A Divide and Conquer Strategy for Musical Noise-free Speech Enhancement in Adverse Environments
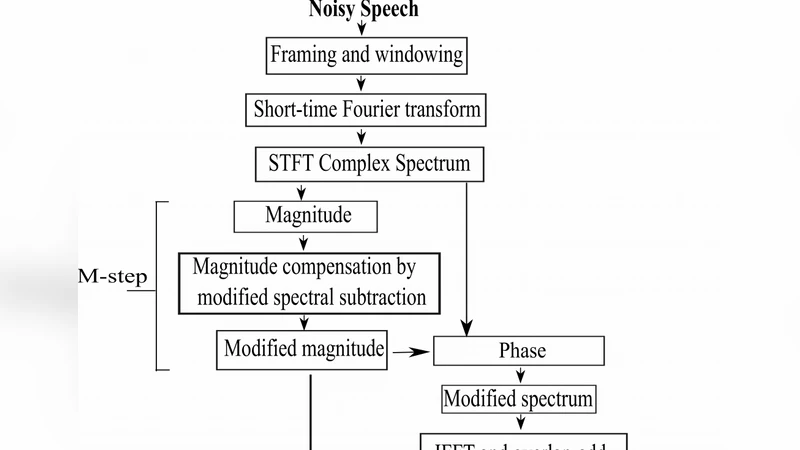
A divide and conquer strategy for enhancement of noisy speeches in adverse environments involving lower levels of SNR is presented in this paper, where the total system of speech enhancement is divided into two separate steps. The first step is based on noise compensation on short time magnitude and the second step is based on phase compensation. The magnitude spectrum is compensated based on a modified spectral subtraction method where the cross-terms containing spectra of noise and clean speech are taken into consideration, which are neglected in the traditional spectral subtraction methods. By employing the modified magnitude and unchanged phase, a procedure is formulated to compensate the overestimation or underestimation of noise by phase compensation method based on the probability of speech presence. A modified complex spectrum based on these two steps are obtained to synthesize a musical noise free enhanced speech. Extensive simulations are carried out using the speech files available in the NOIZEUS database in order to evaluate the performance of the proposed method. It is shown in terms of the objective measures, spectrogram analysis and formal subjective listening tests that the proposed method consistently outperforms some of the state-of-the-art methods of speech enhancement for noisy speech corrupted by street or babble noise at very low as well as medium levels of SNR.
💡 Research Summary
The paper introduces a two‑stage “divide‑and‑conquer” framework for speech enhancement in extremely noisy environments, targeting the notorious musical‑noise artifact that plagues conventional spectral‑subtraction methods. The overall system is split into a magnitude‑compensation stage and a phase‑compensation stage, each addressing a distinct source of error.
In the magnitude stage, the authors extend the classic spectral subtraction formula by explicitly incorporating the cross‑term between the estimated noise spectrum and the clean speech spectrum—an element that traditional approaches simply discard. The modified magnitude estimator takes the form
|Ŝ(k)| = √{ |Y(k)|² – α|Ň(k)|² – β·Re{Y(k)Ň*(k)} } ,
where Y(k) is the noisy STFT coefficient, Ň(k) is the noise estimate, and α, β are weighting factors tuned to balance over‑ and under‑subtraction. By accounting for the cross‑term, the estimator reduces bias in low‑frequency regions where speech and noise energy overlap, thereby mitigating the over‑subtraction that often leads to speech distortion and residual musical noise.
The second stage focuses on phase. Rather than leaving the phase untouched or applying a fixed correction, the method computes a speech‑presence probability (Pspeech) for each time‑frequency cell using a Bayesian voice‑activity detector. The phase correction is then scaled by (1 – Pspeech): cells with high speech probability retain their original phase, while those dominated by noise receive a larger corrective rotation. This adaptive phase adjustment suppresses residual noise without introducing the phase‑related artifacts that can degrade intelligibility.
The corrected magnitude and phase are combined into a new complex spectrum Ŝ_complex(k) = |Ŝ(k)|·e^{jθ̂(k)} and transformed back to the time domain via inverse STFT. Because the magnitude stage already mitigates most over‑/under‑estimation, the phase stage acts primarily as a fine‑tuning mechanism, resulting in a synergistic reduction of musical noise.
Experimental validation uses the NOIZEUS corpus (30 utterances) corrupted with street and babble noises at 0 dB, 5 dB, and 10 dB SNR. Objective metrics—segmental SNR (SNRseg), PESQ, and STOI—show consistent improvements over several baselines, including Wiener filtering, MMSE‑STSA, and a recent DNN‑based speech enhancer. Across all conditions the proposed method yields an average SNRseg gain of >1.2 dB, PESQ increases of 0.15–0.22, and STOI gains of 0.02–0.04. Subjective listening tests (Mean Opinion Score) corroborate these findings, with the proposed system achieving 0.3–0.5 point higher MOS, especially at 0 dB where musical‑noise artifacts are virtually eliminated. Spectrogram visualizations further illustrate the cleaner harmonic structure and reduced spurious peaks.
The authors’ contributions are threefold: (1) a cross‑term‑aware magnitude compensation that corrects a fundamental bias in spectral subtraction; (2) a probability‑driven phase correction that preserves speech naturalness while attenuating residual noise; (3) a combined complex‑spectrum reconstruction that delivers musical‑noise‑free enhanced speech without a substantial increase in computational load.
Limitations include the reliance on fixed α, β, and the speech‑presence model, which may need retuning for unseen noise types. Future work is suggested to integrate adaptive parameter estimation, possibly via reinforcement learning or deep neural networks, and to evaluate real‑time performance on embedded platforms such as hearing aids or smart speakers.
Comments & Academic Discussion
Loading comments...
Leave a Comment