Monaural Singing Voice Separation with Skip-Filtering Connections and Recurrent Inference of Time-Frequency Mask
Singing voice separation based on deep learning relies on the usage of time-frequency masking. In many cases the masking process is not a learnable function or is not encapsulated into the deep learning optimization. Consequently, most of the existin…
Authors: Stylianos Ioannis Mimilakis, Konstantinos Drossos, Jo~ao F. Santos
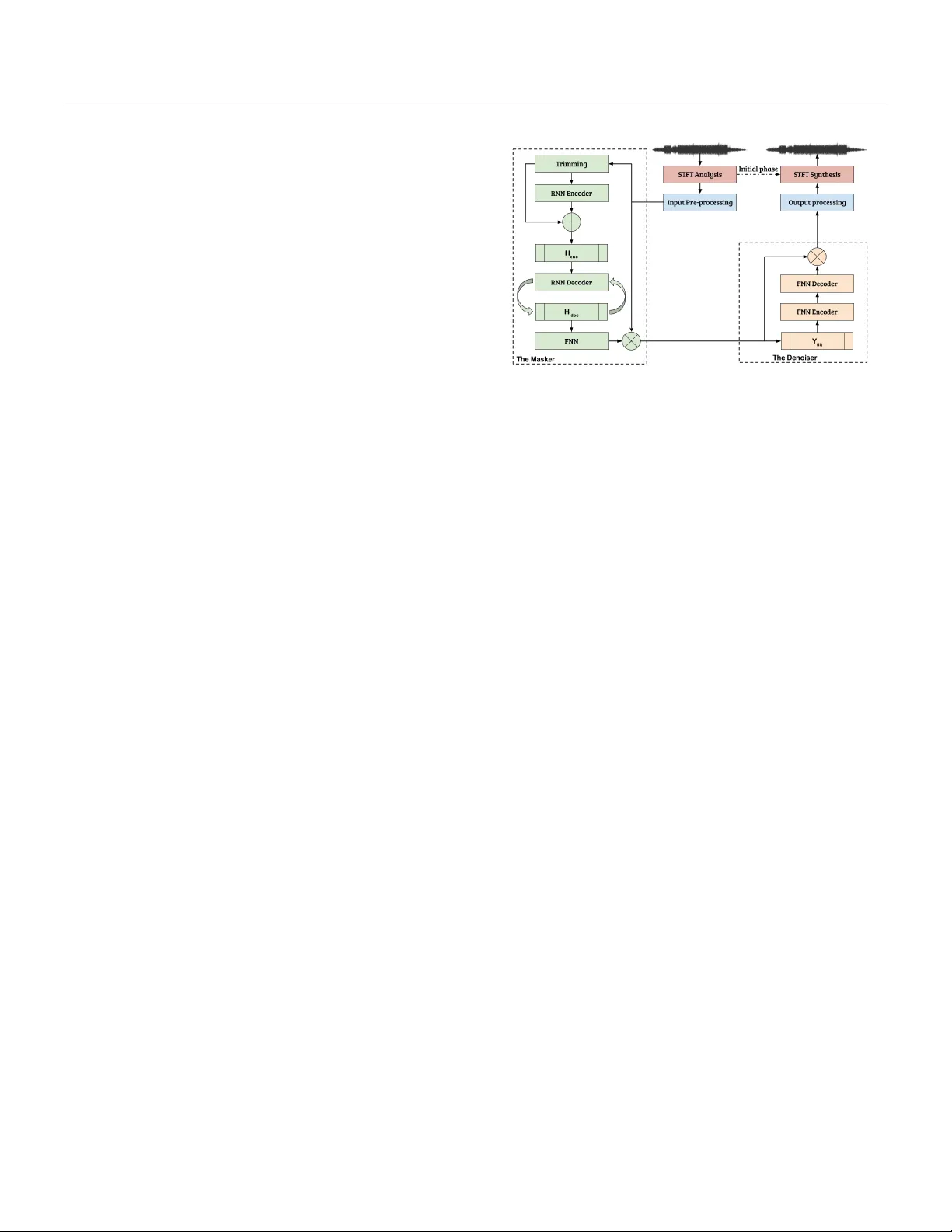
Monaural Singing V oice Separation with Skip-Filtering Connections and Recurren t Inference of Time-F requency Mask St ylianos Ioannis Mimilakis ∗ , Konstantinos Drossos † , Jo˜ ao F. Santos §‡ , Gerald Sch uller ∗ , T uomas Virtanen † , Y osh ua Bengio §¶ ∗ F raunhofer IDMT, Ilmenau, Germany † T amp ere Universit y of T echnology , T ampere, Finland § Univ ersit´ e de Mon tr ´ eal, Mon treal, Canada ‡ INRS-EMT, Montreal, Canada ¶ CIF AR F ello w Abstract Singing voic e sep ar ation b ase d on de ep le arning r elies on the usage of time-fr e quency masking. In many c ases the masking pr o c ess is not a le arnable function or is not enc apsulate d into the deep le arning optimization. Conse quently, most of the existing metho ds r ely on a p ost pr oc essing step using the generalize d Wiener filtering. This work pr op oses a metho d that le arns and optimizes (during tr aining) a sour c e-dep endent mask and do es not ne e d the afor ementione d p ost pr o c essing step. We intr o duc e a r e curr ent infer enc e algorithm, a sp arse tr ansformation step to impr ove the mask gener ation pr o c ess, and a le arne d denoising filter. Obtaine d r esults show an incr e ase of 0.49 dB for the signal to distortion r atio and 0.30 dB for the signal to interfer enc e r atio, c omp ar e d to pr evious state-of-the-art appr o aches for monaur al singing voic e sep ar ation. Keywor ds: Singing v oice separation, recurrent enco der deco der, recurrent inference, skip-filtering connections I. Intr oduction The problem of m usic source separation has received a lot atten tion in the fields of audio signal processing and deep learning [ 1 ]. The most adopted solution is the estimation of a time-v arying and source-dep endent filter, whic h is applied to the mixture [ 2 ]. Performing the filtering operation is done b y treating audio signals as wide-sense stationary . This in volv es transforming the mixture signal using the short-time F ourier transform (STFT). Then, the source-dep endent filtering op eration is applied to the complex-v alued co efficients of the mixture signal. More formally , let x b e the time-domain mixture signal v ector of J sources. Y ∈ C M × N is the complex-v alued STFT represen tation of x , comprising of M o verlapping time frames and N frequency sub-bands. The estimation of the j -th target source ( ˆ Y j ∈ C M × N ) is ac hiev ed through: ˆ Y j = Y M j , (1) where is element-wise pro duct and M j ∈ R M × N ≥ 0 is the j -th source-dependent filter, henceforth denoted as mask. In [ 2 ] w as shown that a preferred w ay for estimating the j -th source is to derive the mask through the generalized Wiener filtering using α -p o w er magnitude sp ectrograms as: M j = | ˆ Y j | ◦ α P j | ˆ Y j | ◦ α , (2) where, | · | and ◦ denote the en try-wise absolute and exponen- tiation op erators resp ectively , and α is an exp onent chosen based on the assumed distributions that the sources follow. Finding α (and thus an optimal M j for the source estimation pro cess [2]) is an op en optimization problem [2, 3]. Deep learning methods for m usic source separation are trained using synthetically created mixtures Y (adding sig- nals Y j together, i.e., knowing the target decomp osition). They can b e divided into tw o categories. In the first cate- gory , the metho ds try to predict the mask directly from the mixture magnitude sp ectrum [ 4 ] (i.e. f 1 : | Y | → M j ). This requires that an optimal M j is given (e.g. all the non-linear mixing parameters of the target source are known) during training as a target. Ho wev er, such information for the M j is unknown, and an approximation of M j is computed from the training data using Eq. (2) and empirically chosen α v alues, under the hypothesis that the source magnitude sp ectra are additiv e, whic h is not true for realistic audio signals [ 2 , 3 ]. This implies that such mo dels are optimized to predict non-optimal masks. The metho ds in the second category try to estimate all sources from the mixture(i.e. f 2 : | Y | → | ˆ Y j | ◦ α ∀ j ∈ J ) and then use these estimates to compute a mask [ 5 , 6 , 7 , 8 , 9 ]. This approach is widely adopted, since it is straightforw ard b y employing denoising auto enco ders [ 10 ], with noise corresp onding to the addition of other sources. How ever, the masks are dep enden t on the initial α -p o w er magnitude estimates of the sources ( | ˆ Y j | ◦ α ), and the mask computation is not a learned function. In- stead, the mask computation uses a deterministic function whic h takes as inputs the outcomes ( | ˆ Y j | ◦ α ∀ j ∈ J ) of deep neural net works, e.g. as in [8]. An exception to the ab ov e are the works presented in [ 11 ] and [ 12 ], where these metho ds jointly learned and optimized the masking proce sses described by Eq. (1) and (2). In [ 11 ], high w ay netw orks [ 13 ] w ere shown to b e able to approximate a masking pro cess for monaural solo source s eparation and in [ 12 ], a more robust alternativ e to [ 11 ] is presen ted. The 1 approac h in [ 12 ] uses a recurrent enco der-deco der with skip- filtering connections, which allow a source-dep enden t mask generation pro cess, applicable to monaural singing voice separation. How ever, the generated masks are not robust against interferences from other music sources, thus requir- ing a p ost-pro cessing step using the generalized Wiener filtering [12]. In this work we present a metho d for source separation that learns to generate a source-dep enden t mask which do es not require the generalized Wiener filtering as a p ost- pro cessing step. T o do so, we in tro duce a nov el recurren t inference algorithm inspired by [ 14 ] and a sparsifying trans- form [ 15 ] for generating the mask M j . The recurrent infer- ence allows the prop osed metho d to ha ve a sto chastic depth of RNNs during the mask generation process, computing hidden, latent representations whic h are presumably b etter for generating the mask. The sparsifying transform is used to approximate the mask using the output of the recurrent inference. In this metho d the mask prediction is not based on the abov e mentioned assumptions ab out the additivity of the magnitude spectrogram of the sources, is part of an optimization pro cess, and is not based on a deterministic function. Additionally , the metho d incorporates RNNs in- stead of feed-forward or conv olutional lay ers for the mask prediction. This allo ws the method to exploit the memory of the RNNs (compared to CNNs) and their efficiency for mo deling longer time dep endencies of the input data. The rest of the pap er is organized as follo ws: Section I I presen ts the proposed metho d, follow ed by Section I I I whic h pro vides information about the follo wed exp erimental pro cedure. Sec- tion IV presen ts the obtained results from the exp erimen tal pro cedure and Section V concludes this w ork. I I. Proposed Method Our prop osed metho d takes as an input the time domain samples of the mixture, and outputs time domain samples of the targeted source. The mo del consists of four parts. The first part implements the analysis and pre-pro cessing of the input. The second part generates and applies a mask, th us creating the first estimate of the magnitude spectro- gram of the targeted source. The third part enhances this estimate b y learning and applying a denoising filter, and the fourth part constructs the time domain samples of the target source. W e call the second part the “Masker” and the third the “Denoiser”. W e differentiate betw een the Masker and the Denoiser b ecause the Masker is optimized to pre- dict a time-frequency mask, whereas the Denoiser enhances the result obtained b y time-frequency masking. W e imple- men t the Mask er using a single la y er bi-directional RNN enco der ( RNN enc ), a single lay er RNN deco der ( RNN dec ), a feed-forw ard lay er (FFN), and skip-filtering connections b et w een the magnitude sp ectrogram of the mixture and the output of the FFN. W e implemen t the Denoiser using one FFN encoder ( FFN enc ), one FFN decoder ( FFN dec ), and Figure 1: Il lustr ation of our pr op ose d metho d. skip-filtering connections b etw een the input to the Denoiser and the output of the FFN dec . W e join tly train the Masker and the Denoiser using tw o criteria based on the generalized Kullbac k-Leibler div ergence ( D K L ), as it is shown in [ 3 , 16 ] to b e a robust criterion for matc hing magnitude sp ectro- grams. All RNNs are gated recurrent units (GR U). The prop osed metho d is illustrated in Figure 1. i. Input prepro cessing Let x b e the vector containing the time-domain samples of a monaural mixture from J sources, sampled at 44 . 1kHz. W e compute the STFT of x from time frames of N = 2049 samples, segmen ted with Hamming window and a hop size of 384 samples. Eac h time frame is zero-padded to N 0 = 4096. Subsequen t to the STFT w e retain only the p ositiv e frequencies, corresp onding to the first N = 2049 frequency sub-bands. This yields the complex-v alued time-frequency represen tation of x , Y ∈ C M × N , and the corresp onding magnitude | Y | ∈ R M × N ≥ 0 . W e split | Y | in B = d M /T e subsequences, with T b eing the length of the subsequence, and d·e is the ceiling function. Each subsequence b o v erlaps with the preceding one by an empirical factor of L × 2, in order to use some context information for the enco ding stage. W e use eac h subsequence b in | Y | , denoted as | Y in | as an input to the skip-filtering connections (presented later). F urthermore w e produce a lo w-bandwidth version of | Y | , whic h is used for enco ding, b y preserving only the first F = 744 frequency sub-bands at each frame yielding | Y tr | ∈ R T × F ≥ 0 | Y tr | . This operation retains information up to 8 kHz, in order to reduce the num b er of trainable parameters but preserving the most relev ant information of the singing v oice source. ii. The Masker RNN enco der W e use | Y tr | as an input to the RNN enc . The forw ard GRU of the RNN enc tak es | Y tr | as an in- put. The backw ard one takes as an input the | ← − Y tr | = [ | y tr T | , . . . , | y tr t | , . . . , | y tr 1 | ] , where | y tr t | ∈ R F ≥ 0 is a vector 2 in | Y tr | at time frame t , and ← − indicates the direction of the sequence. The outputs from the Bi-GR U h t and ← − h t are up dated at each time frame t using residual connections [ 17 ] and then concatenated as h enc t = ( h t + | y tr t | ) T , ( ← − h t + ← − | y tr t | ) T T . (3) The output of the RNN enc for all t ∈ T is denoted as H enc ∈ R T × (2 × F ) and is follow ed b y the con text information remo v al defined as: ˜ H enc = [ h enc 1+ L , h enc 2+ L , . . . , h enc T − L ], (4) yielding ˜ H enc ∈ R T 0 × (2 × F ) for T 0 = T − (2 × L ). Residual connections are used to ease the RNN training [17]. Recurren t inference and mask prediction Inspired b y recent optimization metho ds emplo ying sto chastic depth [ 14 ], we prop ose a recurrent inference algorithm that pro cesses the latent v ariables of the RNN dec whic h affect the mask generation. W e use this algorithm in order to emplo y a sto chastic depth for the net work parts resp onsible for predicting the mask, increasing the p erformance of our metho d. The recurrent inference is an iterative process and consists in reev aluating the laten t v ariables H j dec , pro duced b y the RNN dec , un til a con v ergence criterion is reac hed, thus a v oiding the need to sp ecify a fixed n umber of applications of the RNN dec . The stopping criterion is a threshold on the mean-squared-error ( L MSE ) betw een the consecutive esti- mates of H j dec , with a L MSE threshold τ term . A maximum n umber of iterations ( iter ) is used to a void having infinite iterations for conv ergence betw e en the ab ov e mentioned consecutiv e estimates. H j dec is used only for the singing v oice, i.e. j = 1. Let G j dec b e the sour c e-dep endent and trainable function of the RNN dec . The recurren t inference is p erformed using Algorithm 1. Algorithm 1 Recurren t Inference 1: S j 0 ← G j dec ( ˜ H enc ) 2: for i ∈ { 1 , . . . , iter } do 3: H j dec ← G j dec ( S j i − 1 ) 4: if L MSE ( S j i − 1 , H j dec ) < τ term then 5: T erminate the pro cess 6: S j i ← H j dec return H j dec H j dec is then given to the FFN la yer with shared weigh ts through time frames, in order to appro ximate the j -th source- dep enden t mask as: ˜ M j = ReLU ( H j dec W mask + b mask ), (5) where ReLU is the element-wise rectified linear unit func- tion pro ducing a sparse [ 15 ] approximation of the target source mask ˜ M j ∈ R T 0 × N ≥ 0 . The sparsification is p erformed in order to impro ve the interference reduction of [ 12 ]. The ReLU function can pro duce high p ositive v alues inducing distortions to the audio signal. Ho wev er, the reconstruction loss (see Eq. (9)) will alleviate that. W mask ∈ R (2 × F ) × N is the w eight matrix of the FFN comprising a dimensionality expansion up to N , in order to reco ver the original dimen- sionalit y of the data. b mask ∈ R N is the corresp onding bias term. Skip filtering connections and first estimate of the targeted source W e obtain an estimate of the magnitude sp ectrum of the target source | ˆ Y j filt | ∈ R T 0 × N ≥ 0 through the skip-filtering connections as: | ˆ Y j filt | = | ˜ Y in | ˜ M j , where (6) | Y in | =[ | y in L | , · · · , | y in T − L | ]. (7) iii. The Denoiser The output of the Mask er is likely to contain interferences from other sources [ 12 ]. The Denoiser aims to learn a denoising filter for enhancing the magnitude sp ectrogram estimated b y this masking pro cedure. This denoising filter is implemented by an enco der-deco der arc hitecture with the FFN enc and FFN dec of Fig. 1. FFN enc and FFN dec ha ve shared w eights through time frames. The final enhanced magnitude spectrogram estimate of the target source | ˆ Y j | is computed using | ˆ Y j | = ReLU ( ReLU ( | ˆ Y j filt | W enc + b enc ) W dec + b dec ) | ˆ Y j filt | , (8) where W enc ∈ R N ×b N/ 2 c and W dec ∈ R b N/ 2 c× N are the w eigh t matrices of the FFN enc and FFN dec , with the corre- sp onding biases b enc ∈ R b N/ 2 c , b dec ∈ R N , resp ectiv ely . b·c denotes the flo or function. iv. T raining details and p ost-processing W e train our metho d to minimize the ob jectiv e consisting of a reconstruction and a regularization part as: L = D K L ( | Y j | || | ˆ Y j | ) + λ rec D K L ( | Y j | || | ˆ Y j filt | ) + λ mask | diag { W mask }| 1 + λ dec || W dec || 2 2 , (9) where | Y j | is the magnitude sp ectrogram of the true source, diag {·} denotes the elemen ts on the main diagonal of a matrix, | · | 1 , and || · || 2 2 are the ` 1 v ector norm and the squared matrix L 2 norm respectively , and λ mask , and λ dec are scalars. F or λ rec the follo wing condition applies: λ rec = 1 , if D K L ( | Y j | || | ˆ Y j filt | ) ≥ τ rec and D K L ( | Y j | || | ˆ Y j | ) ≥ τ min 0 , otherwise , (10) where τ rec and τ min are hyper-parameters p enalizing the mask generation pro cess, allo wing a collab orative 3 minimization of the ov erall ob jectiv e. The usage of λ rec D K L ( | Y j | || | ˆ Y j filt | ) will ensure that M j can b e used to initially estimate the target source, whic h is then improv ed b y employing the Denoiser and D K L ( | Y j | || | ˆ Y j | ). The p enalization of the elements in the main diagonal of W mask will ensure that the generated mask is not something trivial (e.g. a voice activity detector), while the reconstruction losses using the D K L will ensure that a source-dep endent mask is generated, that minimizes the aforementioned dis- tance. The squared matrix L 2 norm is emplo yed to improv e the generalization of the mo del. By pro cessing each subsequence using the prop osed metho d, the estimates are concatenated together to form | ˆ Y j | ∈ R M × N ≥ 0 . F or the singing v oice we retrieve the complex- v alued STFT ˆ Y j =1 b y means of 10 iterations of the Griffin- Lim algorithm (least squares error estimation from mo dified STFT magnitude) [ 18 ] initialized with the mixture’s phase and using | ˆ Y j | . The time-domain samples ˆ x j =1 are obtained using in verse STFT. I I I. Experiment al Pr ocedure W e use the developmen t subset of Demixing Secret Dataset (DSD100) 1 and the non-bleeding/non-instrumen tal stems of MedleydB [ 19 ] for the training and v alidation of the prop osed metho d. The ev aluation subset of DSD100 is used for testing the ob jectiv e performance of our metho d. F or eac h multi-trac k contained in the audio corpus, a monaural v ersion of each of the four sources is generated b y av eraging the t wo av ailable c hannels. F or training, the true source | Y j | is the outcome of the ideal ratio masking pro cess [ 20 ], elemen t-wise multiplied by a factor of 2. This is p erformed to a void the inconsistencies in time delays and mixing gains b et w een the mixture signal and the singing v oice (apparent in MedleydB dataset). The length of the sequences is set to T = 60, mo deling appro ximately 0 . 5 seconds, and L = 10. The thresholds for the minimization of Eq.(9) are τ rec = 1 . 5 and τ min = 0 . 25 and the corresp onding scalars are λ mask = 1 e − 2 , and λ dec = 1 e − 4 . The hidden to hidden matrices of all RNNs were initialized using orthogonal initialization [ 21 ] and all other matrices using Glorot normal [ 22 ]. All parameters are join tly optimized using the Adam algorithm [ 23 ], with a learning rate of 1 e − 4 , ov er batches of 16, an L 2 based gradien t norm clipping equal to 0 . 5 and a total num b er of 100 ep o c hs. All of the rep orted parameters were chosen exp erimen tally with tw o random audio files dra wn from the developmen t subset of DSD100. The implemen tation is based on PyT orch 2 . W e compared our metho d with other state-of-the-art ap- proac hes dealing with monaural singing v oice separation, follo wing the standard metrics, namely signal to noise ra- tio (SIR) and signal to distortion ratio (SDR) expressed in 1 http://www.sisec17.audiolabs- erlangen.de 2 http://pytorch.org/ T able 1: Me dian SDR and SIR values in dB for the investi- gate d appr o aches. Pr op ose d appr o aches are underline d. Higher is b etter. Metho d SDR SIR Metho d SDR SIR GRA[4] -1.75 1.28 MIM-D WF + [12] 3.71 8.01 MIM-HW[11] 1.49 7.73 GRU-NRI 3.62 7.06 CHA[6] 1.59 5.20 GRU-RIS s 3.41 8.32 MIM-DWF[12] 3.66 8.02 GR U-RIS l 4.20 7.94 dB, and the rules proposed in the music source separation ev aluation campaign [ 1 ] (e.g. using the proposed toolb ox for SIR and SDR calculation). The compared metho ds are: i) GRA: Deep FFNs [ 4 ] for predicting b oth binary and soft masks [ 20 ] which are then combined to provide source estimates, ii) CHA: A con v olutional enco der-deco der for magnitude source estimation, without a trainable mask appro ximation [ 6 ] iii) MIM-HW: Deep high wa y netw orks for music source separation [ 11 ] approximating the filtering pro cess of Eq.(1), retrained using the dev elopment subset of DSD100, and iv) MIM-DWF, MIM-DWF + : The tw o GR U encoder-deco der models combined with generalized Wiener filtering [ 12 ], trained on the developmen t subset of DSD100 (MIM-GR UDWF) and the additional stems of MedleydB (MIM-D WF + ). The metho ds denoted as MIM- HW, MIM-D WF, and MIM-DWF + w ere re-implemen ted for the purposes of this work. F or the rest of the metho ds w e used their rep orted ev aluation results obtained from [ 1 ]. Our prop osed metho ds are denoted as GR U-NRI , whic h do es not include the recurren t inference algorithm, and t wo metho ds using differen t hyper-parameters for the recurrent inference algorithm: GR U-RIS s , parametrized using a max- im um num b er of iterations iter = 3, and τ term = 1 e − 2 , and GR U-RIS l parametrized using a maximum n umber of iterations iter = 10 and τ term = 1 e − 3 , which where selected according to their p erformance in minimizing Eq. (9). IV. Resul ts & Discussion T able 1 summarizes the results of the ob jective ev alua- tion for the aforemen tioned metho ds by sho wing the me- dian v alues obtained from the SDR and SIR metrics. The prop osed method based on recurren t inference and sparsi- fying transform is able to pro vide state-of-the-art results for monaural singing v oice separation, without the neces- sit y of p ost-processing steps such a s generalized Wiener filtering, and/or additionally trained deep neural netw orks. Compared to metho ds that approximate the masking pro- cesses (GRA, MIM-HW, MIM-D WF, and MIM-DWF + ) there are significant improv ements in ov erall median p erfor- mance of b oth the SDR and SIR metrics, esp ecially when the masks are not a learned function, such as in the case of CHA. Using the prop osed metho d, a gain of 0 . 49 dB for the SDR is observ ed betw een MIM-D WF + and GRU- RIS l and 0 . 30 dB for the SIR b etw een the MIM-DWF and 4 GR U-RIS s . Finally , by allowing a larger num b er of iter- ations during the recursiv e inference the mask generation p erformance and using skip-filtering connections w e see an increase in SDR which outp erforms the previous metho ds MIM-D WF and MIM-DWF + , but at the cost of a loss in SIR. A demo for the prop osed metho d is av ailable at https://js- mim.github.io/mss_pytorch/ . V. Conclusion In this work we presented an approach for singing voice separation that do es not require p ost-pro cessing using gen- eralized Wiener filtering. W e introduced to the skip-filtering connections [ 12 ] a sparsifying transform yielding compara- ble results to approaches that rely on generalized Wiener filtering. F urthermore, the introduced recurrent inference algorithm w as shown to provide state-of-the-art results in monaural singing v oice separation. Exp erimental results sho w that these extensions outp erform previous deep learn- ing based approac hes for singing voice separation. VI. A cknowledgements The researc h leading to these results has receiv ed funding from the Europ ean Union’s H2020 F ramework Programme (H2020-MSCA-ITN-2014) under grant agreement no 642685 MacSeNet. Part of the computations leading to these results w ere p erformed on a TIT AN-X GPU donated to K. Drossos from NVIDIA. The authors w ould lik e to thank Paul Magron for the precious feedbac k. References [1] A. Liutkus, F.-R. St¨ oter, Z. Rafii, D. Kitam ura, B. Rivet, N. Ito, N. Ono, and J. F on tecav e, “The 2016 signal separation ev aluation campaign,” in L atent V ariable A nalysis and Signal Sep ar ation: 13th Interna- tional Confer enc e, L V A/ICA 2017 , 2017, pp. 323–332. [2] A. Liutkus and R. Badeau, “Generalized Wiener filter- ing with fractional p ow er sp ectrograms,” in 40th Inter- national Confer enc e on A c oustics, Sp e e ch and Signal Pr o c essing (ICASSP 2015) , April 2015, pp. 266–270. [3] D. FitzGerald and R. Jaisw al, “On the use of masking filters in sound source separation,” in 15th Interna- tional Confer enc e on Digital A udio Effe cts (D AFx-12) , Septem b er 2012. [4] E.-M. Grais, G. Roma, A.J.R. Simpson, and M.-D. Plum bley , “Single-c hannel audio source separation using deep neural netw ork ensembles,” in A udio Engi- ne ering So ciety Convention 140 , May 2016. [5] S. Uhlic h, F. Giron, and Y. Mitsufuji, “Deep neural net work based instrument extraction from music,” in 40th International Confer enc e on A c oustics, Sp e e ch and Signal Pr o c essing (ICASSP 2015) , 2015, pp. 2135–2139. [6] P . C handna, M. Miron, J. Janer, and E. G´ omez, “Monoaural audio source separation using deep conv o- lutional neural netw orks,” in L atent V ariable A nalysis and Signal Sep ar ation: 13th International Confer enc e, L V A/ICA 2017 , 2017, pp. 258–266. [7] N. T ak ahashi and Y. Mitsufuji, “Multi-scale multi- band densenets for audio source separation,” in 2017 IEEE Workshop on Applic ations of Signal Pr o c essing to Audio and A c oustics (W ASP AA 2017) , Oct 2017. [8] P .-S. Huang, M. Kim, M. Hasegaw a-Johnson, and P . Smaragdis, “Joint optimization of masks and deep recurren t neural netw orks for monaural source separa- tion,” IEEE/A CM T r ansactions on Audio, Sp e e ch, and L anguage Pr o c essing , vol. 23, no. 12, pp. 2136–2147, Dec 2015. [9] A.-A. Nugraha, A. Liutkus, and E. Vincent, “Multi- c hannel m usic separation with deep neural net works,” in 24th Eur op e an Signal Pr o c essing Confer enc e (EU- SIPCO) , Aug 2016, pp. 1748–1752. [10] Y. Bengio, L. Y ao, G. Alain, and P . Vincent, “Gener- alized denoising auto-enco ders as generative mo dels,” in A dvanc es in Neur al Information Pr o c essing Systems 26 , C. J. C. Burges, L. Bottou, M. W elling, Z. Ghahra- mani, and K. Q. W einberger, Eds., pp. 899–907. Curran Asso ciates, Inc., 2013. [11] S.-I. Mimilakis, E. Cano, J. Ab eßer, and G. Sc huller, “New sonorities for jazz recordings: Separation and mix- ing using deep neural netw orks,” in A udio Engine ering So ciety 2nd Workshop on Intel ligent Music Pr o duction , 2016. [12] S.-I. Mimilakis, K. Drossos, G. Sc huller, and T. Vir- tanen, “A recurren t enco der-decoder approach with skip-filtering connections for monaural singing v oice sep- aration,” in 2017 IEEE 27th International Workshop on Machine L e arning for Signal Pr o c essing (MLSP) , 2017. [13] R.-K. Sriv astav a, K. Greff, and J. Schmidh ub er, “High- w a y netw orks,” CoRR , vol. abs/1505.00387, 2015. [14] G. Huang, Y. Sun, Z. Liu, D. Sedra, and K. Q. W ein- b erger, “Deep netw orks with sto chastic depth,” CoRR , v ol. abs/1603.09382, 2016. [15] V. P apy an, Y. Romano, and M. Elad, “Conv olutional neural netw orks analyzed via conv olutional sparse co d- ing,” Journal of Machine L e arning R ese ar ch , vol. 18, no. 83, pp. 1–52, 2017. 5 [16] A. Liutkus, D. Fitzgerald, and R. Badeau, “Cauch y nonnegativ e matrix factorization,” in 2015 IEEE Work- shop on Applic ations of Signal Pr o c essing to Audio and A c oustics (W ASP AA 2015) , Oct 2015, pp. 1–5. [17] Y. W u et al, “Go ogle’s neural machine translation system: Bridging the gap b etw een human and machine translation,” CoRR , v ol. abs/1609.08144, 2016. [18] D. Griffin and J. Lim, “Signal estimation from mo dified short-time Fourier transform,” IEEE T r ansactions on A c oustics, Sp e e ch, and Signal Pr o c essing , vol. 32, no. 2, pp. 236–243, Apr 1984. [19] R. M. Bittner, J. Salamon, M. Tierney , M. Mauch, C. Cannam, and J. P . Bello, “Medleydb: A multitrac k dataset for annotation-in tensiv e MIR researc h,” in 15th International So ciety for Music Information R etrieval (ISMIR) , Oct 2014, pp. 66–70. [20] H. Erdogan, J. R. Hershey , S. W atanab e, and J. Le Roux, “Phase-sensitive and recognition-b o osted speech separation using deep recurrent neural netw orks,” in 40th International Confer enc e on A c oustics, Sp e e ch and Signal Pr o c essing (ICASSP 2015) , April 2015, pp. 708–712. [21] A.-M. Saxe, J.-L. McClelland, and S. Ganguli, “Exact solutions to the nonlinear dynamics of learning in deep linear neural netw orks,” CoRR , vol. abs/1312.6120, 2013. [22] X. Glorot and Y. Bengio, “Understanding the difficulty of training deep feedforward neural netw orks,” in In Pr o c e e dings of the International Confer enc e on Arti- ficial Intel ligenc e and Statistics (AIST A TS’10) , 2010, pp. 249–256. [23] D.-P . Kingma and J. Ba, “Adam: A method for stochas- tic optimization,” CoRR , v ol. abs/1412.6980, 2014. 6
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment