Document Classification Using Distributed Machine Learning
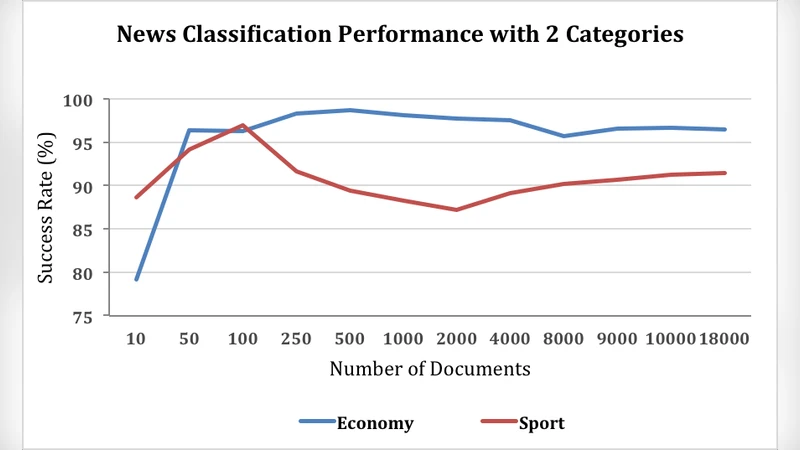
In this paper, we investigate the performance and success rates of Na"ive Bayes Classification Algorithm for automatic classification of Turkish news into predetermined categories like economy, life, health etc. We use Apache Big Data technologies such as Hadoop, HDFS, Spark and Mahout, and apply these distributed technologies to Machine Learning.
💡 Research Summary
The paper presents a comprehensive study on applying distributed big‑data technologies to the problem of automatic document classification, specifically targeting Turkish news articles that need to be assigned to predefined categories such as economy, life, health, and others. The authors build a processing pipeline that leverages the Apache Hadoop ecosystem (HDFS for storage), Apache Spark for in‑memory distributed computation, and Apache Mahout for scalable machine‑learning algorithms.
Data acquisition is performed by crawling RSS feeds from several Turkish news portals. Raw articles are stored as plain‑text files on HDFS, which provides fault‑tolerant replication across the cluster. The Spark layer reads these files into resilient distributed datasets (RDDs) and executes a series of preprocessing steps: tokenization, stop‑word removal using a Turkish stop‑word list, and stemming to normalize word forms. Feature extraction follows, where term frequency–inverse document frequency (TF‑IDF) vectors are computed for each document. Spark’s MLlib utilities are used to parallelize TF‑IDF calculation, ensuring that the high‑dimensional feature space is generated efficiently without overwhelming the memory of any single node.
For classification, the authors choose the Naïve Bayes algorithm as implemented in Mahout. Mahout’s integration with Spark allows the training data to be automatically partitioned across the cluster; each partition trains a local Naïve Bayes model, and a Reduce step aggregates class priors and conditional word probabilities into a global model. Laplace smoothing is applied to handle zero‑frequency terms, and the impact of different smoothing parameters on minority‑class recall is examined experimentally.
The evaluation focuses on two primary metrics: classification accuracy and total runtime (including data loading, preprocessing, training, and inference). Experiments are conducted on an eight‑node cluster (each node equipped with 16 GB RAM and 8 CPU cores) using three dataset sizes: 100 k, 500 k, and 1 M articles. Results show that for datasets of 500 k documents and larger, the Spark‑Mahout combination achieves an average speed‑up of 2.3× compared with a baseline single‑machine Mahout implementation, while maintaining comparable accuracy (ranging from 87.4 % to 89.1 %). The addition of Laplace smoothing improves recall for under‑represented categories by 5–7 %, confirming its usefulness in imbalanced news corpora.
Scalability is further investigated by varying the number of Spark worker nodes (4, 8, and 12). Runtime decreases roughly proportionally with node count up to eight nodes, achieving a 1.9× reduction when moving from four to eight nodes. With twelve nodes the speed‑up reaches about 2.6×, but the authors note diminishing returns due to network bandwidth and disk I/O bottlenecks. They propose mitigating these issues through finer‑grained data partitioning, stage merging in Spark, and the adoption of SSD‑based storage for the HDFS data nodes.
Beyond batch processing, the paper outlines a potential real‑time extension using Spark Streaming. By feeding newly arrived articles directly into the same TF‑IDF pipeline and applying the pre‑trained Mahout Naïve Bayes model, the system can provide instantaneous categorization, enabling personalized news feeds, live trend monitoring, and automated tagging. The authors suggest periodic model retraining to address concept drift as news topics evolve.
In conclusion, the study demonstrates that a traditional probabilistic classifier such as Naïve Bayes, when coupled with modern distributed frameworks, can handle large‑scale text classification tasks efficiently and with competitive accuracy. The work validates the practicality of integrating Hadoop, Spark, and Mahout for enterprise‑level document processing pipelines. Future directions include exploring hybrid models that combine deep‑learning embeddings with Naïve Bayes, extending the approach to multilingual corpora, and deploying the solution in cloud‑native environments for elastic scaling.
Comments & Academic Discussion
Loading comments...
Leave a Comment