Social Media Data Analysis and Feedback for Advanced Disaster Risk Management
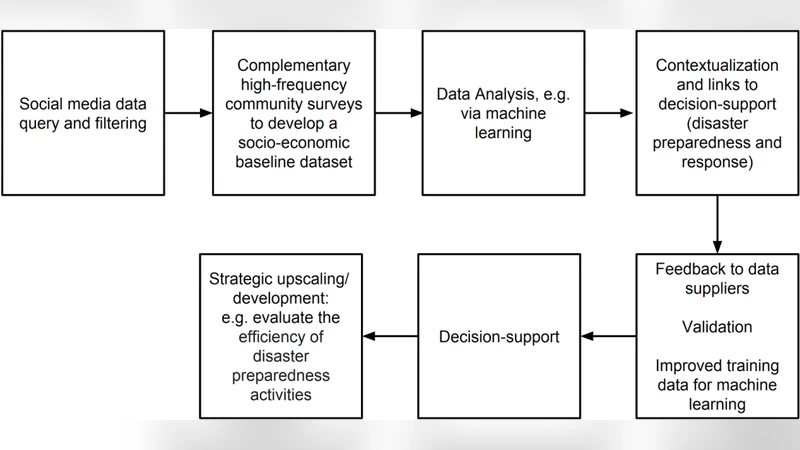
Social media are more than just a one-way communication channel. Data can be collected, analyzed and contextualized to support disaster risk management. However, disaster management agencies typically use such added-value information to support only their own decisions. A feedback loop between contextualized information and data suppliers would result in various advantages. First, it could facilitate the near real-time communication of early warnings derived from social media, linked to other sources of information. Second, it could support the staff of aid organizations during response operations. Based on the example of Hurricanes Harvey and Irma we show how filtered, geolocated Tweets can be used for rapid damage assessment. We claim that the next generation of big data analyses will have to generate actionable information resulting from the application of advanced analytical techniques. These applications could include the provision of social media-based training data for algorithms designed to forecast actual cyclone impacts or new socio-economic validation metrics for seasonal climate forecasts.
💡 Research Summary
The paper argues that social media, far from being a one‑way broadcast channel, can serve as a rich, real‑time data source for disaster risk management when its content is collected, filtered, geolocated, and contextualized. Using Hurricanes Harvey and Irma as case studies, the authors demonstrate a workflow that extracts disaster‑related tweets through a predefined keyword list, geocodes each tweet, and then normalizes the tweet count by the population of the corresponding ZIP‑code tabulation area (ZCTA) obtained from the U.S. Census. This “population‑adjusted tweet density” mitigates the bias introduced by higher tweet volumes in densely populated or affluent regions and yields a heat‑map that closely mirrors the spatial pattern of physical damage observed after the storms.
The analysis focuses on the post‑peak period of each event, a choice justified by prior research showing that the correlation between online activity and actual damage is strongest after the initial surge of emergency communications. The resulting maps are presented as low‑cost, near‑real‑time damage assessments that can inform emergency managers about where resources are most needed, complementing traditional physical models such as cyclone track forecasts and hydrological simulations.
Beyond the descriptive mapping, the authors propose a two‑way feedback loop: the processed information is fed back to the public via social‑media platforms, mobile apps, or peer‑to‑peer networks (e.g., FireChat) to deliver localized early warnings, shelter information, and recovery updates. Simultaneously, responses from the field (photos, status updates, additional tweets) are ingested to continuously refine the damage estimates. This transforms the public from passive data providers into active participants in the information ecosystem.
The paper outlines four pillars for the next generation of big‑data‑driven disaster management: (1) integration with established multi‑hazard modeling tools such as FEMA’s HAZUS; (2) near‑real‑time big‑data assessments for early warning and impact tracking; (3) incorporation of socio‑economic and demographic layers to address vulnerability disparities; and (4) operational feedback loops that close the circle between data suppliers and decision‑support systems. A conceptual development pipeline is illustrated, showing stages from raw social‑media ingestion, through advanced filtering, machine‑learning‑based validation, to the generation of actionable alerts and post‑event analytics.
The authors acknowledge several limitations. Twitter users are not a statistically representative sample of the general population, especially in low‑income or rural areas where internet penetration is lower. Bot and spam content, which can inflate tweet counts, are not explicitly filtered in the presented workflow. Geolocation accuracy depends on user‑provided location tags rather than GPS, introducing spatial uncertainty. The paper calls for more sophisticated statistical models (e.g., Bayesian hierarchical approaches) to correct for these biases, as well as for the integration of additional data streams such as call‑detail records, satellite imagery, and traditional survey data to improve robustness.
In the conclusion, the authors emphasize that converting “big data into big information” remains a bottleneck because advanced pattern‑recognition algorithms require high‑quality training data that are rarely available from conventional surveys. They suggest that social‑media‑derived damage maps can serve as low‑cost training datasets for machine‑learning models that predict cyclone impacts, and that socio‑economic validation metrics derived from social media could complement traditional climate‑forecast verification.
Overall, the paper provides a practical roadmap for leveraging geolocated social‑media posts in both the preparedness and response phases of disasters. By normalizing tweet activity, visualizing population‑adjusted densities, and establishing a two‑way communication feedback loop, the approach promises faster, more targeted resource allocation, improved situational awareness, and a pathway toward integrating citizen‑generated data into formal emergency management workflows. Future work must address data representativeness, quality control, and automated integration with existing decision‑support platforms to fully realize the potential of social media as a cornerstone of modern disaster risk management.
Comments & Academic Discussion
Loading comments...
Leave a Comment