CREPE: A Convolutional Representation for Pitch Estimation
The task of estimating the fundamental frequency of a monophonic sound recording, also known as pitch tracking, is fundamental to audio processing with multiple applications in speech processing and music information retrieval. To date, the best perf…
Authors: Jong Wook Kim, Justin Salamon, Peter Li
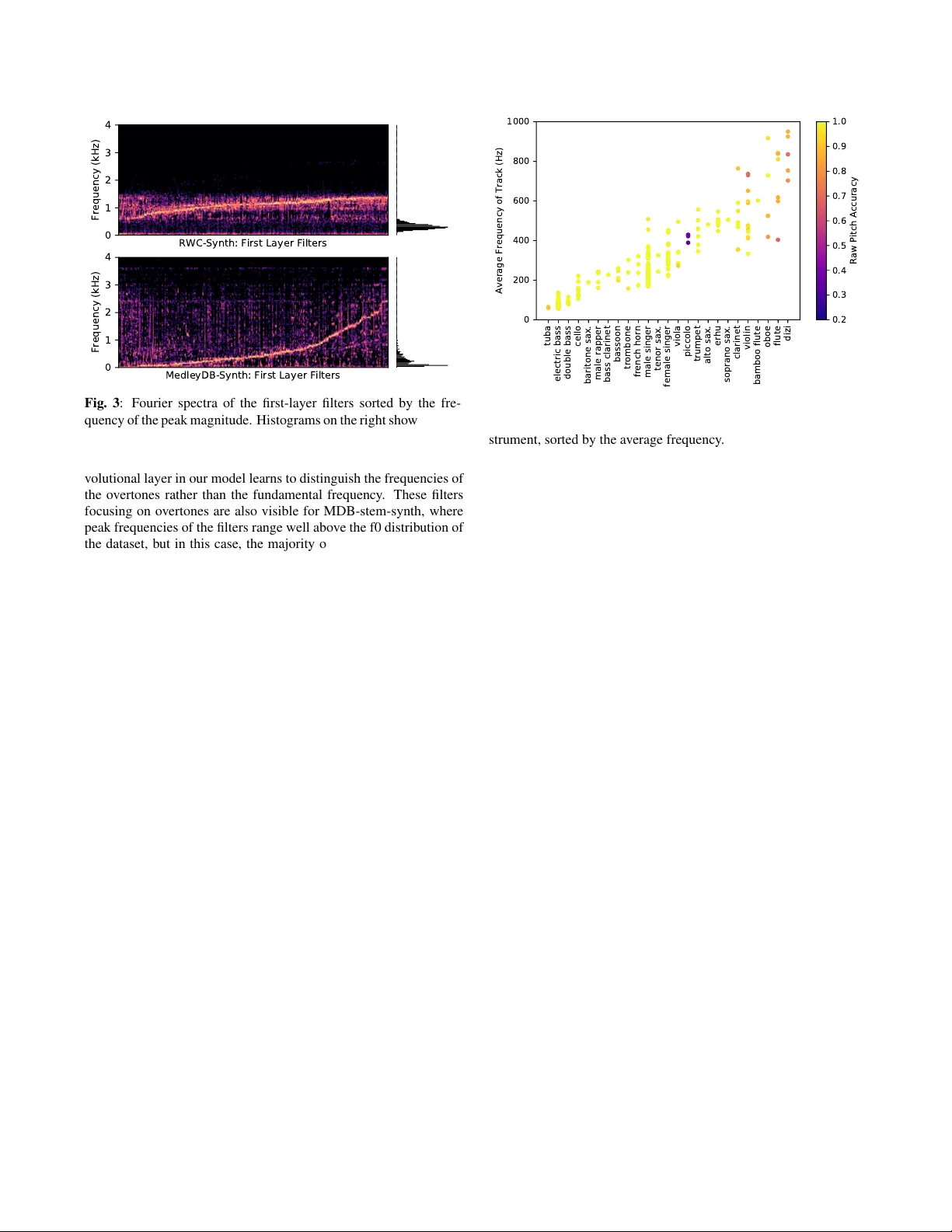
CREPE: A CONV OLUTIONAL REPRESENT A TION FOR PITCH ESTIMA TION J ong W ook Kim 1 , J ustin Salamon 1 , 2 , P eter Li 1 , J uan P ablo Bello 1 1 Music and Audio Research Laboratory , New Y ork Uni versity 2 Center for Urban Science and Progress, Ne w Y ork University ABSTRA CT The task of estimating the fundamental frequency of a monophonic sound recording, also known as pitch tracking, is fundamental to audio processing with multiple applications in speech processing and music information retriev al. T o date, the best performing techniques, such as the pYIN algorithm, are based on a combination of DSP pipelines and heuristics. While such techniques perform very well on av erage, there remain man y cases in which the y f ail to correctly estimate the pitch. In this paper , we propose a data-driven pitch tracking algorithm, CREPE, which is based on a deep con volutional neural network that operates directly on the time-domain wa veform. W e show that the proposed model produces state-of-the-art results, performing equally or better than pYIN. Furthermore, we evaluate the model’ s generalizability in terms of noise robustness. A pre- trained version of CREPE is made freely av ailable as an open-source Python module for easy application. Index T erms — pitch estimation, con volutional neural network 1. INTR ODUCTION Estimating the fundamental frequency (f0) of a monophonic audio signal, also known as pitch tracking or pitch estimation, is a long- standing topic of research in audio signal processing. Pitch esti- mation plays an important role in music signal processing, where monophonic pitch tracking is used as a method to generate pitch annotations for multi-track datasets [1] or as a core component of melody extraction systems [2, 3]. Pitch estimation is also important for speech analysis, where prosodic aspects such as intonations may reflect various features of speech [4]. Pitch is defined as a subjecti ve quality of perceived sounds and does not precisely correspond to the physical property of the fun- damental frequency [5]. Howe ver , apart from a few rare excep- tions, pitch can be quantified using fundamental frequenc y , and thus they are often used interchangeably outside psychoacoustical stud- ies. For con venience, we will also use the two terms interchangeably throughout this paper . Computational methods for monotonic pitch estimation hav e been studied for more than a half-century [6], and many reliable methods have been proposed since. Earlier methods commonly em- ploy a certain candidate-generating function, accompanied by pre- and post-processing stages to produce the pitch curve. Those func- tions include the cepstrum [6], the autocorrelation function (A CF) [7], the average magnitude dif ference function (AMDF) [8], the nor - malized cross-correlation function (NCCF) as proposed by RAPT [9] and PRAA T [10], and the cumulative mean normalized differ - ence function as proposed by YIN [11]. More recent approaches include SWIPE [12], which performs template matching with the spectrum of a sawtooth wav eform, and pYIN [13], a probabilistic variant of YIN that uses a Hidden Markov Model (HMM) to decode the most probable sequence of pitch values. According to a few comparativ e studies, the state of the art is achiev ed by YIN-based methods [14, 15], with pYIN being the best performing method to date [13]. A notable trend in the abo ve methods is that the deri vation of a better pitch detection system solely depends on cleverly de- vising a robust candidate-generating function and/or sophisticated post-processing steps, i.e. heuristics, and none of them are di- rectly learned from data, except for manual hyperparameter tuning. This contrasts with many other problems in music information re- triev al like chord ID [16] and beat detection [17], where data-driven methods hav e been shown to consistently outperform heuristic ap- proaches. One possible explanation for this is that since fundamental frequency is a low-lev el physical attribute of an audio signal which is directly related to its periodicity , in man y cases heuristics for estimating this periodicity perform extremely well with accuracies (measured in raw pitch accuracy , defined later on) close to 100%, leading some to consider the task a solved problem. This, howe ver , is not always the case, and ev en top performing algorithms like pYIN can still produce noisy results for challenging audio record- ings such as a sound of uncommon instruments or a pitch curve that fluctuates very fast. This is particularly problematic for tasks that require a fla wless f0 estimation, such as using the output of a pitch tracker to generate reference annotations for melody and multi-f0 estimation [18, 19]. In this paper, we present a novel, data-dri ven method for mono- phonic pitch tracking based on a deep con volutional neural network operating on the time-domain signal. W e sho w that our approach, CREPE (Con volutional Representation for Pitch Estimation), ob- tains state-of-the-art results, outperforming heuristic approaches such as pYIN and SWIPE while being more robust to noise too. W e further show that CREPE is highly precise, maintaining over 90% raw pitch accuracy ev en for a strict e v aluation threshold of just 10 cents. The Python implementation of our proposed approach, along with a pre-trained model of CREPE are made a vailable online 1 for easy utilization and reproducibility . 2. ARCHITECTURE CREPE consists of a deep con volutional neural network which oper - ates directly on the time-domain audio signal to produce a pitch es- timate. A block diagram of the proposed architecture is provided in Figure 1. The input is a 1024-sample excerpt from the time-domain audio signal, using a 16 kHz sampling rate. There are six con volu- tional layers that result in a 2048-dimensional latent representation, which is then connected densely to the output layer with sigmoid ac- tiv ations corresponding to a 360-dimensional output v ector ˆ y . From this, the resulting pitch estimate is calculated deterministically . 1 https://github.com/marl/crepe Fig. 1 : The architecture of the CREPE pitch tracker . The six conv olutional layers operate directly on the time-domain audio signal, producing an output vector that approximates a Gaussian curv e as in Equation 3, which is then used to deriv e the exact pitch estimate as in Equation 2. Each of the 360 nodes in the output layer corresponds to a spe- cific pitch v alue, defined in cents. Cent is a unit representing musical intervals relativ e to a reference pitch f ref in Hz, defined as a function of frequency f in Hz: ¢ ( f ) = 1200 · log 2 f f ref , (1) where we use f ref = 10 Hz throughout our e xperiments. This unit provides a logarithmic pitch scale where 100 cents equal one