Developing a High Performance Software Library with MPI and CUDA for Matrix Computations
Nowadays, the paradigm of parallel computing is changing. CUDA is now a popular programming model for general purpose computations on GPUs and a great number of applications were ported to CUDA obtaining speedups of orders of magnitude comparing to optimized CPU implementations. Hybrid approaches that combine the message passing model with the shared memory model for parallel computing are a solution for very large applications. We considered a heterogeneous cluster that combines the CPU and GPU computations using MPI and CUDA for developing a high performance linear algebra library. Our library deals with large linear systems solvers because they are a common problem in the fields of science and engineering. Direct methods for computing the solution of such systems can be very expensive due to high memory requirements and computational cost. An efficient alternative are iterative methods which computes only an approximation of the solution. In this paper we present an implementation of a library that uses a hybrid model of computation using MPI and CUDA implementing both direct and iterative linear systems solvers. Our library implements LU and Cholesky factorization based solvers and some of the non-stationary iterative methods using the MPI/CUDA combination. We compared the performance of our MPI/CUDA implementation with classic programs written to be run on a single CPU.
💡 Research Summary
The paper presents the design, implementation, and performance evaluation of a high‑performance linear‑algebra library that leverages a hybrid MPI‑CUDA programming model to solve large‑scale linear systems on heterogeneous clusters. Recognizing that modern scientific and engineering applications frequently involve solving very large sparse or dense systems, the authors argue that pure CPU implementations are limited by memory bandwidth and compute capacity, while GPUs offer massive parallelism but are constrained by device memory. By combining MPI for inter‑node communication with CUDA for intra‑node acceleration, the library can exploit both distributed memory and fine‑grained parallelism.
The architecture is organized in two layers. At the top level, the matrix is partitioned into two‑dimensional blocks that are distributed across MPI ranks. Each rank owns a subset of blocks and is responsible for local computation and for exchanging border data with neighboring ranks. The block distribution is static, chosen to minimize the number of MPI messages (approximately O(√P) where P is the total number of processes). At the bottom level, each rank launches CUDA kernels that perform block‑wise matrix operations (e.g., triangular solves, matrix‑matrix updates, matrix‑vector products). Overlap between host‑device data transfers and kernel execution is achieved using CUDA streams, thereby hiding PCI‑e latency.
Both direct and iterative solvers are implemented. Direct solvers include LU factorization with partial pivoting and Cholesky factorization for symmetric positive‑definite matrices. In the LU routine, each step performs a parallel search for the local pivot, followed by an MPI_Allreduce to identify the global pivot row. After row swapping, the update of the trailing submatrix is carried out by a CUDA kernel on each GPU, and the updated blocks are redistributed via MPI. The Cholesky implementation stores only the upper triangular part, reducing memory consumption by half, and uses block‑wise rank‑k updates that map efficiently onto the GPU’s shared memory hierarchy.
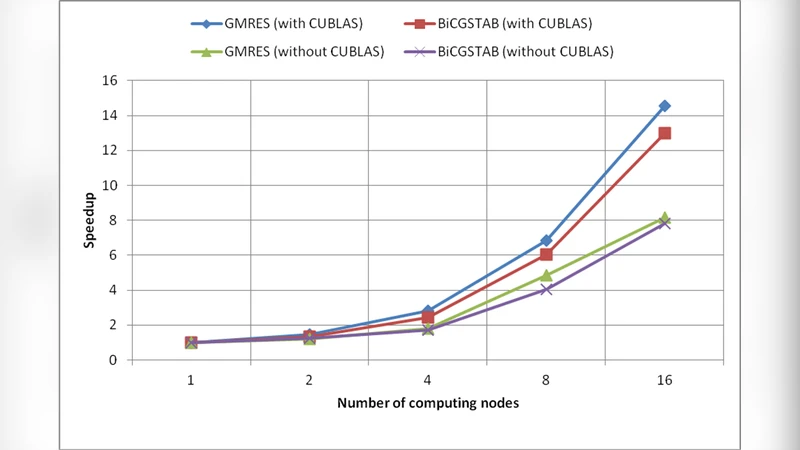
Iterative solvers cover non‑stationary Krylov‑subspace methods such as GMRES, BiCGSTAB, and the Conjugate Gradient method. These algorithms are dominated by matrix‑vector multiplications, which are offloaded to CUDA kernels. Global scalar reductions (e.g., residual norm, inner products) are performed with MPI_Allreduce, ensuring that convergence checks remain consistent across the cluster. The library allows the user to set a tolerance; the solvers stop when the residual norm falls below this threshold. Because the bulk of each iteration is performed on the GPU, the overall iteration time is dramatically reduced compared with a CPU‑only baseline.
Performance experiments were conducted on a cluster equipped with up to eight nodes, each node containing one multi‑core CPU and one NVIDIA GPU. Test matrices ranged from 10⁴ to 10⁶ unknowns, covering both dense and moderately sparse cases. For the direct solvers, the 8‑GPU configuration achieved speed‑ups of 12× on average and up to 25× for the largest problems, while also extending the solvable problem size beyond the memory limits of a single CPU node. For the iterative solvers, the hybrid implementation showed particularly strong scaling: with 8 GPUs the overall runtime was reduced by more than an order of magnitude, and the parallel efficiency remained above 85 % as the number of GPUs increased. The authors attribute this success to the reduced communication volume (thanks to block partitioning) and the high compute‑to‑communication ratio of the GPU kernels.
The paper acknowledges several limitations. Currently only single‑precision and double‑precision dense formats are supported; sparse matrix formats and mixed‑precision strategies are left for future work. The static block distribution can lead to load imbalance for highly irregular matrices, and the library does not yet exploit direct GPU‑to‑GPU (P2P) communication, which could further lower inter‑node latency. Planned extensions include dynamic load‑balancing, support for CSR/ELLPACK sparse formats, and automated tuning of block sizes based on runtime profiling.
In conclusion, the study demonstrates that a carefully engineered MPI‑CUDA hybrid approach can deliver substantial performance gains for both direct and iterative linear‑system solvers, making it a viable foundation for large‑scale scientific computing, high‑fidelity simulations, and data‑intensive machine‑learning workloads that rely heavily on matrix computations.
Comments & Academic Discussion
Loading comments...
Leave a Comment