Analysis of Schema.org Usage in the Tourism Domain
Schema.org is an initiative founded in 2011 by the four-big search engine Bing, Google, Yahoo!, and Yandex. The goal of the initiative is to publish and maintain the schema.org vocabulary, in order to facilitate the publication of structured data on the web which can enable the implementation of automated agents like intelligent personal assistants and chatbots. In this paper, the usage of schema.org in tourism domain between years 2013 and 2016 is analysed. The analysis shows the adoption of schema.org, which indicates how well the tourism sector is prepared for the web that targets automated agents. The results have shown that the adoption of schema.org type and properties is grown over the years. While the US is dominating the annotation numbers, a drastic drop is observed for the proportion of the US in 2016. Poorly rated businesses are encountered more in 2016 results in comparison to previous years.
💡 Research Summary
The paper presents a longitudinal study of Schema.org adoption within the tourism sector, covering the years 2013 through 2016. The authors leveraged the Web Data Commons (WDC) micro‑data releases, which provide RDF‑style N‑Quads extracted from a large portion of the public web. After loading the yearly dumps into a triple store, they executed a series of SPARQL 2 queries to count instances of twelve tourism‑related classes (Airport, Event, Hotel, LakeBodyOfWater, LandmarksOrHistoricalBuildings, LocalBusiness, Mountain, Museum, Park, Restaurant, RiverBodyOfWater, and SkiResort) as well as their associated properties.
Data preprocessing combined Entity Reconciliation (ER) and Reverse Geocoding (RG) to map address strings to standardized country names. Because country names appear in many languages and scripts, the authors applied a k‑Nearest‑Neighbour (kNN) similarity matching using Levenshtein edit distance to harmonize the labels. This pipeline ensured that country‑level statistics were not biased by linguistic variations.
Quantitatively, the total number of triples grew dramatically: 1.2 billion in 2013, 622 million in 2014, 1.1 billion in 2015, and 2.1 billion in 2016. The upward trend reflects a broadening acceptance of structured data on the web. In the early years the United States dominated the annotation landscape, accounting for roughly 80 % of Hotel instances and a similar share of overall tourism annotations. By 2016 the U.S. share fell to 28.4 %, indicating a rapid rise in contributions from other countries.
At the property level, the analysis highlighted a stark contrast between the Hotel class and the remaining eleven classes. Hotel instances consistently included address or geo‑coordinates that could be reverse‑geocoded to a country (over 70 % success rate). For the other classes, the success ratio never exceeded 70 %, and often stayed below 50 %. This suggests that many tourism providers publish only partial location metadata, limiting the usefulness of their data for location‑aware agents.
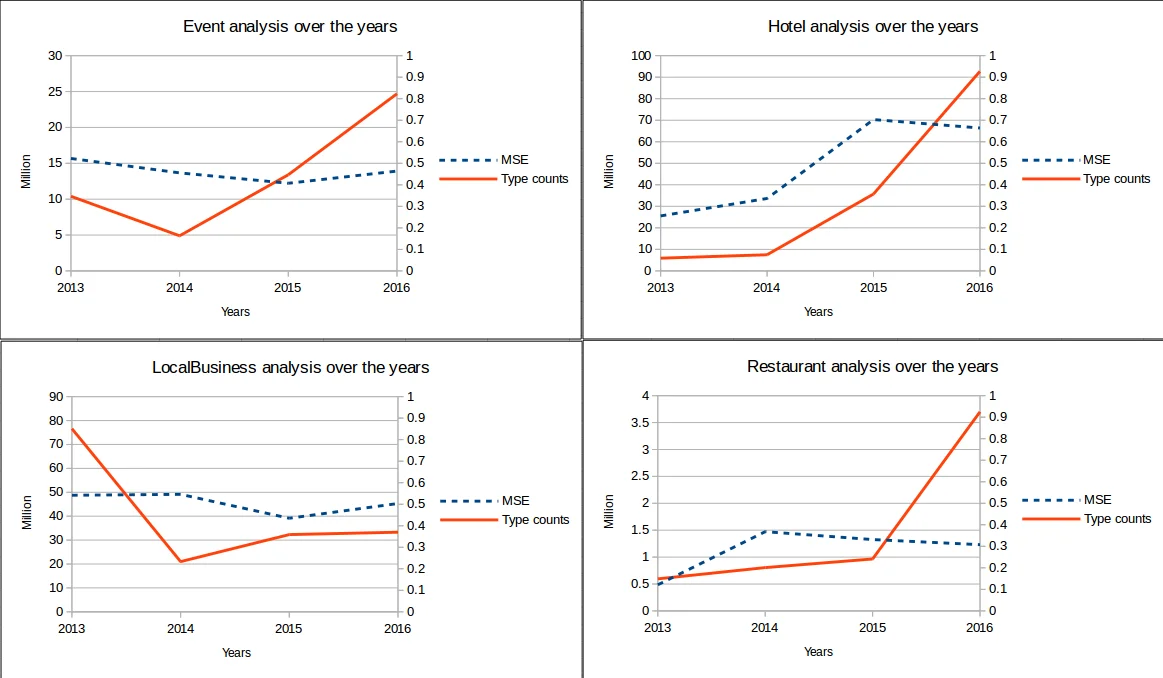
To assess annotation quality, the authors computed Mean Squared Error (MSE) for each class across years, treating missing or malformed property values as errors. The MSE either decreased or remained stable over time, indicating an overall improvement in data quality.
A special focus was placed on the Hotel Extension introduced by schema.org in August 2016 (e.g., Campground, HotelRoom, Room, and the hasAmenity property). The authors examined the three‑month window from August to October 2016 and found modest uptake: 716 Campground, 117 HotelRoom, and 3,339 Room instances. The hasAmenity property appeared about 7,000 times, primarily attached to Room. Most of the newly added types, however, were absent from the WDC dumps, reflecting the early stage of adoption.
Rating information was also explored. By extracting the aggregateRating property and normalizing values to a 1‑5 scale, the authors observed a noticeable increase in low‑rating (1‑2) entries from 2015 to 2016. This aligns with prior research (Park & Nicolau, 2015) showing that consumers tend to notice extreme (especially negative) reviews more than moderate ones.
The paper acknowledges several limitations. The 2013 dataset is heavily skewed by the domain citysearch.com, which contributed more than 65 % of annotations that year, causing an artificial spike. The short observation window for the Hotel Extension prevents a full assessment of its long‑term impact. Moreover, incomplete address or geo properties hinder accurate country‑level analysis for many classes.
In conclusion, the study demonstrates that Schema.org usage in tourism has grown both in volume and quality between 2013 and 2016. While the United States’ share of annotations has declined, global participation is rising. Nevertheless, critical properties such as address and geo are still under‑utilized outside the Hotel class, and newly introduced extension types have yet to achieve widespread adoption. The authors suggest future work that includes a deeper PLD‑level (pay‑level domain) analysis, incorporation of the 2017 WDC dump, and longitudinal monitoring of extension uptake to better understand how the tourism sector prepares for automated agents and intelligent personal assistants.
Comments & Academic Discussion
Loading comments...
Leave a Comment