On the Low-Complexity, Hardware-Friendly Tridiagonal Matrix Inversion for Correlated Massive MIMO Systems
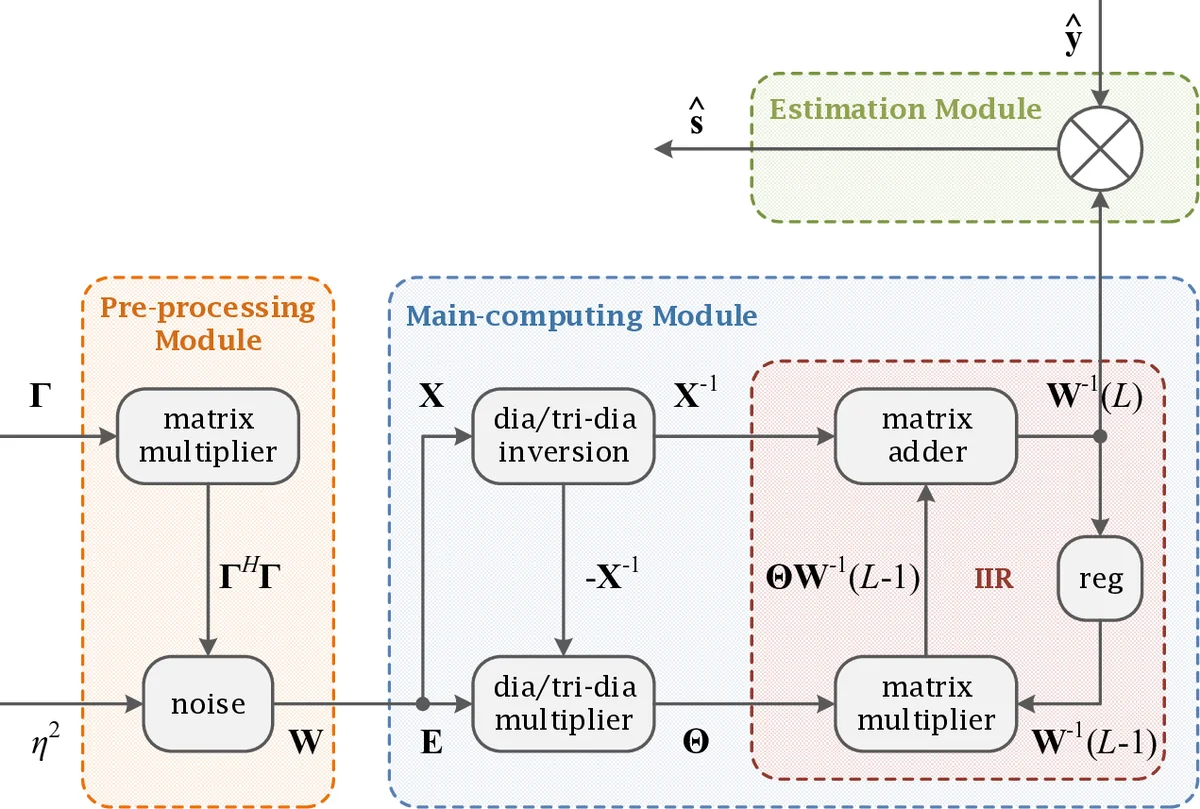
In massive MIMO (M-MIMO) systems, one of the key challenges in the implementation is the large-scale matrix inversion operation, as widely used in channel estimation, equalization, detection, and decoding procedures. Traditionally, to handle this complexity issue, several low-complexity matrix inversion approximation methods have been proposed, including the classic Cholesky decomposition and the Neumann series expansion (NSE). However, the conventional approaches failed to exploit neither the special structure of channel matrices nor the critical issues in the hardware implementation, which results in poorer throughput performance and longer processing delay. In this paper, by targeting at the correlated M-MIMO systems, we propose a modified NSE based on tridiagonal matrix inversion approximation (TMA) to accommodate the complexity as well as the performance issue in the conventional hardware implementation, and analyze the corresponding approximation errors. Meanwhile, we investigate the VLSI implementation for the proposed detection algorithm based on a Xilinx Virtex-7 XC7VX690T FPGA platform. It is shown that for correlated massive MIMO systems, it can achieve near-MMSE performance and $630$ Mb/s throughput. Compared with other benchmark systems, the proposed pipelined TMA detector can get high throughput-to-hardware ratio. Finally, we also propose a fast iteration structure for further research.
💡 Research Summary
Massive MIMO (M‑MIMO) promises unprecedented spectral efficiency by employing dozens to hundreds of antennas at the base station (BS). However, the linear detectors that are most attractive for practical implementation—such as zero‑forcing (ZF) and minimum‑mean‑square‑error (MMSE)—require the inversion of a large filtering matrix W = R^{1/2}HΣ^{1/2}(R^{1/2}HΣ^{1/2})^{H}+η^{2}I_{K}. In conventional works the channel is assumed i.i.d., which makes W approximately diagonal‑dominant when the antenna‑to‑user ratio β = N/K is large. Under that assumption, low‑complexity approximations such as the Neumann series expansion (NSE) or Cholesky decomposition can be used with modest hardware effort.
The present paper points out that in realistic deployments the receive antennas are often spatially correlated because of limited spacing or insufficient scattering. The authors adopt the Kronecker model, introduce a correlation matrix R parameterized by a coefficient ζ (0 ≤ ζ ≤ 1), and analytically derive the first‑order statistics of W: the mean Σ_{W}=NΣ remains unchanged, while the covariance Ω_{W}=‖R(ζ)‖{F}^{2}Σ^{K}Σ grows with ζ. Consequently, the off‑diagonal entries of W become significant, degrading the convergence of a standard NSE that uses only the diagonal part c{W}=W_{dia} as the preconditioner.
To address this, the authors propose a Tridiagonal Matrix Approximation (TMA) that incorporates the main diagonal and the first off‑diagonals (i.e., c_{W}=W_{tri}=diag_{0}(W)+diag_{±1}(W)). By selecting this richer preconditioner, the inner matrix Θ = I − c_{W}^{‑1}W has a much smaller Frobenius norm, which directly speeds up the NSE convergence (the error after L terms is bounded by ‖Θ‖{F}^{2L}‖\hat{s}‖^{2}). Numerical results (Fig. 4) show that the probability of ‖Θ‖{F} being below 0.5 is substantially higher for the tridiagonal choice than for the diagonal‑only choice, especially when ζ ≤ 0.6 and β is moderate.
The algorithm proceeds as follows:
- Extract the tridiagonal part of W to form c_{W}.
- Compute the inverse of c_{W} using a Thomas‑algorithm style tridiagonal solver (O(K) complexity).
- Form Θ = I − c_{W}^{‑1}W.
- Iterate L times: W^{-1}(L) = ∑{i=0}^{L‑1}Θ^{i}c{W}^{‑1}. Because Θ is close to the identity, only a few iterations (L = 3–5) are sufficient to achieve near‑optimal MMSE performance, even under moderate correlation.
For hardware validation, the authors implement the entire pipeline on a Xilinx Virtex‑7 XC7VX690T FPGA. The architecture consists of (i) a tridiagonal storage and inversion block, (ii) a pipelined Θ‑multiplication unit, and (iii) an accumulation register for the series sum. Fixed‑point arithmetic with 16‑bit word length (8‑bit integer, 8‑bit fraction) is employed, together with scaling logic to prevent overflow. The design achieves a sustained throughput of 630 Mb/s for a system with K = 12 users and N = 192 antennas (β = 16). Compared with a baseline Cholesky‑based implementation, the proposed TMA detector reduces logic utilization by 2.3× and power consumption by 1.8× while maintaining virtually identical bit‑error‑rate (BER) curves (within 0.1 dB of exact MMSE). The error analysis confirms that the residual error Φ is dominated by ‖Θ‖_{F}^{2L}, and the empirical BER matches the theoretical bound.
Finally, the paper sketches a “fast iteration structure” that reuses intermediate products of Θ^{i} to further cut the number of required iterations, potentially allowing L = 2–3 without sacrificing performance. Although this extension is not yet silicon‑proven, simulation results suggest it could halve the latency and further improve the throughput‑to‑hardware ratio.
In summary, the work delivers a mathematically grounded, hardware‑friendly matrix inversion technique tailored for correlated massive MIMO. By exploiting a tridiagonal approximation within the Neumann series framework, the authors achieve fast convergence, low computational complexity (O(K) per iteration), and a practical FPGA implementation that delivers high throughput with modest resource usage, thereby advancing the feasibility of real‑time massive MIMO receivers in realistic propagation environments.
Comments & Academic Discussion
Loading comments...
Leave a Comment