One Single Deep Bidirectional LSTM Network for Word Sense Disambiguation of Text Data
Due to recent technical and scientific advances, we have a wealth of information hidden in unstructured text data such as offline/online narratives, research articles, and clinical reports. To mine these data properly, attributable to their innate ambiguity, a Word Sense Disambiguation (WSD) algorithm can avoid numbers of difficulties in Natural Language Processing (NLP) pipeline. However, considering a large number of ambiguous words in one language or technical domain, we may encounter limiting constraints for proper deployment of existing WSD models. This paper attempts to address the problem of one-classifier-per-one-word WSD algorithms by proposing a single Bidirectional Long Short-Term Memory (BLSTM) network which by considering senses and context sequences works on all ambiguous words collectively. Evaluated on SensEval-3 benchmark, we show the result of our model is comparable with top-performing WSD algorithms. We also discuss how applying additional modifications alleviates the model fault and the need for more training data.
💡 Research Summary
The paper addresses a fundamental bottleneck in Word Sense Disambiguation (WSD): the need to train a separate classifier for each ambiguous word. Existing supervised WSD systems typically allocate one model per target word, which leads to a proliferation of parameters, high training costs, and difficulty scaling to languages or domains with many polysemous terms. To overcome this limitation, the authors propose a single deep neural architecture—a Bidirectional Long Short‑Term Memory (BLSTM) network—that can disambiguate all ambiguous words in a language jointly.
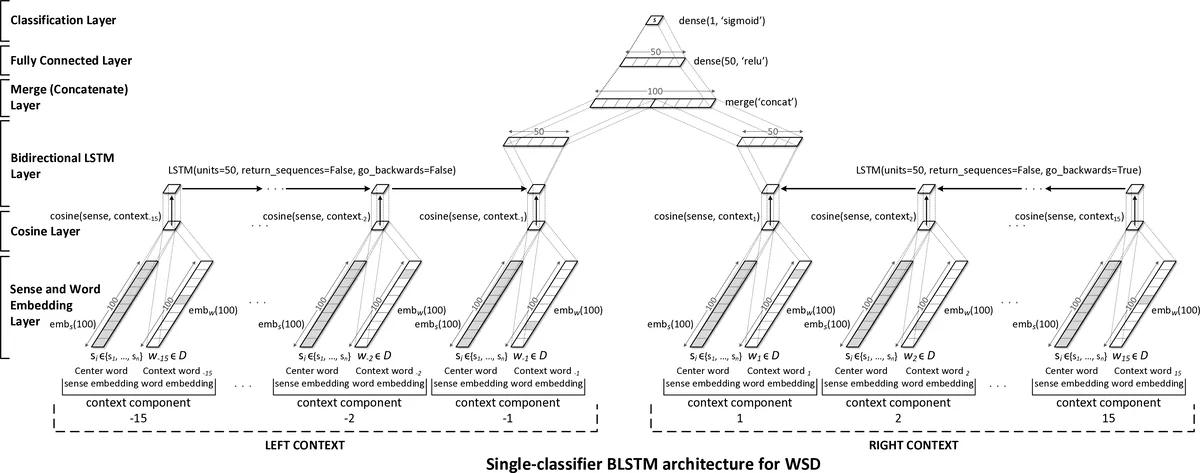
The core idea is to represent each candidate sense with a learnable sense embedding and each surrounding word with a pre‑trained word embedding (GloVe). For a given target word, the model computes the cosine similarity between the sense embedding and each context word embedding, producing a sequence of similarity scores that captures how well the sense aligns with the left and right context. This similarity sequence is fed into a BLSTM that processes it in both forward and backward directions, allowing the network to capture patterns that distinguish the correct sense from incorrect ones. The BLSTM outputs are concatenated, passed through a ReLU‑activated fully‑connected layer, and finally through a sigmoid unit that yields a binary score ˆy for the examined sense. During training, the correct sense receives a target of 1.0 and all other senses 0.0, and the loss is mean‑squared error (MSE), which the authors found to work better than binary cross‑entropy for their final argmax decision rule.
The architecture consists of six layers: (1) sense and word embedding lookup, (2) cosine similarity computation, (3) BLSTM, (4) concatenation (merge) layer, (5) fully‑connected layer, and (6) sigmoid classifier. Unlike prior neural WSD models that allocate a separate softmax layer (and thus separate weight matrices) per ambiguous word, this design shares all parameters across all senses, dramatically reducing model size and enabling statistical sharing among different words. Regularization is achieved through dropout applied to embeddings (20 %), BLSTM outputs (50 %), and the fully‑connected layer (50 %). Additionally, word‑dropout (20 %) randomly replaces context words with a special token during training to reduce dependence on any single token.
Hyper‑parameter tuning on a 5 % validation split of the training data identified the following optimal settings: context window of 15 tokens to the left and right, embedding dimension of 100, BLSTM hidden size of 2 × 50 units, and the dropout rates mentioned above. The model is trained end‑to‑end with RMSprop, updating both the embedding matrices and the BLSTM weights.
Experiments are conducted on the SemEval‑3 lexical sample task (task 5), which provides annotated instances for 57 target words (20 nouns, 32 verbs, 5 adjectives) with an average of 6.47 senses per word. After lower‑casing and removing numbers, the vocabulary size is 29,044. Fixed‑size contexts are obtained by padding or truncating as needed.
Results show that the single BLSTM model attains an F‑measure that places it among the top five supervised systems submitted to the SemEval‑3 competition, despite using only one classifier for all words. This demonstrates that parameter sharing does not sacrifice accuracy and that the cosine‑similarity‑based sequence captures sufficient discriminative information. The authors also note that their approach eliminates the need to train 57 separate models, simplifying deployment and maintenance.
However, several limitations are acknowledged. First, sense embeddings are initialized randomly and learned solely from the WSD training data, which can lead to unstable convergence and may not scale well to larger sense inventories. Second, relying exclusively on cosine similarity between sense and word vectors may overlook richer syntactic or semantic cues that could be captured by more expressive contextual encoders. Third, evaluation is limited to a single benchmark; cross‑domain generalization remains untested.
Future work includes (i) initializing sense embeddings with retrofitted or sense‑specific vectors to provide a better starting point, (ii) replacing the BLSTM with Transformer‑based encoders to capture longer‑range dependencies, and (iii) exploring meta‑learning or multi‑task learning strategies to reduce the amount of labeled data required. The authors also suggest extending the framework to specialized domains such as biomedicine, where large, domain‑specific sense inventories exist.
In summary, the paper presents a novel, unified BLSTM architecture for WSD that jointly handles all ambiguous words, achieving competitive performance while drastically reducing model complexity. This contribution offers a practical pathway toward scalable, maintainable sense‑disambiguation systems in real‑world NLP pipelines.
Comments & Academic Discussion
Loading comments...
Leave a Comment