semi- tone. The 360 pitch values are denoted as ¢ 1 , ¢ 2 , · · · , ¢ 360 and are selected so that the y cover six octa ves with 20-cent interv als between C1 and B7, corresponding to 32.70 Hz and 1975.5 Hz. The resulting pitch estimate ˆ ¢ is the weighted av erage of the associated pitches ¢ i according to the output ˆ y , which gi ves the frequency estimate in Hz: ˆ ¢ = P 360 i =1 ˆ y i ¢ i P 360 i =1 ˆ y i , ˆ f = f ref · 2 ˆ ¢ / 1200 . (2) The target outputs we use to train the model are 360-dimensional vectors, where each dimension represents a frequency bin co vering 20 cents (the same as the model’ s output). The bin corresponding to the ground truth fundamental frequenc y is given a magnitude of one. As in [19], in order to soften the penalty for near -correct predictions, the target is Gaussian-blurred in frequency such that the energy sur- rounding a ground truth frequency decays with a standard deviation of 25 cents: y i = exp − ( ¢ i − ¢ true ) 2 2 · 25 2 , (3) This way , high activ ations in the last layer indicate that the input signal is likely to have a pitch that is close to the associated pitches of the nodes with high activ ations. The network is trained to minimize the binary cross entropy be- tween the target v ector y and the predicted vector ˆ y : L ( y , ˆ y ) = 360 X i =1 ( − y i log ˆ y i − (1 − y i ) log (1 − ˆ y i )) , (4) where both y i and ˆ y i are real numbers between 0 and 1. This loss function is optimized using the AD AM optimizer [20], with the learning rate 0.0002. The best performing model is selected after training until the v alidation accurac y no longer improves for 32 epochs, where one epoch consists of 500 batches of 32 examples randomly selected from the training set. Each con volutional layer is preceded with batch normalization [21] and followed by a dropout layer [22] with the dropout probability 0.25. This architecture and the training procedures are implemented using Keras [23]. 3. EXPERIMENTS 3.1. Datasets In order to objectively e valuate CREPE and compare its performance to alternative algorithms, we require audio data with perfect ground truth annotations. This is especially important since the performance of the compared algorithms is already very high. In light of this, we cannot use a dataset such as MedleyDB [1], since its annota- tion process includes manual corrections which do not guarantee a 100% perfect match between the annotation and the audio, and it can be affected, to a de gree, by human subjectivity . T o guarantee a perfectly objecti ve e valuation, we must use datasets of synthesized audio in which we have perfect control o ver the f0 of the resulting signal. W e use two such datasets: the first, R WC-synth, contains 6.16 hours of audio synthesized from the R WC Music Database [24] and is used to ev aluate pYIN in [13]. It is important to note that the signals in this dataset were synthesized using a fixed sum of a small number of sinusoids, meaning that the dataset is highly homogenous in timbre and represents an over -simplified scenario. T o ev aluate the algorithms under more realistic (but still controlled) conditions, the second dataset we use is a collection of 230 monophonic stems taken from MedleyDB and re-synthesized using the methodology presented in [18], which uses an analysis/synthesis approach to gen- erate a synthesized track with a perfect f0 annotation that maintains the timbre and dynamics of the original track. This dataset consists of 230 tracks with 25 instruments, totaling 15.56 hours of audio, and henceforth referred to as MDB-stem-synth. 3.2. Methodology W e train the model using 5-fold cross-validation, using a 60/20/20 train, validation, and test split. For MDB-stem-synth, we use artist- conditional folds, in order to av oid training and testing on the same artist which can result in artificially high performance due to artist or album effects [25]. The ev aluation of an algorithm’ s pitch estimation is measured in raw pitch accurac y (RP A) and raw chroma accuracy (RCA) with 50 cent thresholds [26]. These metrics measure the pro- portion of frames in the output for which the output of the algorithm is within 50 cents (a quarter -tone) of the ground truth. W e use the reference implementation provided in mir eval [27] to compute the ev aluation metrics. W e compare CREPE ag ainst the current state of the art in mono- phonic pitch tracking, represented by the pYIN [13] and SWIPE [12] algorithms. T o e xamine the noise rob ustness of each algorithm, we also ev aluate their pitch tracking performance on degraded versions of MDB-stem-synth, using the Audio Degradation T oolbox (ADT) [28]. W e use four dif ferent noise sources provided by the ADT : pub, white, pink, and brown. The pub noise is an actual recording of the sound in a crowded pub, and the white noise is a random signal with a constant power spectral density over all frequencies. The pink and brown noise hav e the highest power spectral density in lo w frequen- cies, and the densities fall of f at 10 dB and 20 dB per decade respec- tiv ely . W e used sev en dif ferent signal-to-noise ratio (SNR) values: ∞ , 40, 30, 20, 10, 5, and 0 dB. 3.3. Results 3.3.1. Pitch Accuracy T able 1 shows the pitch estimation performance tested on the two datasets. On the R WC-synth dataset, CREPE yields a close-to- perfect performance where the error rate is lo wer than the baselines by more than an order of magnitude. While these high accuracy numbers are encouraging, those are achievable thanks to the highly homogeneous timbre of the dataset. In order to test the generaliz- ability of the algorithms on a more timbrally di verse dataset, we ev aluated the performance on the MDB-stem-synth dataset as well. It is notable that the degradation of performance from R WC-synth is more significant for the baseline algorithms, implying that CREPE is more robust to comple x timbres compared to pYIN and SWIPE. Finally , to see ho w the algorithms compare under scenarios where any de viation in the estimated pitch from the true v alue could be detrimental, in T able 2 we report the RP A at lower evaluation tolerance thresholds of 10 and 25 cents as well as the RP A at the standard 50 cents threshold for reference. W e see that as the thresh- old is decreased, the difference in performance becomes more ac- centuated, with CREPE outperforming by over 8 percentage points when the evaluation tolerance is lowered to 10 cents. This suggests that CREPE is especially preferable when e ven minor deviations from the true pitch should be a voided as best as possible. Obtain- ing highly precise pitch annotations is perceptually meaningful for transcription and analysis/resynthesis applications. 3.3.2. Noise Robustness Noise robustness is key to many applications like speech analysis for mobile phones or smart speakers, or for liv e music performance. In Figure 2 we show how the pitch estimation performance is affected when an additiv e noise is present in the input signal. CREPE main- tains the highest accuracy for all SNR le vels for pub noise and white noise, and for all SNR levels except for the highest level of pink noise. Brown noise is the exception where pYIN’ s performance is almost unaf fected by the noise. This can be attrib uted to the fact that Dataset Metric CREPE pYIN SWIPE R WC- synth RP A 0.999 ± 0.002 0.990 ± 0.006 0.963 ± 0.023 RCA 0.999 ± 0.002 0.990 ± 0.006 0.966 ± 0.020 MDB- stem- synth RP A 0.967 ± 0.091 0.919 ± 0.129 0.925 ± 0.116 RCA 0.970 ± 0.084 0.936 ± 0.092 0.936 ± 0.100 T able 1 : A verage raw pitch/chroma accuracies and their standard deviations, tested with the 50 cents threshold. Dataset Threshold CREPE pYIN SWIPE R WC- synth 50 cents 0.999 ± 0.002 0.990 ± 0.006 0.963 ± 0.023 25 cents 0.999 ± 0.003 0.972 ± 0.012 0.949 ± 0.026 10 cents 0.995 ± 0.004 0.908 ± 0.032 0.833 ± 0.055 MDB- stem- synth 50 cents 0.967 ± 0.091 0.919 ± 0.129 0.925 ± 0.116 25 cents 0.953 ± 0.103 0.890 ± 0.134 0.897 ± 0.127 10 cents 0.909 ± 0.126 0.826 ± 0.150 0.816 ± 0.165 T able 2 : A verage ra w pitch accuracies and their standard deviations, with different e valuation thresholds. brown noise has most of its energy at low frequencies, to which the YIN algorithm (on which pYIN is based) is particularly robust. T o summarize, we confirmed that CREPE performs better in all cases where the SNR is below 10 dB while the performance varies depending on the spectral properties of the noise when the noise level is higher , which indicates that our approach can be reliable under a reasonable amount of additive noise. CREPE is also more stable, exhibiting consistently lower variance in performance compared to the baseline algorithms. 3.3.3. Model Analysis T o gain some insight into the CREPE model, in Figure 3 we visual- ize the spectra of the 1024 con volutional filters in the first layer of the neural network, with histograms of the ground-truth frequencies to the right of each plot. It is noticeable that the filters learned from the R WC-synth dataset have the spectral density concentrated be- tween 600 Hz and 1500 Hz, while the ground-truth frequencies are mostly between 100 Hz and 600 Hz. This indicates that the first con- Fig. 2 : Pitch tracking performance when additi ve noise signals are present. The error bars are centered at the average raw pitch accuracies and span the first standard deviations. W ith brown noise being a notable exception, CREPE sho ws the highest noise robustness in general. RWC-Synth: First Layer Filters 0 1 2 3 4 Frequency (kHz) MedleyDB-Synth: First Layer Filters 0 1 2 3 4 Frequency (kHz) Fig. 3 : Fourier spectra of the first-layer filters sorted by the fre- quency of the peak magnitude. Histograms on the right show the dis- tribution of ground-truth frequencies in the corresponding dataset. tuba electric bass double bass cello baritone sax. male rapper bass clarinet bassoon trombone french horn male singer tenor sax. female singer viola piccolo trumpet alto sax. erhu soprano sax. clarinet violin bamboo flute oboe flute dizi 0 200 400 600 800 1000 Average Frequency of Track (Hz) 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0 Raw Pitch Accuracy Fig. 4 : The raw pitch accuracy (RP A) of CREPE’ s predictions on each of the 230 tracks in MDB-stem-synth with respect to the in- strument, sorted by the av erage frequency . volutional layer in our model learns to distinguish the frequencies of the overtones rather than the fundamental frequency . These filters focusing on overtones are also visible for MDB-stem-synth, where peak frequencies of the filters range well abo ve the f0 distribution of the dataset, but in this case, the majority of the filters ov erlap with the ground-truth distribution, unlike R WC-synth. A possible expla- nation for this is that since the timbre in R WC-synth is fixed and identical for all tracks, the model is able to obtain a highly accurate estimate of the f0 by modeling its harmonics. Con versely , when the timbre is heterogeneous and more complex, as is the case for MDB- stem-synth, the model cannot rely solely on the harmonic structure and requires filters that capture the f0 periodicity directly in addition to the harmonics. In both cases, this suggests that the neural network can adapt to the distribution of timbre and frequency in the dataset of interest, which in turn contributes to the higher performance of CREPE compared to the baseline algorithms. 3.3.4. P erformance by Instrument The MDB-stem-synth dataset contains 230 tracks from 25 differ - ent instruments, where electric bass (58 tracks) and male singer (41 tracks) are the most common while there are instruments that occur in only one or two tracks. In Figure 4 we plot the performance of CREPE on each of the 230 tracks, with respect to the instrument of each track. It is notable that the model performs worse for the in- struments with higher average frequencies, but the performance is also dependent on the timbre. CREPE performs particularly worse on the tracks with the dizi, a Chinese transverse flute, because the tracks came from the same artist, and they are all placed in the same split. This means that for the fold in which the dizi tracks are in the test set, the training and validation sets do not contain a single dizi track, and the model fails to generalize to this previously unseen timbre. There are 5 instruments (bass clarinet, bamboo flute, and the family of saxophones) that occur only once in the dataset, but their performance is decent, because their timbres do not deviate too far from other instruments in the dataset. F or the flute and the violin, although there are many tracks with the same instrument in the train- ing set, the performance is low when the sound in the tested tracks is too lo w (flute) or too high (violin) compared to other tracks of the same instruments. The low performance on the piccolo tracks is due to an error in the dataset where the annotation is inconsistent with the correct pitch range of the instrument. Unsurprisingly , the model performs well on test tracks whose timbre and frequency range are well-represented in the training set. 4. DISCUSSIONS AND CONCLUSION In this paper , we presented a novel data-driv en method for mono- phonic pitch tracking based on a deep con volutional neural network operating on time-domain input, CREPE. W e sho wed that CREPE obtains state-of-the-art results, outperforming pYIN and SWIPE on two datasets with homogeneous and heterogeneous timbre respec- tiv ely . Furthermore, we showed that CREPE remains highly accurate ev en at a v ery strict e valuation threshold of just 10 cents. W e also showed that in most cases CREPE is more rob ust to added noise. Ideally , we want the model to be in variant to all transformations that do not affect pitch, such as changes due to distortion and rev er- beration. Some in variance can be induced by the architectural design of the model, such as the translation inv ariance induced by pooling layers in our model as well as in deep image classification models. Howe ver , it is not as straightforw ard to design the model architecture to specifically ignore other pitch-preserving transformations. While it is still an intriguing problem to build an architecture to achieve this, we could use data augmentation to generate transformed and degraded inputs that can effecti vely make the model learn the in vari- ance. The robustness of the model could also be improved by ap- plying pitch-shifts as data augmentation [29] to cover a wider pitch range for every instrument. In addition to data augmentation, v arious sources of audio timbre can be obtained from software instruments; NSynth [30] is an example where the training dataset is generated from the sound of software instruments. Pitch v alues tend to be continuous over time, but CREPE esti- mates the pitch of ev ery frame independently without using any tem- poral tracking, unlike pYIN which exploits this by using an HMM to enforce temporal smoothness. W e can potentially improv e the per- formance of CREPE even further by enforcing temporal smoothness. In the future, we plan to do this by means of adding recurrent archi- tecture to our model, which could be trained jointly with the con- volutional front-end in the form of a conv olutional-recurrent neural network (CRNN). 5. REFERENCES [1] Rachel M Bittner , Justin Salamon, Mike T ierney , Matthias Mauch, Chris Cannam, and Juan P ablo Bello, “Medleydb: A multitrack dataset for annotation-intensiv e mir research., ” in Pr oceedings of the 15th ISMIR Confer ence , 2014, vol. 14, pp. 155–160. [2] Juan Bosch and Emilia G ´ omez, “Melody extraction in sym- phonic classical music: a comparativ e study of mutual agree- ment between humans and algorithms, ” in Pr oceedings of the 9th Confer ence on Inter disciplinary Musicology (CIM14) , 2014. [3] Matthias Mauch, Chris Cannam, Rachel Bittner, Geor ge Fazekas, Justin Salamon, Jiajie Dai, Juan Bello, and Simon Dixon, “Computer-aided melody note transcription using the tony software: Accuracy and efficienc y , ” in Proceedings of the F irst International Confer ence on T ec hnologies for Music Notation and Repr esentation , 2015. [4] Maria Luisa Zubizarreta, Pr osody , focus, and word or der , MIT Press, 1998. [5] William M Hartmann, Signals, Sound, and Sensation , Springer , 1997. [6] A Michael Noll, “Cepstrum pitch determination, ” The journal of the acoustical society of America , vol. 41, no. 2, pp. 293– 309, 1967. [7] John Dubnowski, Ronald Schafer, and Lawrence Rabiner, “Real-time digital hardware pitch detector , ” IEEE T ransac- tions on Acoustics, Speech, and Signal Pr ocessing , v ol. 24, no. 1, pp. 2–8, 1976. [8] Myron Ross, Harry Shaffer , Andrew Cohen, Richard Freud- berg, and Harold Manley , “ A verage magnitude dif ference func- tion pitch extractor , ” IEEE T ransactions on Acoustics, Speech, and Signal Pr ocessing , vol. 22, no. 5, pp. 353–362, 1974. [9] David T alkin, “ A rob ust algorithm for pitch tracking (rapt), ” Speech Coding and Synthesis , 1995. [10] Paul Boersma, “ Accurate short-term analysis of the fundamen- tal frequency and the harmonics-to-noise ratio of a sampled sound, ” in Pr oceedings of Institute of Phonetic Sciences , 1993, vol. 17, pp. 97–110. [11] Alain De Che veign ´ e and Hideki Ka wahara, “Y in, a fundamen- tal frequency estimator for speech and music, ” The Journal of the Acoustical Society of America , v ol. 111, no. 4, pp. 1917– 1930, 2002. [12] Arturo Camacho and John G Harris, “ A sawtooth w av eform inspired pitch estimator for speech and music, ” The Journal of the Acoustical Society of America , v ol. 124, no. 3, pp. 1638– 1652, 2008. [13] Matthias Mauch and Simon Dixon, “pYIN: A fundamental fre- quency estimator using probabilistic threshold distributions, ” in Acoustics, Speech and Signal Pr ocessing (ICASSP), 2014 IEEE International Confer ence on . IEEE, 2014, pp. 659–663. [14] Adrian von dem Knesebeck and Udo Z ¨ olzer , “Comparison of pitch trackers for real-time guitar effects, ” in Pr oceedings of the International Conference on Digital Audio Effects (DAFx) , 2010. [15] Onur Babacan, Thomas Drugman, Nicolas d’Alessandro, Nathalie Henrich, and Thierry Dutoit, “ A comparati ve study of pitch extraction algorithms on a large variety of singing sounds, ” in Acoustics, Speech and Signal Process- ing (ICASSP), 2013 IEEE International Conference on . IEEE, 2013, pp. 7815–7819. [16] Eric J Humphrey and Juan P ablo Bello, “Rethinking automatic chord recognition with con volutional neural networks, ” in Ma- chine Learning and Applications (ICMLA), 2012 11th Interna- tional Confer ence on . IEEE, 2012, vol. 2, pp. 357–362. [17] Sebastian B ¨ ock and Markus Schedl, “Enhanced beat tracking with conte xt-aware neural netw orks, ” in Pr oceedings of the In- ternational Conference on Digital Audio Effects (DAFx) , 2011. [18] Justin Salamon, Rachel M Bittner , Jordi Bonada, Juan Jos ´ e Bosch V icente, Emilia G ´ omez Guti ´ errez, and Juan P Bello, “ An analysis/synthesis frame work for automatic f0 annotation of multitrack datasets, ” in Pr oceedings of the 18th ISMIR Con- fer ence , 2017. [19] Rachel M Bittner , Brian McFee, Justin Salamon, Peter Li, and Juan Pablo Bello, “Deep salience representations for f0 track- ing in polyphonic music, ” in Proceedings of the 18th ISMIR Confer ence , 2017. [20] Diederik Kingma and Jimmy Ba, “ Adam: A method for stochastic optimization, ” in Pr oceedings of the International Confer ence on Learning Representations (ICLR) , 2015. [21] Sergey Iof fe and Christian Szegedy , “Batch normalization: Ac- celerating deep network training by reducing internal cov ari- ate shift, ” in International Conference on Machine Learning , 2015, pp. 448–456. [22] Nitish Sriv astav a, Geoffrey E Hinton, Alex Krizhevsky , Ilya Sutske ver , and Ruslan Salakhutdino v , “Dropout: a simple way to prevent neural networks from o verfitting., ” Journal of Ma- chine Learning Resear ch , v ol. 15, no. 1, pp. 1929–1958, 2014. [23] Franc ¸ ois Chollet, “Keras: The python deep learning library , ” URL: https://keras.io/ . [24] Masataka Goto, Hiroki Hashiguchi, T akuichi Nishimura, and Ryuichi Oka, “Rwc music database: Popular, classical and jazz music databases., ” in Pr oceedings of the 3rd ISMIR Con- fer ence , 2002, vol. 2, pp. 287–288. [25] Bob L Sturm, “Classification accurac y is not enough, ” Journal of Intelligent Information Systems , vol. 41, no. 3, pp. 371–406, 2013. [26] Justin Salamon, Emilia G ´ omez, Daniel PW Ellis, and Ga ¨ el Richard, “Melody e xtraction from polyphonic music signals: Approaches, applications, and challenges, ” IEEE Signal Pr o- cessing Magazine , v ol. 31, no. 2, pp. 118–134, 2014. [27] Colin Raffel, Brian McFee, Eric J Humphrey , Justin Salamon, Oriol Nieto, Dawen Liang, Daniel PW Ellis, and C Colin Raf- fel, “mir ev al: A transparent implementation of common mir metrics, ” in Pr oceedings of the 15th ISMIR Confer ence , 2014. [28] Matthias Mauch and Sebastian Ewert, “The audio degradation toolbox and its application to robustness evaluation, ” in Pr o- ceedings of the 14th ISMIR Confer ence , Curitiba, Brazil, 2013, accepted. [29] Brian McFee, Eric J. Humphrey , and Juan Pablo Bello, “ A software frame work for musical data augmentation, ” in 16th International Society for Music Information Retrieval Confer- ence , 2015, ISMIR. [30] Jesse Engel, Cinjon Resnick, Adam Roberts, Sander Dieleman, Douglas Eck, Karen Simonyan, and Mohammad Norouzi, “Neural audio synthesis of musical notes with wa venet autoen- coders, ” arXiv preprint , 2017.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment