Sequence-to-Sequence ASR Optimization via Reinforcement Learning
Despite the success of sequence-to-sequence approaches in automatic speech recognition (ASR) systems, the models still suffer from several problems, mainly due to the mismatch between the training and inference conditions. In the sequence-to-sequence…
Authors: Andros Tj, ra, Sakriani Sakti
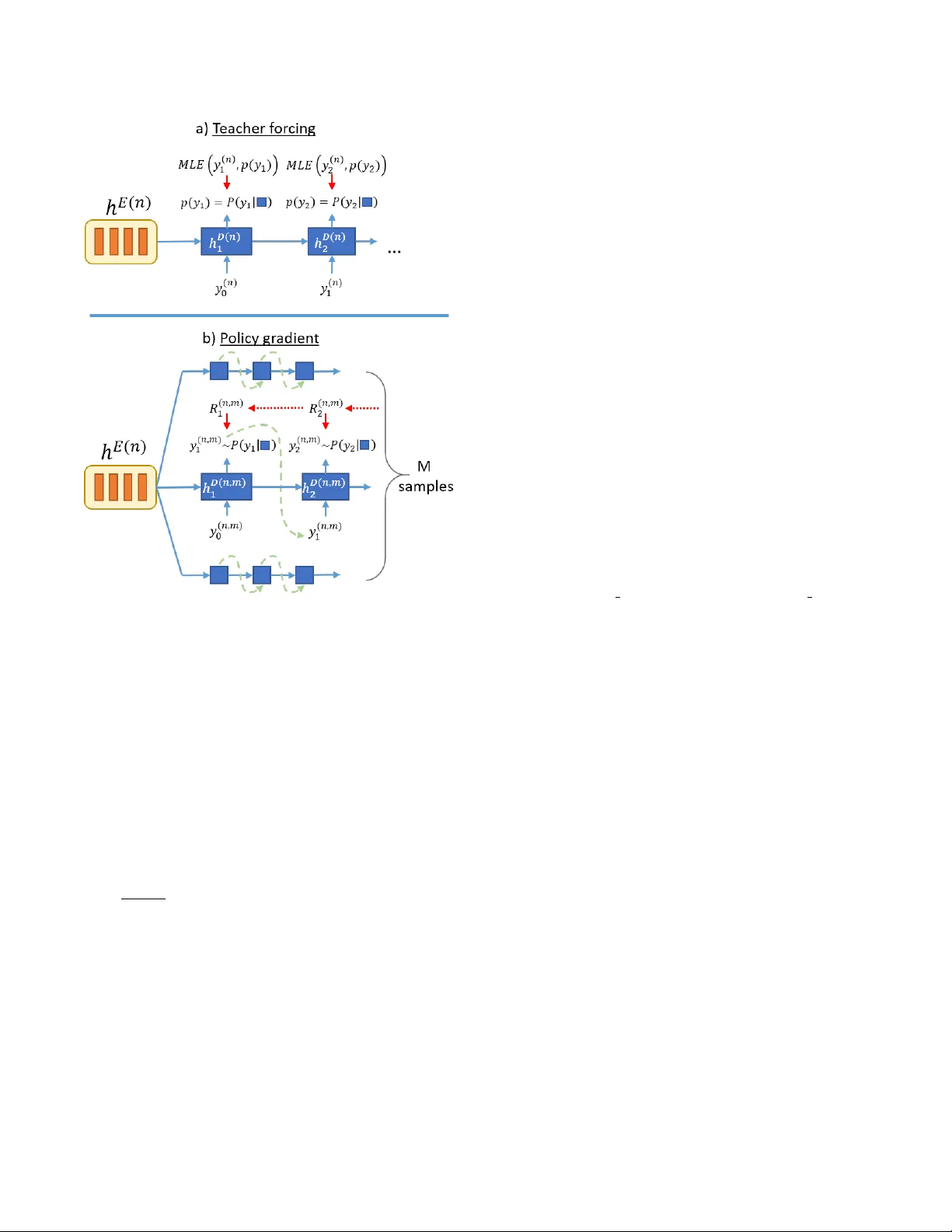
SEQUENCE-T O-SEQUENCE ASR OPTIMIZA TION VIA REINFORCEMENT LEARNING Andr os Tjandr a 1 , Sakriani Sakti 1,2 , Satoshi Nakamura 1,2 1 Graduate School of Information Science, Nara Institute of Science and T echnology , Japan 2 RIKEN, Center for Adv anced Intelligence Project AIP , Japan { andros.tjandra.ai6, ssakti, s-nakamura } @is.naist.jp ABSTRA CT Despite the success of sequence-to-sequence approaches in auto- matic speech recognition (ASR) systems, the models still suffer from sev eral problems, mainly due to the mismatch between the train- ing and inference conditions. In the sequence-to-sequence archi- tecture, the model is trained to predict the grapheme of the cur- rent time-step giv en the input of speech signal and the ground-truth grapheme history of the previous time-steps. Howe ver , it remains unclear how well the model approximates real-world speech dur- ing inference. Thus, generating the whole transcription from scratch based on previous predictions is complicated and errors can propa- gate over time. Furthermore, the model is optimized to maximize the likelihood of training data instead of error rate ev aluation met- rics that actually quantify recognition quality . This paper presents an alternativ e strategy for training sequence-to-sequence ASR mod- els by adopting the idea of reinforcement learning (RL). Unlike the standard training scheme with maximum likelihood estimation, our proposed approach utilizes the policy gradient algorithm. W e can (1) sample the whole transcription based on the model’ s prediction in the training process and (2) directly optimize the model with negati ve Lev enshtein distance as the reward. Experimental results demon- strate that we significantly improved the performance compared to a model trained only with maximum likelihood estimation. Index T erms — End-to-end speech recognition, reinforcement learning, policy gradient optimization 1. INTRODUCTION Sequence-to-sequence models have been recently shown to be very effecti ve for many tasks such as machine translation [1, 2], image captioning [3, 4], and speech recognition [5]. W ith these models, we are able to learn a direct mapping between the v ariable-length of the source and the target sequences that are often not known apriori using only a single neural network architecture. This way , many complicated hand-engineered models can also be simplified by letting DNNs find their way to map from input to output spaces [5, 6, 7]. Therefore, we can eliminate the need to construct separate components, i.e., a feature extractor , an acoustic model, a lexicon model, or a language model, as is commonly required in con ven- tional ASR systems such as hidden Mark ov model-Gaussian mixture model (HMM-GMM)-based or hybrid HMM-DNN. A generic sequence-to-sequence model commonly consists of three modules: (1) an encoder module for representing source data information, (2) a decoder module for generating transcription out- put and (3) an attention module for extracting related information from an encoder representation based on the current decoder state. A decoding scheme was done based on a left-to-right decoding pro- cedure. In the training stage, gi ven the current input of the speech signal, the decoder produces a grapheme in the current time-step with maximal probability conditioned on the ground-truth of the grapheme history in the previous time-steps. This training scheme is usually referred as a teacher-forcing method [8]. Howe ver , in the inference stage, since the ground-truth of the transcription is not known, the model must produce the grapheme in the current time- step based on an approximation of the correct grapheme in previous time-steps. Therefore, an incorrect decision in an earlier time-step may propagate through subsequent time-steps. Another drawback is the differences in the use of objective func- tions between training and ev aluation schemes. In the training stage, the model is mostly optimized by combining the teacher-forcing ap- proach with the maximum likelihood estimation (MLE) for each frame. On the other hand, the recognition accuracy is ev aluated by calculating the minimum string edit-distance (Lev enshtein distance) between the correct transcription and the recognition output. Such differences may result in suboptimal performance [9]. Optimizing the model parameter with the appropriate objecti ve function is cru- cial to achieve good model performance, or in other words, direct optimization with respect to the evaluation metrics might be neces- sary . In this paper , we propose an alternative strategy for training a sequence-to-sequence ASR by adopting an idea from RL. Specifi- cally , we utilize a policy gradient algorithm (REINFORCE) [10] to simultaneously alleviate both of the abo ve problems. By treating our decoder as a policy network or an agent, we are able to (1) sample the whole transcription based on model’ s prediction in the training pro- cess and (2) directly optimize the model with ne gativ e Levenshtein distance as the re ward. Our model thus integrates the po wer of the sequence-to-sequence approach to learn the mapping between the speech signal and the text transcription based on the strength of re- inforcement learning to optimize the model with ASR performance metric directly . 2. SEQUENCE-TO-SEQ UENCE ASR Sequence-to-sequence model is a type of neural network model that directly models conditional probability P ( y | x ) , where x = [ x 1 , ..., x S ] is the source sequence with length S , and y = [ y 1 , ..., y T ] is the target sequence with length T . Most common input x is a se- quence of feature vectors like Mel-spectral filterbank and/or MFCC. Therefore, x ∈ R S × F where F is the number of features and S is the total frame length for an utterance. Output y , which is a speech transcription sequence, can be either a phoneme or a grapheme (character) sequence. Figure 1 sho ws the ov erall structure of the attention-based encoder-decoder model that consists of encoder, decoder, and at- tention modules. The encoder task processes input sequence x and outputs representati ve information h E = [ h E 1 , ..., h E S ] for the Fig. 1 . Attention-based encoder -decoder architecture. decoder . The attention module is an extension scheme that helps the decoder find relev ant information on the encoder side based on current decoder hidden states [2]. An attention module produces context information c t at time t based on the encoder and decoder hidden states with following equation: c t = S X s =1 a t ( s ) ∗ h E s (1) a t ( s ) = Align ( h E s , h D t ) = exp( Score ( h E s , h D t )) P S s =1 exp( Score ( h E s , h D t )) . (2) There are sev eral variations for the score functions: Score ( h E s , h D t ) = h h E s , h D t i , dot product h E | s W s h D t , bilinear V | s tanh( W s [ h E s , h D t ]) , MLP (3) where Score : ( R M × R N ) → R , M is the number of hidden units for the encoder and N is the number of hidden units for the decoder . Finally , the decoder task, which predicts the target sequence proba- bility at time t based on the pre vious output and conte xt information c t can be formulated: log P ( y | x ; θ ) = T X t =1 log P ( y t | h D t , c t ; θ ) (4) where h D t is the last decoder layer that contains summarized infor- mation from all previous input y 1 − ( E D ( y 1: t , y ( n ) ) − | y ( n ) | ) if t = 1 where E D ( · , · ) is the edit-distance function between two transcrip- tions, y 1: t is the substring of y from index 1 to t , and | y ( n ) | is the ground-truth length. Intuiti vely , we try to calculate whether the cur- rent new transcription at time- t decreases the edit-distance compared to previous transcription, and we multiply it by -1 for a positive re- ward if our new edit-distance at time t is smaller than the pre vious t − 1 edit distance. 4. EXPERIMENT 4.1. Speech Dataset and Featur e Extraction In this study , we inv estigated the performance of our proposed method on WSJ [15] with identical definitions of training, develop- ment, and test sets as the Kaldi s5 recipe [16]. W e separated WSJ into two experiments using WSJ-SI84 only and WSJ-SI284 data for training. W e used dev 93 for our validation set and ev al 92 for our test set. W e used the character sequence as our decoder target and followed the preprocessing steps proposed by [17]. The text from all the utterances was mapped into a 32-character set: 26 (a-z) let- ters of the alphabet, apostrophes, periods, dashes, space, noise, and “eos”. In all experiments, we extracted the 40 dims + ∆ + ∆∆ (total 120 dimensions) log Mel-spectrogram features from our speech and normalized ev ery dimension into zero mean and unit variance. 4.2. Model Architecture On the encoder side, we fed our input features into a linear layer with 512 hidden units followed by the LeakyReLU [18] activ ation function. W e used three bidirectional LSTMs (Bi-LSTM) for our encoder with 256 hidden units for each LSTM (total 512 hidden units for Bi-LSTM). T o improv e the running time and reduce the memory consumption, we used hierarchical subsampling [19, 5] on the top two Bi-LSTM layers and reduced the number of encoder time-steps by a factor of 4. On the decoder side, we used a 128-dimensional embedding ma- trix to transform the input graphemes into a continuous vector , fol- lowed by one-unidirectional LSTMs with 512 hidden units. For our scorer function inside the attention module, we used MLP scorers (Eq. 3) with 256 hidden units and Adam [20] optimizer with a learn- ing rate of 5 e − 4 . In the training phase, we started to train our model with MLE (Eq. 8) until conv ergence. After that, we continued training by adding an RL-based objective until our model stopped improving. For our RL-based objectiv e, we tried four scenarios using differ- ent discount factors γ = { 0 , 0 . 5 , 0 . 95 } and only global reward R (Eq. 5). T o calculate the gradient based on Eq. 7, we sampled up to M = 15 sequences for each utterance. In the decoding phase, we extracted our transcription with a beam search strategy (beam size = 5) and normalized log-likelihood log P ( Y | X ; θ ) by dividing it by the transcription length to prevent the decoder from fav oring shorter transcriptions. W e did not use any language model or lexicon dictionary in this w ork. All of our models were implemented on the PyT orch frame work 1 . 5. RESUL TS AND DISCUSSION T able 1 . Character error rate (CER) result from baseline and pro- posed models on WSJ-SI84 and WSJ-SI284 datasets. All results were produced without a language model or lexicon dictionary . Models Results WSJ-SI84 CER (%) MLE CTC [21] 20.34 % Att Enc-Dec Content [21] 20.06 % Att Enc-Dec Location [21] 17.01 % Joint CTC+Att (MTL) [21] 14.53 % Att Enc-Dec (ours) 17.68 % MLE + RL Att Enc-Dec + RL (final rew ard R ) 15.46 % Att Enc-Dec + RL (time rew ard R t , γ = 0 ) 15.99 % Att Enc-Dec + RL (time rew ard R t , γ = 0 . 5 ) 15.05 % Att Enc-Dec + RL (time rew ard R t , γ = 0 . 95 ) 13.90 % WSJ-SI284 CER (%) MLE CTC [21] 8.97% Att Enc-Dec Content [21] 11.08% Att Enc-Dec Location [21] 8.17% Joint CTC+Att (MTL) [21] 7.36% Att Enc-Dec (ours) 7.69% MLE+RL Att Enc-Dec + RL (final rew ard R ) 7.26 % Att Enc-Dec + RL (time rew ard R t , γ = 0 ) 6.64 % Att Enc-Dec + RL (time rew ard R t , γ = 0 . 5 ) 6.37 % Att Enc-Dec + RL (time rew ard R t , γ = 0 . 95 ) 6.10 % T able 1 shows all the experiment results from the WSJ-SI84 and WSJ-SI284 datasets. W e compared our results with several pub- lished models such as CTC, Attention Encoder-Decoder and Joint CTC-Attention model trained with MLE objective. W e also created our own baseline model with Attention Encoder-Decoder and trained only with MLE objectiv e. The difference between our Attention Encoder-Decoder (“ Att Enc-Dec (ours)”) is our decoder calculate the attention probability and context vector based on current hidden state instead of previous hidden state. W e also reused the previous context v ector by concatenating it with the input embedding vector . W e explore several configurations by only using final reward R and time distributed re ward R t with different γ = [0 , 0 . 5 , 0 . 95] val- ues. Our result shows that with by combining the teacher forcing with polic y gradient approach improv ed our model performance sig- 1 PyT orch https://github.com/pytorch/pytorch/ nificantly compared to a system just trained with the teacher forc- ing method only . Furthermore, we also found that discount factor γ = 0 . 95 gi ve the best performance on both datasets. 6. RELA TED WORK Reinforcement learning is a subfield of machine learning that creates an agent that interacts with its en vironment and learn how to maxi- mize the rewards using some feedback signal. Many reinforcement learning applications exist, including building an agent that can learn how to play a game without any e xplicit kno wledge [22, 23], control tasks in robotics [24], and dialogue system agents [25, 26]. Not only limited to these areas, reinforcement learning has also been adopted for improving sequence-based neural network models. Ranzato et al. [27] proposed an idea that combined REINFORCE with an MLE objecti ve for training called MIXER. In the early stage of training, the first s steps are trained with MLE and the remain- ing T − s steps with REINFORCE. They decrease s as the training progress over time. By using REINFORCE, they trained the model using non-differentiable task-related rewards (e.g., BLEU for ma- chine translation). In this paper , we did not need to deal with any scheduling or mix any sampling with teacher forcing ground-truth. Furthermore, MIXER did not sample multiple sequences based on the REINFORCE Monte Carlo approximation and they were not in- vestigate MIXER on an ASR system. In a machine translation task, Shen et al. [12] impro ved the neu- ral machine translation (NMT) model using Minimum Risk T raining (MR T). Google NMT [9] system combined MLE and MR T objec- tiv es to achie ve better results. For ASR task, Shanon et al. [28] performed WER optimization by sampling paths from the lattices used during sMBR training which might be similar to REINFORCE algorithm. But, the work was only applied on CTC-based model. From the probabilistic perspectiv e, MR T formulation resembles the expected rew ard formulation used in reinforcement learning. Here, MR T formulation equally distribute the sentence-lev el loss into all of the time-steps in the sample. In contrast, we applied the RL strategy to an ASR task and found that using final reward R is not an effecti ve method for train- ing our system because the loss diver ged and produced a worse re- sult. Therefore, we proposed a temporal structure and applied time- distributed reward R t . Our results demonstrate that we impro ved our performance significantly compared to the baseline system. 7. CONCLUSION W e introduced an alternati ve strategy for training sequence-to- sequence ASR models by integrating the idea from reinforcement learning. Our proposed method integrates the power of sequence- to-sequence approaches to learn the mapping between speech signal and text transcription based on the strength of reinforcement learning to optimize the model with ASR performance metric directly . W e also explored sev eral different scenarios for training with RL-based objectiv e. Our results show that by combining RL-based objecti ve together with MLE objective, we significantly improved our model performance compared to the model just trained with the MLE ob- jectiv e. The best system achiev ed up to 6.10% CER in WSJ-SI284 using time-distrib uted re ward settings and discount factor γ = 0 . 95 . 8. A CKNO WLEDGEMENTS Part of this work was supported by JSPS KAKENHI Grant Numbers JP17H06101 and JP17K00237. 9. REFERENCES [1] Ilya Sutskev er , Oriol V inyals, and Quoc V Le, “Sequence to sequence learning with neural networks, ” in Advances in neu- ral information pr ocessing systems , 2014, pp. 3104–3112. [2] Dzmitry Bahdanau, K yunghyun Cho, and Y oshua Bengio, “Neural machine translation by jointly learning to align and translate, ” arXiv preprint , 2014. [3] Kelvin Xu, Jimmy Ba, Ryan Kiros, Kyunghyun Cho, Aaron Courville, Ruslan Salakhudinov , Rich Zemel, and Y oshua Ben- gio, “Show , attend and tell: Neural image caption generation with visual attention, ” in International Confer ence on Machine Learning , 2015, pp. 2048–2057. [4] Oriol V inyals, Alexander T oshev , Samy Bengio, and Dumitru Erhan, “Show and tell: A neural image caption generator, ” in Pr oceedings of the IEEE confer ence on computer vision and pattern reco gnition , 2015, pp. 3156–3164. [5] Dzmitry Bahdanau, Jan Choro wski, Dmitriy Serdyuk, Phile- mon Brakel, and Y oshua Bengio, “End-to-end attention-based large vocabulary speech recognition, ” in Proc. ICASSP , 2016 . IEEE, 2016, pp. 4945–4949. [6] William Chan, Navdeep Jaitly , Quoc Le, and Oriol V inyals, “Listen, attend and spell: A neural network for large vocab u- lary conv ersational speech recognition, ” in Acoustics, Speech and Signal Pr ocessing (ICASSP), 2016 IEEE International Confer ence on . IEEE, 2016, pp. 4960–4964. [7] Andros Tjandra, Sakriani Sakti, and Satoshi Nakamura, “ Attention-based wa v2text with feature transfer learning, ” in 2017 IEEE Automatic Speech Recognition and Understand- ing W orkshop, ASR U 2017, Okinawa, J apan, December 16-20, 2017 , 2017, pp. 309–315. [8] Ronald J Williams and David Zipser, “ A learning algorithm for continually running fully recurrent neural networks, ” Neural computation , vol. 1, no. 2, pp. 270–280, 1989. [9] Y onghui W u, Mike Schuster , Zhifeng Chen, Quoc V Le, Mo- hammad Norouzi, W olfgang Macherey , Maxim Krikun, Y uan Cao, Qin Gao, Klaus Macherey , et al., “Google’ s neural ma- chine translation system: Bridging the gap between human and machine translation, ” arXiv preprint , 2016. [10] Ronald J Williams, “Simple statistical gradient-following al- gorithms for connectionist reinforcement learning, ” Machine learning , vol. 8, no. 3-4, pp. 229–256, 1992. [11] Richard S. Sutton and Andrew G. Barto, Intr oduction to Re- infor cement Learning , MIT Press, Cambridge, MA, USA, 1st edition, 1998. [12] Shiqi Shen, Y ong Cheng, Zhongjun He, W ei He, Hua W u, Maosong Sun, and Y ang Liu, “Minimum risk training for neu- ral machine translation, ” in Pr oceedings of the 54th Annual Meeting of the Association for Computational Linguistics, ACL 2016, August 7-12, 2016, Berlin, Germany , V olume 1: Long P apers , 2016. [13] Evan Greensmith, Peter L Bartlett, and Jonathan Baxter, “V ari- ance reduction techniques for gradient estimates in reinforce- ment learning, ” Journal of Machine Learning Researc h , v ol. 5, no. Nov , pp. 1471–1530, 2004. [14] Andriy Mnih and Karol Gregor , “Neural variational inference and learning in belief networks, ” in Pr oceedings of the 31st International Confer ence on International Conference on Ma- chine Learning-V olume 32 . JMLR. org, 2014, pp. II–1791. [15] Douglas B. Paul and Janet M. Baker , “The design for the Wall Street Journal-based CSR corpus, ” in Pr oceedings of the W ork- shop on Speech and Natural Language , Stroudsburg, P A, USA, 1992, HL T ’91, pp. 357–362, Association for Computational Linguistics. [16] Daniel Pove y , Arnab Ghoshal, Gilles Boulianne, Lukas Bur- get, Ondrej Glembek, Nagendra Goel, Mirk o Hannemann, Petr Motlicek, Y anmin Qian, Petr Schwarz, Jan Silovsk y , Georg Stemmer , and Karel V esely , “The Kaldi speech recognition toolkit, ” in IEEE 2011 W orkshop on Automatic Speech Recog- nition and Understanding . Dec. 2011, IEEE Signal Processing Society , IEEE Catalog No.: CFP11SR W -USB. [17] A wni Y Hannun, Andre w L Maas, Daniel Jurafsky , and An- drew Y Ng, “First-pass large vocab ulary continuous speech recognition using bi-directional recurrent DNNs, ” arXiv pr eprint arXiv:1408.2873 , 2014. [18] Bing Xu, Naiyan W ang, Tianqi Chen, and Mu Li, “Empirical ev aluation of rectified activ ations in con volutional network, ” arXiv preprint arXiv:1505.00853 , 2015. [19] Alex Graves et al., Supervised sequence labelling with recur - r ent neural networks , vol. 385, Springer , 2012. [20] Diederik Kingma and Jimmy Ba, “ Adam: A method for stochastic optimization, ” arXiv preprint , 2014. [21] Suyoun Kim, T akaaki Hori, and Shinji W atanabe, “Joint CTC- attention based end-to-end speech recognition using multi- task learning, ” in Acoustics, Speech and Signal pr ocess- ing (ICASSP), 2017 IEEE International Conference on . IEEE, 2017. [22] V olodymyr Mnih, K oray Kavukcuoglu, Da vid Silver , An- drei A. Rusu, Joel V eness, Marc G. Bellemare, Alex Graves, Martin Riedmiller , Andreas K. Fidjeland, Geor g Ostro- vski, Stig Petersen, Charles Beattie, Amir Sadik, Ioannis Antonoglou, Helen King, Dharshan Kumaran, Daan Wier - stra, Shane Legg, and Demis Hassabis, “Human-lev el control through deep reinforcement learning, ” Nature , vol. 518, no. 7540, pp. 529–533, 02 2015. [23] David Silver , Aja Huang, Chris J Maddison, Arthur Guez, Lau- rent Sifre, George V an Den Driessche, Julian Schrittwieser, Ioannis Antonoglou, V eda Panneershelv am, Marc Lanctot, et al., “Mastering the game of go with deep neural networks and tree search, ” Natur e , vol. 529, no. 7587, pp. 484–489, 2016. [24] Jens K ober and Jan Peters, “Reinforcement learning in robotics: A surve y , ” in Reinforcement Learning , pp. 579–610. Springer , 2012. [25] Satinder P Singh, Michael J K earns, Diane J Litman, and Mar - ilyn A W alker , “Reinforcement learning for spoken dialogue systems, ” in Advances in Neural Information Processing Sys- tems , 2000, pp. 956–962. [26] Jiwei Li, Will Monroe, Alan Ritter , Michel Galley , Jianfeng Gao, and Dan Jurafsky , “Deep reinforcement learning for dia- logue generation, ” arXiv preprint , 2016. [27] Marc Aurelio Ranzato, Sumit Chopra, Michael Auli, and W oj- ciech Zaremba, “Sequence lev el training with recurrent neural networks, ” arXiv pr eprint arXiv:1511.06732 , 2015. [28] Matt Shannon, “Optimizing expected word error rate via sampling for speech recognition, ” arXiv pr eprint arXiv:1706.02776 , 2017.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment