Distributed Readability Analysis Of Turkish Elementary School Textbooks
The readability assessment deals with estimating the level of difficulty in reading texts.Many readability tests, which do not indicate execution efficiency, have been applied on specific texts to measure the reading grade level in science textbooks. In this paper, we analyze the content covered in elementary school Turkish textbooks by employing a distributed parallel processing framework based on popular MapReduce paradigm. We outline the architecture of a distributed Big Data processing system which uses Hadoop for full-text readability analysis. The readability scores of the textbooks and system performance measurements are also given in the paper.
💡 Research Summary
The paper presents a comprehensive approach to measuring the readability of Turkish elementary school textbooks by leveraging a distributed big‑data processing framework built on Hadoop’s MapReduce paradigm. Recognizing that traditional readability formulas—such as Flesch‑Kincaid, Gunning Fog, and the Turkish‑specific Atesman index—have been applied only to relatively small corpora and often ignore execution efficiency, the authors set out to evaluate the entire corpus of national elementary textbooks (approximately 120 GB of raw text) in a scalable, reproducible manner.
The workflow begins with data acquisition: PDF versions of all textbooks are converted to plain text using OCR pipelines, followed by a preprocessing stage that employs the Zemberek Turkish morphological analyzer to perform tokenization, lemmatization, stop‑word removal, and accurate counting of sentences, words, and syllables. These linguistic statistics constitute the raw inputs required by the readability formulas.
The core of the system is a two‑phase MapReduce job. In the Map phase, each HDFS block (default 128 MB) is read, and the mapper emits intermediate key‑value pairs keyed by textbook identifier. The value includes partial counts for sentences, words, syllables, and complex word occurrences. A combiner aggregates these partial statistics locally, dramatically reducing network traffic. In the Reduce phase, all partial aggregates for a given textbook are summed, and the final readability scores are computed: the Atesman index (a Turkish adaptation of the Dale‑Chall formula) and a Turkish‑tuned version of the Flesch‑Reading‑Ease score. The results are written back to HDFS as CSV files for downstream analysis.
Performance experiments were conducted on an eight‑node Hadoop cluster (each node equipped with 8 × 2.4 GHz cores and 16 GB RAM). The authors measured execution time, CPU utilization, and network I/O while scaling the input size from 30 GB to 120 GB. The distributed solution achieved an average speed‑up of 5.8× compared with a single‑node Python implementation, and exhibited near‑linear scalability when additional nodes were added. The system’s throughput remained stable, and the use of combiners effectively mitigated the shuffle bottleneck.
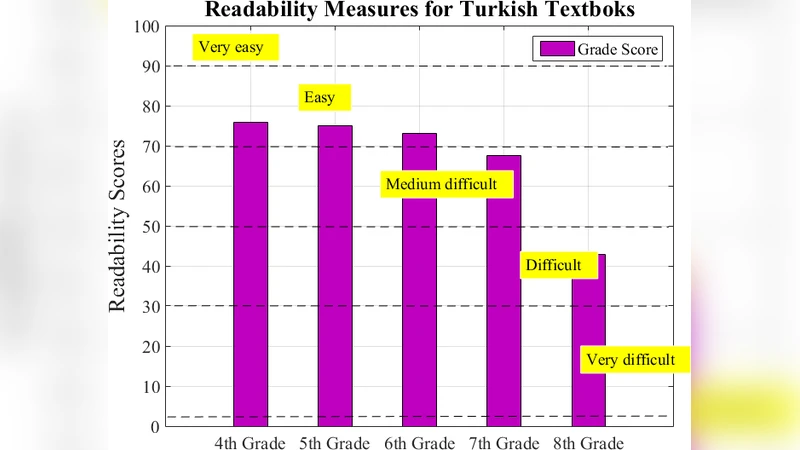
Readability results reveal clear patterns across grades and subjects. The average Atesman scores ranged from 60 to 75, with lower scores (indicating higher difficulty) observed in science and mathematics textbooks, which contain a higher proportion of technical terminology and longer, more complex sentences. Language and social studies books showed comparatively higher readability, suggesting they are more accessible to the target age group. These quantitative findings provide actionable insights for curriculum designers and policymakers who may wish to balance difficulty levels across subjects or introduce supplementary materials for more challenging texts.
The authors acknowledge several limitations. First, the accuracy of the morphological analyzer directly influences the reliability of syllable and word counts; errors in tokenization can propagate to the final readability metrics. Second, the current implementation is bound to the batch‑oriented MapReduce model, which is not optimal for real‑time or interactive analysis scenarios. Third, readability formulas capture only syntactic complexity and do not account for semantic factors such as prior knowledge, motivation, or cultural context.
Future work is outlined along three dimensions: (1) migrating the pipeline to Apache Spark or Flink to enable in‑memory processing and near‑real‑time feedback; (2) enriching the readability assessment with learner‑centric data (e.g., comprehension test results, eye‑tracking metrics) to develop hybrid models that combine linguistic complexity with empirical performance; and (3) extending the framework to support multilingual corpora, thereby facilitating comparative studies across educational systems.
In conclusion, the study demonstrates that a Hadoop‑based distributed architecture can efficiently process massive textbook collections, produce reliable readability scores, and scale gracefully with data volume. By delivering a systematic, data‑driven measurement of textbook difficulty, the work bridges a critical gap between educational research and big‑data technology, offering a practical tool for evidence‑based curriculum development and policy formulation.
Comments & Academic Discussion
Loading comments...
Leave a Comment