of clustering ensem- ble algorithms. International Journal of P attern Recognition and Artificial Intelligence , 25 , 337–372. W ang, D. L., & Chen, J. (2017). Supervised speech separation based on deep learning: An overvie w . arXiv preprint , . W ang, Q., Qin, Z., Nie, F ., & Y uan, Y . (2017). Con v olutional 2d lda for nonlin- ear dimensionality reduction. In Pr oceedings of the 26th International J oint Confer ence on Artificial Intelligence (pp. 2929–2935). W ichert, A. (2012). Product quantization for vector retrie val with no error . In ICEIS (1) (pp. 87–92). W ichert, A., & Moreira, C. (2015). On projection based operators in lp space for exact similarity search. Fundamenta Informaticae , 136 , 461–474. W ikipedia (2017). Frequentist probability . https://en.wikipedia.org/ wiki/Frequentist_probability . Xing, E. P ., Jordan, M. I., Russell, S., & Ng, A. (2002). Distance metric learning with application to clustering with side-information. In Advances in Nueral Information Processing Systems 15 (pp. 505–512). V ancouver , British Columbia, Canada. Y an, S., Xu, D., Zhang, B., Zhang, H.-J., Y ang, Q., & Lin, S. (2007). Graph embedding and extensions: a general framew ork for dimensionality reduc- tion. IEEE Tr ansactions on P attern Analysis and Machine Intelligence , 29 , 40–51. Zahn, C. T . (1971). Graph-theoretical methods for detecting and describing gestalt clusters. IEEE T ransactions on Computer s , 100 , 68–86. Zheng, L., Li, T ., & Ding, C. (2010). Hierarchical ensemble clustering. In Pr of. IEEE Int. Conf. Data Min. (pp. 1199–1204). Zhou, Z.-H., & Feng, J. (2017). Deep forest: T owards an alternativ e to deep neural networks. arXiv pr eprint arXiv:1702.08835 , (pp. 1–10). Appendix A. Complexity analysis Theorem 4. The computational and storag e complexities of MBN ar e: O time = O ( d sk V n ) (A.1) O stor age = O (( d s + V ) n + k V + kd s ) (A.2) r espectively at the bottom layer , and ar e: O time = O kV 2 n (A.3) O stor age = O (2 V ( n + k )) (A.4) r espectively at other layers, where d is the dimension of the original feature , s is the sparsity of the data (i.e., the ratio of the non-zer o elements o ver all elements). If MBN is not used for prediction, then MBN needs not to be saved, which further r educes the storag e comple xity to O (( d s + V ) n ) at the bottom layer and O (2 V n ) at other layer s. Pr oof. Due to the length limitation of the paper, we omit the simple proof. Fortunately , as shown in Fig A.15 , the empirical time com- plexity grows with O ( V ) instead of O ( V 2 ). The only explana- tion is that the input data is sparse. Specifically , the multipli- cation of two sparse matrices only considers the element-wise multiplication of two elements that are both nonzero, as a re- sult, when the input data is sparse, one factor V is o ff set by the sparsity factor s . The empirical time and storage complexities with other parameters are consistent with our theoretical analy- sis. W e omit the results here. Note that, our default parameter k 1 = 0 . 5 n makes the time complexity scale squarely with the size of the data set n . T o reduce the computational cost, we usually set k 1 manually to a small v alue irrelev ant to n as what we ha ve done for visualizing the full MNSIT and retrieving the RCV1 documents in Section 5 . Appendix B. Proof of Theorem 2 The optimization objective of k -means clustering can be writ- ten as: max W , h g ( x | W , h ) = max W , h exp − 1 2 σ 2 k x − W T h k 2 2 ! subject to h is a one-hot code (B.1) where W = [ w 1 , . . . , w k ] is the weight matrix whose columns are centroids, h is a vector of hidden variables, and the cov ari- ance matrix of the clustering is σ 2 I with I being the identity matrix and σ → 0 ( Bishop et al. , 2006 ). Substituting g ( x | W , h ) = exp −k x − W T h k 2 2 / 2 σ 2 to Eq. ( 12 ) gets: p ( x |{ W v , h v } V v = 1 ) = Q V v = 1 exp −k x − W T v h v k 2 2 / 2 σ 2 P x 0 Q V v = 1 exp −k x 0 − W T v h v k 2 2 / 2 σ 2 = exp − P V v = 1 k x − W T v h v k 2 2 / 2 σ 2 P x 0 exp − P V v = 1 k x 0 − W T v h v k 2 2 / 2 σ 2 (B.2) 14 50 100 200 400 10 -2 10 -1 10 0 Pa r a m e te r V Time ( H rs) Lay er 1 Lay er 2 Lay er 3 Lay er 4 Lay er 5 Lay er 6 Lay er 7 O( V 2 ) O( V ) 50 100 200 400 10 -1 10 0 10 1 P aram et er V Ti m e (Hrs ) Running t im e on M NIS T MBN O( V 2 ) O( V ) 50 100 200 10 0 10 1 P aram et er V Ti m e (Hrs ) Running t im e of t raini ng eac h l ay er on Reuters news wi re s t ories Lay er 1 Lay er 2 Lay er 3 Lay er 4 Lay er 5 Lay er 6 O( V 2 ) O( V ) 50 100 200 10 1 10 2 Pa r a m e te r V Ti m e (Hrs ) Running t im e on Reut ers news wire s t ories MBN O( V 2 ) O( V ) Running t im e of t raini ng eac h lay er on MNI S T (a) (b) (c) (d) Figure A.15: T ime complexity of MBN with respect to parameter V . where we assume that all e xperts have the same cov ariance ma- trix σ 2 I . Maximizing the likelihood of Eq. ( B.2 ) is equiv alent to the following problem: J PoE = min { W v , h v } V v = 1 − log p ( x |{ W v , h v } V v = 1 ) = min { W v , h v } V v = 1 1 2 σ 2 V X v = 1 k x − W T v h v k 2 2 + log X x 0 exp − 1 2 σ 2 V X v = 1 k x 0 − W T v h v k 2 2 ∝ min { W v , h v } V v = 1 V X v = 1 k x − W T v h v k 2 2 + log X x 0 exp − 1 2 σ 2 V X v = 1 k x 0 − W T v h v k 2 2 2 σ 2 subject to h v is a one-hot code (B.3) Because σ → 0, problem ( B.3 ) can be re written as: J PoE ∝ min { W v , h v } V v = 1 V X v = 1 k x − W T v h v k 2 2 + log max x 0 exp − 1 2 σ 2 V X v = 1 k x 0 − W T v h v k 2 2 2 σ 2 = min { W v , h v } V v = 1 V X v = 1 k x − W T v h v k 2 2 − min x 0 V X v = 1 k x 0 − W T v h v k 2 2 subject to h v is a one-hot code (B.4) Because x 0 can be any possible vector in the data space, we hav e min x 0 P V v = 1 k x 0 − W T v h v k 2 2 = 0. Eventually , the optimization objectiv e of PoE is: J PoE ∝ min { W v , h v } V v = 1 V X v = 1 k x − W T v h v k 2 2 subject to h v is a one-hot code (B.5) which is irrelev ant to the partition function. It is clear that problem ( B.5 ) is the optimization objective of an ensemble of k -means clusterings. When we assign W v by 15 random sampling, then problem ( B.5 ) becomes: J PoE ∝ min { h v } V v = 1 V X v = 1 k x − W T v h v k 2 2 subject to h v is a one-hot code (B.6) which is the building block of MBN. Theorem 2 is pro ved. Appendix C. Proof of Theorem 3 Each layer of MBN maximizes the likelihood of the follow- ing equation: p ( x ) = V Y v = 1 g v ( x ) (C.1) where g v ( x ) is a k -means clustering with the squared error as the similarity metric: g v ( x ) = MN x ; W v h v , σ 2 I (C.2) subject to h v is a one-hot code where MN denotes the multiv ariate normal distrib ution, W v = [ w v , 1 , . . . , w v , k ] is the weight matrix whose columns are cen- troids, I is the identity matrix, and σ → 0. Giv en a data set { x i } n i = 1 . W e assume that { W v } V v = 1 are fixed, and take the neg ati ve logarithm of Eq. ( C.1 ): min {{ h v , i } n i = 1 } V v = 1 V X v = 1 n X i = 1 k x i − W v h v , i k 2 2 , (C.3) subject to h v , i is a one-hot code . If we denote W = [ W 1 , . . . , W V ] and further complement the head and tail of h v , i with multiple zeros, denoted as h 0 v , i , such that Wh 0 v , i = W v h v , i , we can rewrite Eq. ( C.3 ) to the following equiv alent problem: min {{ h v , i } n i = 1 } V v = 1 V X v = 1 n X i = 1 k x i − Wh 0 v , i k 2 2 , (C.4) subject to h v , i is a one-hot code . It is an integer optimization problem that has an integer matrix variable H 0 v = [ h 0 v , 1 , . . . , h 0 v , n ]. Suppose there are totally | H 0 v | possible solutions of H 0 v , denoted as H 0 v , 1 , . . . , H 0 v , | H 0 v | , we first relax Eq. ( C.4 ) to a conv e x optimization problem by construct- ing a con ve x hull ( Boyd & V andenber ghe , 2004 ) on H 0 v : min { µ v , k } | H 0 v | k = 1 V v = 1 V X v = 1 n X i = 1 x i − W | H 0 v | X k = 1 µ v , k h 0 v , k , i 2 2 (C.5) subject to 0 ≤ µ v , k ≤ 1 , | H 0 v | X k = 1 µ v , k = 1 , ∀ v = 1 , . . . , V . Because Eq. ( C.5 ) is a con ve x optimization problem, accord- ing to Jensen’ s inequality , the follo wing problem learns a lo wer bound of Eq. ( C.5 ): min { µ v , k } | H 0 v | k = 1 V v = 1 V n X i = 1 x i − Wh 00 i 2 2 (C.6) subject to 0 ≤ µ v , k ≤ 1 , | H 0 v | X k = 1 µ v , k = 1 , ∀ v = 1 , . . . , V where h 00 i = 1 V P V v = 1 P | H 0 v | k = 1 µ v , k h 0 v , k , i with µ v , k as a variable. Recalling the definition of sparse coding giv en a fix ed dictio- nary W , we observe that Eq. ( C.6 ) is a special form of sparse coding with more strict constraints on the format of sparsity . Therefore, giv en the same dictionary W , each layer of MBN is a distributed sparse coding that is lower bounded by the com- mon ` 1 -norm sparse coding. When we discard the expectation- maximization optimization of each k -means clustering (i.e., dictionary learning) but only preserve the default initialization method – random sampling, Eq. ( C.1 ) becomes the build- ing block of MBN. Given the same dictionary , the ` 1 -norm- regularized sparse coding is a con v ex relaxation of the building block of MBN. Theorem 3 is prov ed. Appendix D. Visualizations pr oduced by intermediate lay- ers 16 Layer 1 Layer 2 Layer 3 Layer 4 Layer 5 Layer 6 Layer 7 Layer 8 Layer 9 0 1 2 3 4 5 6 7 8 9 Figure D.16: V isualizations of MNIST produced by MBN at di ff erent layers. This figure is a supplement to Fig. 9 . 17
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment