Content-based Representations of audio using Siamese neural networks
In this paper, we focus on the problem of content-based retrieval for audio, which aims to retrieve all semantically similar audio recordings for a given audio clip query. This problem is similar to the problem of query by example of audio, which aim…
Authors: Pranay Manocha, Rohan Badlani, Anurag Kumar
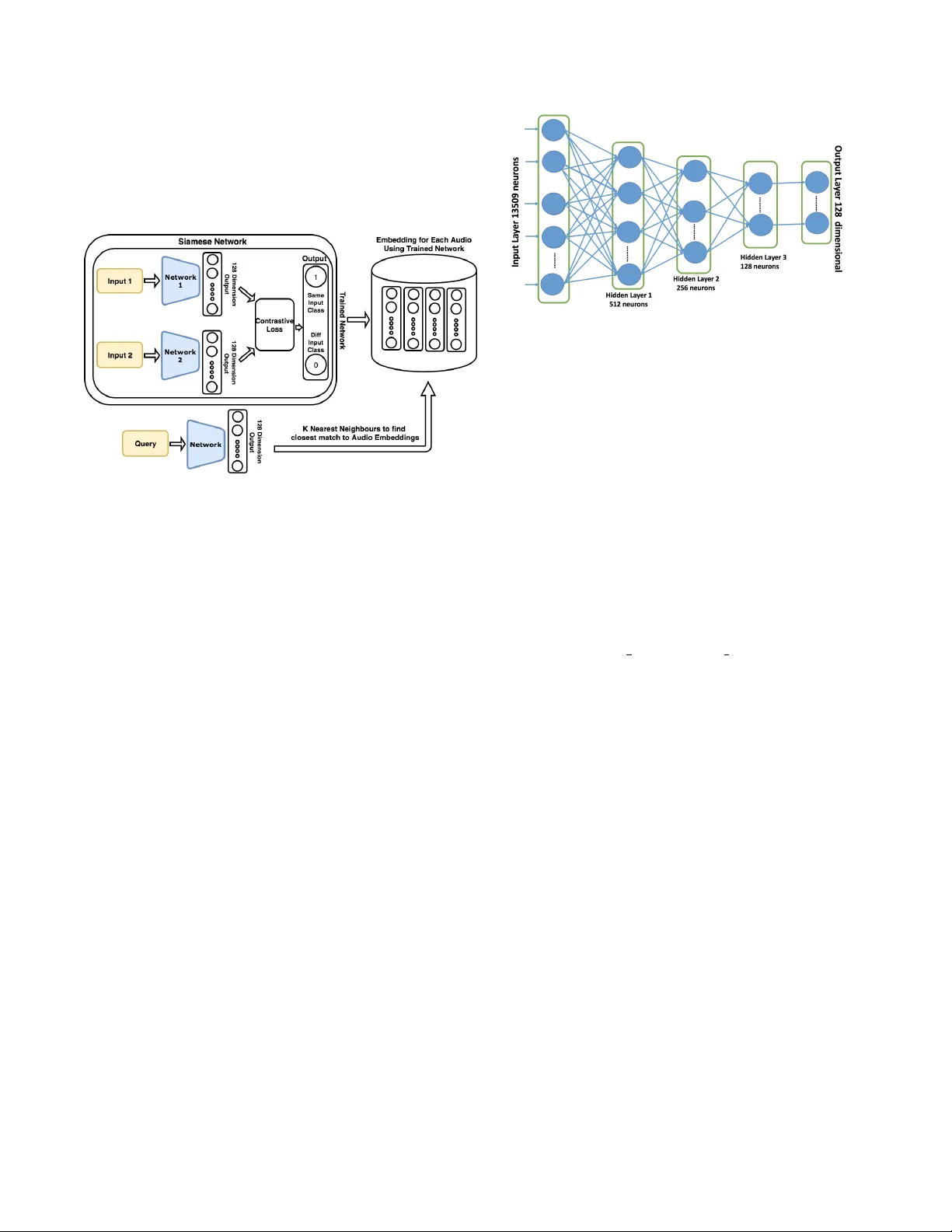
CONTENT -B ASED REPRESENT A TIONS OF A UDIO USING SIAMESE NEURAL NETWORKS Pranay Manocha † , Rohan Badlani ? , Anura g K umar ‡ , Ankit Shah ‡ , Benjamin Elizalde ‡ § , Bhiksha Raj ‡ † Department of Electronics and Electrical Engineering IIT Guwahati, India ? Department of Computer Science, BITS Pilani, India ‡ Language T echnologies Institute, Carne gie Mellon Univ ersity , Pittsb urgh, United States Email: pranaymnch@gmail.com, rohan.badlani@gmail.com, alnu@andre w .cmu.edu, aps1@andre w .cmu.edu, bmartin1@andre w .cmu.edu, bhiksha@cs.cmu.edu ABSTRA CT In this paper , we focus on the problem of content-based retriev al for audio, which aims to retriev e all semantically similar audio record- ings for a gi ven audio clip query . This problem is similar to the problem of query by example of audio, which aims to retrie ve media samples from a database, which are similar to the user-provided ex- ample. W e propose a novel approach which encodes the audio into a vector representation using Siamese Neural Netw orks. The goal is to obtain an encoding similar for files belonging to the same audio class, thus allowing retriev al of semantically similar audio. Using simple similarity measures such as those based on simple euclidean distance and cosine similarity we show that these representations can be very ef fectively used for retrie ving recordings similar in audio content. Index T erms — Audio Fingerprinting, Content-Based Retrie val, Query by Example, Siamese Network, Similar Matching 1. INTR ODUCTION Humans hav e an inherent ability to distinguish and recognize differ- ent sounds. Moreov er , we are also able to relate and match similar sounds. In fact, we have the capability to detect and relate sound ev ents or “acoustic objects” which we have never encountered be- fore, based on ho w that phenomenon stands out ag ainst the back- ground [1]. This ability plays a crucial role in our interactions with the surroundings and it is also expected that machines ha ve this abil- ity to relate the two audio recordings based on their semantic content. This is precisely the broad goal of this paper . W e propose a method to encode semantic content of an audio recording such that two audio recordings of similar content (containing same audio events) can be matched and related through these embeddings. More specifically , we address the problem of content-based retrieval for audio: given an input audio recording we intend to retrieve audio recordings which are semantically related to it. Semantic similarity matching and retriev al based on it has re- ceiv ed much attention for video and images [2], [3] and [4]. How- ev er , in the broad field of machine learning for audio, semantic sim- ilarity matching and retrie val based on audio has recei ved limited at- tention [5]. A major focus has been music information retrieval [6], [7], [8] and semantic retriev al of audio using text queries [9], [10]. Our focus here is on non-music and non-speech content, sounds which we hear ev eryday in our daily life, since they play an impor- tant role in defining the ov erall semantic content of an audio record- First two authors contributed equally § Acknowledges CON ACYT for his doctoral fello wship, No.343964 ing. Note that the problem of semantic content matching is different from the problem of audio event detection and classification [11]. Our goal is not to detect or classify sound e vents in an audio record- ing b ut to de velop methods which capture the semantic content of an audio and be useful in retrieving similar audios. One method which has been explored considerably for audios is the idea of fingerprint- ing. Audio fingerprinting is an acoustic approach that provides the ability to derive a compact representation which can be ef ficiently matched against other audio clips to compare their similarity or dissimilarity [12]. Audio fingerprinting has v arious applications like Broadcast Monitoring[13], Audio/Song Detection[14], Filter - ing T echnology for File Sharing[15] and Automatic Music Library organization[16]. W e focus on dev eloping an efficient content-based retriev al system that can retrieve audio clips which contain similar audio ev ents as the query audio clip. One can potentially think of applying the con ventional fingerprinting approach [14] for matching to find recordings with similar audio content. Howe ver , fingerprinting is useful only in finding e xact matc h . It has been used for finding mul- tiple videos of the same e vent [17]. In [18] it is used to find multiple occurrences of a sound event in a recording. But it cannot solve the problem of retrieving all semantically similar files together . In fact ev en for finding repetitions of the same sound e vent it does not work well if the sound ev ent is unstructured [18]. The reason is that finger- printing tries to capture local features specific to an audio recording. It does not try to capture the broader features which might represent a semantically meaningful class. For searching similar videos based on content, we need audio retriev als belonging to the correct audio class and not just exact matches as in con ventional fingerprinting. Hence, we need representations which can encode class specific information. In this paper , we try to achieve this by using a Siamese Neural Netw ork. Although the siamese network has been previously explored for representations and content understanding in images and video [19, 3], to the best of our kno wledge this is the first work employing it in the context of sound e vents. Siamese neural networks incorporate methods that excel at de- tecting similar instances but fail to of fer robust solutions that may be applied to other types of problems like classification. In this pa- per , we present a novel approach that uses a Siamese network to au- tomatically acquire features which enable the model to distinguish between clips containing distinct audio events and encodes a giv en audio into a vector fingerprint. W e show that the output feature vec- tor has an inherent property to capture semantic similarity between audio containing same ev ents. Although the cost of the learning al- gorithm itself may be considerable, this compressed representation is powerful as we are able to not only learn them without imposing strong priors like in [14], but also to retriev e semantically similar clips by using this feature space. 2. PR OPOSED APPR OA CH Fig. 1 . Framew ork of the Proposed approach 2.1. Framework Outline W e propose a neural network based approach to obtain representa- tions or embeddings such that semantically similar audios ha ve sim- ilar embeddings. W e learn these semantic representations through Siamese Neu- ral Networks. Fig 1 shows our proposed frame work. A Siamese neural network actually consists of two twin netw orks. The Siamese network takes in two different inputs, one applied to each twin, and is trained to learn the similarity between these inputs. If the inputs are similar then it should predict 1 otherwise 0 . W e use the trained component (twin) network as a feature extractor to obtain represen- tations for audio recordings in the database, as shown in the figure. The input audio query is also embedded through the same network and its embedding is matched with embeddings of recordings in the database to rank them in decreasing order of similarity . This rank- ing can be done through any distance or similarity measure. In this work we use cosine similarity and euclidean distance. Based on the ranked list one can return the top K most similar audios. 2.2. Siamese Network and Loss Function The Siamese neural network is a class of neural network architec- tures that contains two or more identical sub-netw orks, meaning that all sub-networks hav e the same configuration with the same param- eters. W eights and the parameter updates are mirrored across all sub-networks simultaneously . Siamese networks have pre viously been used in tasks in volving similarity or identifying relationships between two or more comparable things. Muller et al.[20] used a Siamese network for paraphrase scoring by giving a score to a pair of input sentences. Bromley et al.[21] used a Siamese network for the task of signature verification. In the domain of audio, it has been incorporated for content-based matching in music [22] and in speech to model speaker related information [23, 24]. Siamese networks of fers several advantages. All subnetworks hav e similar weights which leads to fewer training parameters thus requiring less training data and a lesser tendency to over fit. More- ov er , the outputs of each of the subnetworks are representation vec- tors with the same semantics and this makes them much easier to Fig. 2 . Architecture of the Subnetworks in the Siamese Network. The final layer of 128 neurons is also the output layer compare with one other . These characteristics makes them well suited for our task. T o train our Siamese Network we use the contrastiv e loss func- tion defined in [25]. The goal is to learn the parameters W of a func- tion G W , such that neighbors are pulled together and non-neighbors are pushed apart. T o achie ve this, the objective function needs to be suitably defined. The learning process here operates on a pair of samples. Let X 1 , X 2 ∈ P be a pair of input samples and let Y be the label assigned to this pair . Y = 1 if the inputs X 1 and X 2 are similar , otherwise Y = 0 . The distance between X 1 and X 2 is defined as the euclidean distance between the mapping from the function G W D W ( X 1 , X 2 ) = k G w ( X 1 ) − G w ( X 2 ) k (1) The o verall loss function for the pair X 1 and X 2 , is then defined as L ( W, Y , X 1 , X 2 ) = ( Y ) 1 2 ( D w ) 2 + (1 − Y ) 1 2 { max (0 , m − D w ) } 2 (2) In Eq 2, m > 0 is the mar gin. The idea behind this margin is that the dissimilar points contribute to the training loss only if the distance between them, D W , is within the radius defined by margin v alue m . For the pairs of similar inputs we always want reduce the distance between them. 2.3. Network Architectur e The architecture of the individual sub-networks in the Siamese net- work is shown in Fig 2. Each sub-network is a feed-forward multi layer perceptron (MLP) network. The input to the network are log- frequency spectrograms of audio recordings. The frames in Logspec are concatenated to create one long extended vector . The dimen- sionality of the inputs are 13509 (See 3.2 for details). The network consists of a total of 3 layers after the input layer . The first layer con- sists of 512 neurons, the second layer 256 neurons and the last layer has 128 neurons. The last layer also serves as the output layer . The activ ation function in all layers is ReLU ( max (0 , x ) ). A dropout of 0 . 3 is applied between all three layers during training. W e will refer to the network as N R 2.4. Representations and Retriev al All audio clips in the audio database are represented through the 128 dimensional output from the network N R . When a query audio clip is gi ven, we first obtain its 128 dimensional representation using N R . This representation is then matched to representations of all audios in the database using a similarity or distance function. The clips in database are ranked according to the similarity measure and then the top K clips are returned. In other ways, one can think of it as obtaining K nearest neighbors in the database. Note that all operations are done on fixed length audios of 2 seconds, details are provided in further sections. 3. D A T ASET AND EXPERIMENT AL SETUP W e study the problem of semantic similarity based retrieval in the domain of sound events. More specifically , given an audio clip of a sound class, the goal is to retrieve all audio clips of that class from the database. W e consider the list of sound events from 3 databases, ESC-50[26], US8K[27] and TUT 2016[28]. Overall, we considered a total of 76 sound ev ents. Some examples are, Dog Barking, Clock T ick-T ock, W ind Blowing etc. audio ev ents include wide range of sound ev ents, including dif ferent sound events from broad cate gories from animal sounds such as Dog Barking and Crow , non-speech hu- man sounds such as Clapping and Coughing , e xterior sounds such as Sir en, Engine, Airplane to urban soundscape sounds such as Street Music, Jac khammer etc. 3.1. Y ouT ube Dataset The importance of semantic similarity matching lies in its utility in content-based retrieval of multimedia data on the web . Hence, we work with audio recordings from Y ouT ube. User generated record- ings on multimedia sharing websites such as Y ouT ube, are often very noisy , unstructured and recorded under different conditions. Hence, ev en intra-class variation is very high, which makes content-based retriev al an extremely difficult problem. For each of the 76 classes, we obtain 100 recordings from Y ouT ube. T o obtain relev ant results we use < SOUND N AME sound > ( e.g < car horn sound > ) as search query . From the returned list we select 100 recordings based on their length and rel- ev ance for the query . V ery short ( < 2 seconds) and very long ( > 10 min) recordings are not considered. W e divided the dataset in the ratio of 70-10-20. 70 percent of the data per class is used for training and the remaining 30 percent data is split 1:2 between validation and testing. Thus, we take 70 samples per class for training, 10 for validation and the remaining 20 for testing, given that we roughly hav e 100 files per audio class. Overall, we hav e around 5K audio files for training, 760 files for validation and around 1500 files for testing. For our experiments, we operate on 2 second clips from each of these recordings. Hence, our actual database for experiments are fixed length 2 second audio clips in training as well as validation and test sets. 3.2. Siamese Network T raining The inputs to the Siamese network must be pairs of audio clips. W e assign label 1 to the pairs of clips from the same class and label 0 to the pairs from dif ferent classes. W e consider two training sets, balanced and unbalanced. The network trained on balanced set will be referred to as N B R and that trained on unbalanced as N U R . In the balanced case, to create pairs with positi ve label ( Y = 1 ), we consider all possible pairs belonging to the same audio class. For pairs with negati ve label ( Y = 0 ), a clip belonging to a sound class is randomly paired with a clip from any other sound class. Hence, we end up with equal number of positi ve and ne gati ve label pairs. In the unbalanced case the positi ve label pairs are obtained in the same way . But for the negati ve label, we pair a clip belonging to a sound class with all clips not belonging to that sound. Thus, we hav e a non equal distribution of positi ve and negati ve labels. W e used the log spectrogram features, taking 1024 point FFT ov er a window size of 64ms and an ov erlap of 32ms per windo w . Both the axis were con verted to the log scale and 79 bins were chosen for the frequency axis whereas 171 quantization bins were chosen for the time scale. W e then concatenate these 79X171=13509 features and use as an input to the Siamese Network. The reason for taking log spectrogram features is that the features having a large difference on a common scale have diminished differences on the log scale. It is specially useful in those cases where we ha ve a huge v ariation of feature magnitudes and hence it brings all a common scale. All parameters were tuned using the v alidation set. W e train each model to 200 epochs and optimize on the training and validation losses. 3.3. Retrieval W e obtain the vector encoding of each file of the audio class by passing it through the trained saved model. All audio clips in the database are represented by these representations. At the time of testing, we obtain the representation for the query audio clip using the network and compute its similarity with representations of audios in the database. For computing similarity between two representa- tions we use either euclidean distance or cosine similarity . Fig. 3 . V ariation of M P K with different K, from K=1 to K=30 4. EV ALU A TION AND RESUL TS 4.1. Metrics For any gi ven query audio, we obtain a ranked list of audio clips present in the database which contain similar audio events present in the query clip. W e then compute 3 metrics for ev aluation which are defined below: 4.1.1. A verage Precision The a verage precision for a query is defined as mean of precisions at all positiv e hits. AP = 1 m j m j X i =1 P r ecision i (3) P r ecision i measures the fraction of correct items among first i rec- ommendations. This precision is measured at every positiv e hit in the ranked list. m j refers to the number of positive items in the database for the query . A verage precision is simply the mean of these pre- cision values. W e will be reporting the mean of av erage precision (MAP) ov er all queries. 4.1.2. Precision at 1 This metric measures the precision at the first positive hit only . The idea is to understand where does the first positive item lie in the ranked list. Again the mean of Precision at 1 ( M P 1 ) over all queries are reported. 4.1.3. Precision of T op K retrieval This metric measures the quality of retrie ved items in the top K items in the ranked list. For each query , we calculate the number of correct class instances in the top K files and then divide that by K to get the precision of the correct class amongst the top K retriev ed files and take an average across all queries. Multiplying this score by K tells us the average number of correct class matches in the top K of the retrieved list. This measure tells us about the precision of the correct class in the top K retrieved list. Once again the mean of this metric ov er all queries is reported ( M P K ) Measures N B R N U R MAP 0.0241 0.0342 M P 1 0.314 0.436 M P K =25 0.099 0.177 Measures N B R N U R MAP 0.0186 0.0133 M P 1 0.132 0.333 M P K =25 0.105 0.133 T able 1 . Left: Performance using euclidean distance, Right: Perfor- mance using cosine similarity Fig. 4 . Examples of content-based retriev al. Left: Clock Tick, Right: Brushing T eeth The variation of M P K with K is shown in Figure 3. W e observe that this metric is maximum around K=25 and hence we report the best possible performance from now on for K=25. 4.2. Results and Discussion W e first show performance with respect to queries. From table 1, we observe that the Euclidean distance performance exceeds the Cosine similarity performance in the Mean A verage Precision mea- sure. This may be due to the fact during siamese network training, euclidean distance is used to measure the closeness between two points. Hence, the learned representations are inherently designed to work better with euclidean distance. W e note that the ov erall MAP of the system is similar to what has been traditionally observed throughout audio retrie val work [29]. M P 1 value of around 0 . 3 (for N B R ) indicates that the first positive hit on an a verage is achiev ed at rank 3. Howe ver , for a gi ven specific query it can be much better . W e note that the M P 1 values are f airly high, implying that the first positiv e hit can be easily obtained using the audio embeddings generated using Siamese Netw ork. Also, note that the network N U R performs much better compared to N B R . N U R is trained using a lar ger set of pairs of dissimilar audios and hence it is able learn more discriminitiv e representations. The most important metric for understanding performance of a retriev al system is M P K . The values for M P K multiplied by K giv es us the average number of correct class instances in the top K for a query . A lo w v alue of this measure means that a lo w number of correct class instances are obtained in the top K retrieved files. W e are able to obtain fairly reasonable v alue of M P K . Fig4 gi ves visualization of a retriev al example. It sho ws two e x- amples of queries and their top 6 retrieved similar files. W e observe that for the class ’clock tick sound’, the retrie val is from classes ’clock tick sound’ and ’clock alarm sound’, which are both nearly similar audio ev ents. For the class ’brushing teeth sound’, the sys- tem performs well as their are no other similar audio classes in the database and hence it retrie ves 5 out of the 6 files correctly . Overall, it illustrates that our system is capable of deliv ering content based retriev al of audio recordings. W e now sho w performance on retriev al for some specific sound ev ents. W e sho w the a verage M P K measure over all queries of a sound ev ent class. Due to space constraints, we are not able to show performance numbers for all classes. In T able 2, we show perfor- A udio Class MP K=25 W ind Blowing 0.784 Sheep 0.753 Pig 0.724 W ater Drop 0.711 Clock T ick 0.708 Brushing T eeth 0.699 Drilling Sound 0.681 Helicopter 0.670 Chirping Birds 0.650 Rooster 0.636 A udio Class MP K=25 Dog Bark 0.110 Car Horn 0.272 Crackling Fire 0.276 Glass Breaking 0.312 Can Opening 0.314 Crying Baby 0.315 Gun Shot 0.318 Crickets(insect) 0.41 Banging Residential Area 0.42 Children Playing 0.44 T able 2 . Left: Classes (T op 10) with highest precisions, Right:Classes (bottom 10) with least precision Fig. 5 . TSNE plot for 3 classes- Clock T ick Sound, Brushing T eeth Sound, Pig Sound mance for 20 sound ev ents, 10 with highest M P K values and 10 with lowest M P K values. First, we note that for several classes we are able to obtain reasonably high performance using our learned representations. For example, for W ind Blowing , around 20 out of the top 25 retrie val actually belong to the sound class wind blo wing. Howe ver , we also observe that some audio classes ha ve unusually low av erage precisions. This occurs because we combine the labels of different datasets, there were some similar e vents classes which are semantically same but were treated as separate classes like ’Dog bark sound’ and ’Dog sound’ and ’Car horn sound’ and ’Car pass- ing by residential area’. Hence, the problem is more of how a sound ev ent is referred to as instead of the actual representation we obtain from our method. W e are acti vely in vestigating this problem of sim- ilar audio ev ents with minor dif ferences in text labels and will be addressing this in our future work. Figure 5 sho ws that the visualization of 2 dimensional t-SNE embeddings for the 3 classes. For the purpose of clarity , we in- cluded only 3 classes in the plot. Once can see that the represen- tations learned for audios are actually encoding semantic content as audios of same class cluster close to each other . This demonstrates that the proposed Siamese Network based representations inherently indistinguish between distinct audio ev ents. 5. CONCLUSIONS W e proposed a novel approach that uses Siamese Neural Network to learn representations for audios. Our results indicate that these representations are able to capture semantic similarity between au- dio containing same ev ents. This makes them well suited for content based retrie val of audio. W e observe that for sev eral classes, the pre- cision of top 25 results is very high. W e tried different measures of similarity lik e con ventional euclidean distance and Cosine similarity and found that the performance of both of them is similar on re- triev al of similar semantic sounds. This shows that the embeddings obtained from the Siamese Neural Network capture the similarity between clips belonging to the audio events v ery well and can be used for efficient content-based audio retrie val tasks. 6. REFERENCES [1] Anurag Kumar , Rita Singh, and Bhiksha Raj, “Detecting sound objects in audio recordings, ” in Signal Pr ocessing Confer ence (EUSIPCO), 2014 Pr oceedings of the 22nd European . IEEE, 2014, pp. 905–909. [2] Liwei W ang, Y in Li, and Svetlana Lazebnik, “Learning deep structure-preserving image-text embeddings, ” pp. 5005–5013, 06 2016. [3] Eng-Jon Ong, Syed Husain, and Mirosla w Bober , “Siamese network of deep fisher-v ector descriptors for image retrieval, ” 02 2017. [4] Y onggang Qi, Y i-Zhe Song, Honggang Zhang, and Jun Liu, “Sketch-based image retriev al via siamese con volutional neural network, ” pp. 2460–2464, 09 2016. [5] Erling W old, Thom Blum, Douglas K eislar , and James Wheaten, “Content-based classification, search, and retriev al of audio, ” IEEE multimedia , vol. 3, no. 3, pp. 27–36, 1996. [6] M. A. Case y , R. V eltkamp, M. Goto, M. Leman, C. Rhodes, and M. Slaney , “Content-based music information retrieval: Current directions and future challenges, ” Pr oceedings of the IEEE , vol. 96, no. 4, pp. 668–696, April 2008. [7] Michael S. Lew , Nicu Sebe, Chabane Djeraba, and Ramesh Jain, “Content-based multimedia information retrie val: State of the art and challenges, ” ACM T rans. Multimedia Comput. Commun. Appl. , vol. 2, no. 1, pp. 1–19, Feb . 2006. [8] Jonathan T Foote, “Content-based retriev al of music and au- dio, ” in Multimedia Storag e and Ar chiving Systems II . Interna- tional Society for Optics and Photonics, 1997, vol. 3229, pp. 138–148. [9] Gal Chechik, Eugene Ie, Martin Rehn, Samy Bengio, and Dick L yon, “Large-scale content-based audio retriev al from text queries, ” in Pr oceedings of the 1st A CM International Con- fer ence on Multimedia Information Retrieval , New Y ork, NY , USA, 2008, MIR ’08, pp. 105–112, A CM. [10] N. M. Patil and M. U. Nemade, “Content-based audio classifi- cation and retriev al: A nov el approach, ” in 2016 International Confer ence on Global T rends in Signal Processing , Informa- tion Computing and Communication (ICGTSPICC) , Dec 2016, pp. 599–606. [11] D. Stowell, D. Giannoulis, E. Benetos, M. Lagrange, and M. D. Plumbley , “Detection and classification of acoustic scenes and ev ents, ” IEEE T ransactions on Multimedia , vol. 17, pp. 1733– 1746, 2015. [12] D. Ellis, “Rob ust landmark-based audio fingerprinting, ” 09 2009. [13] Jaap Haitsma and T on Kalker , “ A highly robust audio finger- printing system., ” in Ismir , 2002, vol. 2002, pp. 107–115. [14] A very W ang et al., “ An industrial strength audio search algo- rithm., ” in Ismir . W ashington, DC, 2003, v ol. 2003, pp. 7–13. [15] Barry G Sherlock, DM Monro, and K Millard, “Fingerprint en- hancement by directional fourier filtering, ” IEE Pr oceedings- V ision, Image and Signal Pr ocessing , v ol. 141, no. 2, pp. 87– 94, 1994. [16] Pedro Cano, Markus Koppenber ger , and Nicolas W ack, “Content-based music audio recommendation, ” in Pr oceedings of the 13th annual ACM international confer ence on Multime- dia . A CM, 2005, pp. 211–212. [17] Courtenay V Cotton and Daniel PW Ellis, “ Audio finger- printing to identify multiple videos of an event, ” in Acoustics Speech and Signal Processing (ICASSP), 2010 IEEE Interna- tional Conference on . IEEE, 2010, pp. 2386–2389. [18] James P Ogle and Daniel PW Ellis, “Fingerprinting to identify repeated sound e vents in long-duration personal audio record- ings, ” in Acoustics, Speech and Signal Pr ocessing, 2007. ICASSP 2007. IEEE International Conference on . IEEE, 2007, vol. 1, pp. I–233. [19] Xiaolong W ang and Abhinav Gupta, “Unsupervised learning of visual representations using videos, ” in Proceedings of the IEEE International Conference on Computer V ision , 2015, pp. 2794–2802. [20] Jonas Mueller and Aditya Thyagarajan, “Siamese recurrent architectures for learning sentence similarity ., ” in AAAI , 2016, pp. 2786–2792. [21] Jane Bromley , Isabelle Guyon, Y ann LeCun, Eduard S ¨ ackinger , and Roopak Shah, “Signature verification using a” siamese” time delay neural network, ” in Advances in Neural Information Pr ocessing Systems , 1994, pp. 737–744. [22] Colin Raffel and Daniel PW Ellis, “Large-scale content-based matching of midi and audio files., ” in ISMIR , 2015, pp. 234– 240. [23] Neil Zeghidour , Gabriel Synnaeve, Nicolas Usunier , and Em- manuel Dupoux, “Joint learning of speaker and phonetic simi- larities with siamese networks., ” in INTERSPEECH , 2016, pp. 1295–1299. [24] Ke Chen and Ahmad Salman, “Extracting speaker-specific in- formation with a regularized siamese deep network, ” in Ad- vances in Neural Information Pr ocessing Systems , 2011, pp. 298–306. [25] Raia Hadsell, Sumit Chopra, and Y ann LeCun, “Dimensional- ity reduction by learning an inv ariant mapping, ” in Computer vision and pattern recognition, 2006 IEEE computer society confer ence on . IEEE, 2006, vol. 2, pp. 1735–1742. [26] Karol J Piczak, “En vironmental sound classification with con volutional neural networks, ” in 2015 IEEE 25th Interna- tional W orkshop on Mac hine Learning for Signal Pr ocessing (MLSP) . IEEE, 2015, pp. 1–6. [27] J. Salamon, C. Jacoby , and J. P . Bello, “ A dataset and tax- onomy for urban sound research, ” in 22st ACM International Confer ence on Multimedia (ACM-MM’14) , Orlando, FL, USA, Nov . 2014. [28] Annamaria Mesaros, T oni Heittola, and T uomas V irtanen, “TUT database for acoustic scene classification and sound ev ent detection, ” in 24th Eur opean Signal Pr ocessing Con- fer ence 2016 (EUSIPCO 2016) , Budapest, Hungary , 2016. [29] C. Buckley and E. V oorhees, “Retriev al e valuation with incom- plete information, ” in Pr oceedings of the 27th annual interna- tional ACM SIGIR confer ence on Resear ch and development in information retrie val . A CM, 2004, pp. 25–32.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment