Deep Feed-forward Sequential Memory Networks for Speech Synthesis
The Bidirectional LSTM (BLSTM) RNN based speech synthesis system is among the best parametric Text-to-Speech (TTS) systems in terms of the naturalness of generated speech, especially the naturalness in prosody. However, the model complexity and inference cost of BLSTM prevents its usage in many runtime applications. Meanwhile, Deep Feed-forward Sequential Memory Networks (DFSMN) has shown its consistent out-performance over BLSTM in both word error rate (WER) and the runtime computation cost in speech recognition tasks. Since speech synthesis also requires to model long-term dependencies compared to speech recognition, in this paper, we investigate the Deep-FSMN (DFSMN) in speech synthesis. Both objective and subjective experiments show that, compared with BLSTM TTS method, the DFSMN system can generate synthesized speech with comparable speech quality while drastically reduce model complexity and speech generation time.
💡 Research Summary
The paper investigates the use of Deep Feed‑forward Sequential Memory Networks (DFSMN) as the acoustic modeling back‑end for statistical parametric text‑to‑speech (TTS), aiming to replace the widely adopted Bidirectional LSTM (BLSTM) architecture. While BLSTM‑based TTS systems achieve state‑of‑the‑art naturalness, especially in prosody, they suffer from high model complexity and costly inference, which limits their deployment in real‑time or resource‑constrained applications. DFSMN, originally proposed for speech recognition, offers a feed‑forward structure augmented with memory blocks that perform weighted sums over past and future frames, effectively modeling long‑range dependencies without recurrent connections. This FIR‑like design can be trained with standard back‑propagation, avoiding the vanishing‑gradient and computational overhead associated with BPTT.
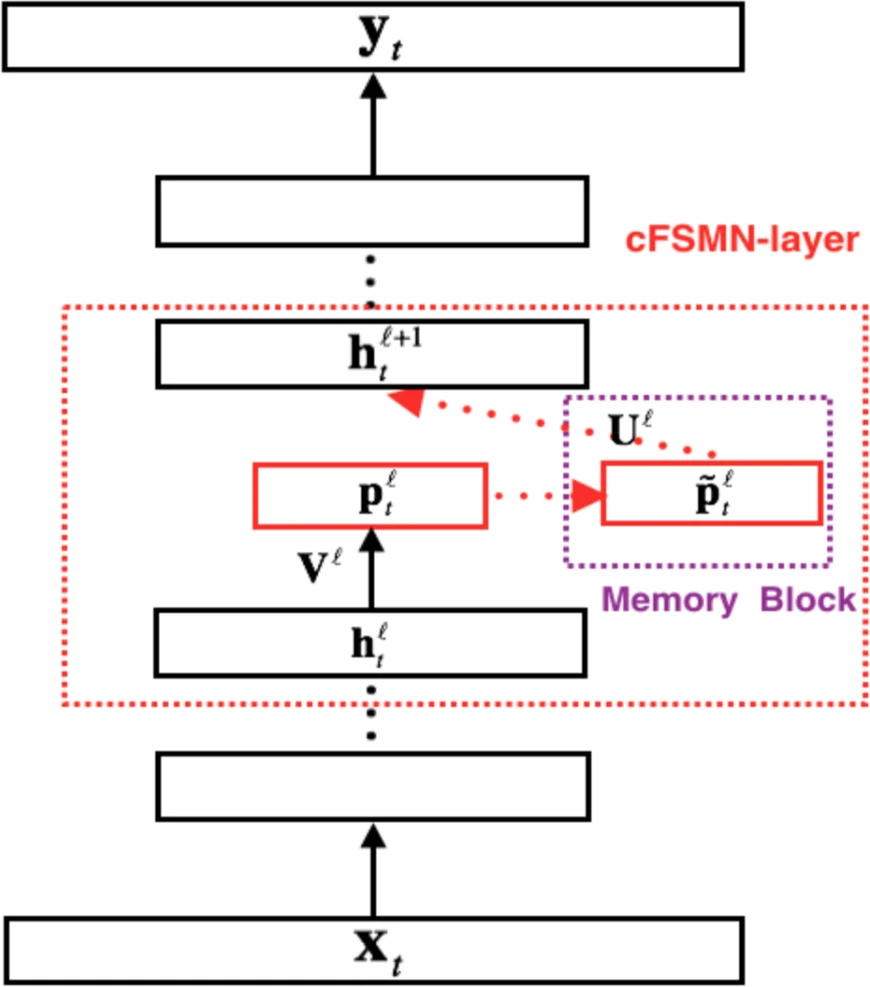
The authors first describe the compact FSMN (cFSMN) variant, which reduces parameters via low‑rank projection, and then extend it to a deep architecture (DFSMN) by stacking multiple cFSMN layers and inserting skip connections between successive memory blocks. Skip connections facilitate gradient flow in deep networks and implicitly enlarge the temporal context seen by higher layers. Two hyper‑parameters govern the temporal receptive field: the “order” (how many frames are looked back and ahead) and the “stride” (the step size between frames). By adjusting these, the effective context window can be scaled from a few frames up to several thousand.
The experimental setup uses a Mandarin male speaker corpus of 83 hours (38,600 utterances) for training and 3 hours (1,400 utterances) for validation. Speech is analyzed with the WORLD vocoder, extracting 60‑dimensional mel‑cepstral coefficients, 3‑dimensional log‑F0 (static, delta, acceleration), 11‑dimensional band‑aperiodicity (BAP), and a voiced/unvoiced flag. Linguistic input consists of 754‑dimensional one‑hot and numeric features derived from text normalization and lexical analysis. All features are normalized to zero mean and unit variance before training.
The BLSTM baseline comprises a 2048‑unit fully‑connected layer followed by three BLSTM layers, each with 2048 cells (1024 per direction), trained with BPTT on 40 parallel streams. DFSMN models consist of DFSMN layers (2048 hidden units, 512 projection units) interleaved with fully‑connected layers (2048 units). Training employs BMUF on two GPUs, with multi‑task frame‑level mean‑squared error (MSE) loss for the three acoustic streams plus the V/UV decision. DFSMN models are optimized with SGD (batch size 512, initial LR 5e‑7, decay factor 0.1 on plateau).
A systematic exploration varies the number of DFSMN layers (depth) and the memory order/stride. Table 1 reports objective metrics: mel‑cepstral distortion (MCD), F0 RMSE, U/V error, BAP distortion, total MSE, model size, and FLOPS. As depth and order increase, all objective errors consistently decrease. The most competitive DFSMN configuration (system H: 10 + 2 layers, order = 40, stride = 2) achieves lower overall MSE than the BLSTM while halving the model size (≈7 MB vs 6.9 MB for BLSTM) and reducing FLOPS from 29 G to 28.9 G, resulting in roughly three‑fold faster synthesis.
Subjective evaluation uses a crowdsourced MOS test with 40 native Mandarin listeners rating 20 utterances per system. System E (6 + 2 layers, order = 10, stride = 2) attains the highest MOS of 4.23, comparable to the BLSTM baseline. MOS improves with increasing depth and order up to system E, after which further scaling yields diminishing returns and slight variability, indicating that a context window of about 600 ms (derived from depth × order × stride) is sufficient for high‑quality TTS. Longer windows introduce noise without perceptual benefit.
The authors answer two central questions: (1) Long‑term dependencies are indeed important for acoustic modeling in TTS; (2) Modeling beyond roughly 600 ms of past and future context does not translate into perceptual gains. They argue that DFSMN, as a finite‑impulse‑response (FIR) network, can approximate the infinite‑impulse‑response (IIR) behavior of BLSTM given sufficient depth and order, confirming the theoretical claim that FIR filters can emulate IIR filters.
In conclusion, DFSMN delivers comparable or slightly better speech naturalness than BLSTM while dramatically reducing memory footprint and computational load, making it highly suitable for embedded or real‑time TTS deployments. The paper suggests future work such as integrating DFSMN with neural vocoders (e.g., WaveNet), extending experiments to multi‑speaker or multilingual corpora, and exploring adaptive order/stride mechanisms for further efficiency.
Comments & Academic Discussion
Loading comments...
Leave a Comment