Deep Active Learning for Named Entity Recognition
Deep learning has yielded state-of-the-art performance on many natural language processing tasks including named entity recognition (NER). However, this typically requires large amounts of labeled data. In this work, we demonstrate that the amount of labeled training data can be drastically reduced when deep learning is combined with active learning. While active learning is sample-efficient, it can be computationally expensive since it requires iterative retraining. To speed this up, we introduce a lightweight architecture for NER, viz., the CNN-CNN-LSTM model consisting of convolutional character and word encoders and a long short term memory (LSTM) tag decoder. The model achieves nearly state-of-the-art performance on standard datasets for the task while being computationally much more efficient than best performing models. We carry out incremental active learning, during the training process, and are able to nearly match state-of-the-art performance with just 25% of the original training data.
💡 Research Summary
The paper tackles two intertwined challenges in modern named‑entity recognition (NER): the heavy reliance of deep neural networks on large annotated corpora, and the prohibitive computational cost of traditional active‑learning pipelines that require full model retraining after each annotation round. To address these issues, the authors propose a lightweight “CNN‑CNN‑LSTM” architecture together with an incremental active‑learning strategy that dramatically reduces both labeling and training overhead while preserving state‑of‑the‑art performance.
Model architecture
The system consists of three components. First, a character‑level encoder built from two 1‑D convolutional layers (with ReLU, dropout, and residual connections) extracts fixed‑size sub‑word features. These are max‑pooled and concatenated with a word embedding (initialized from word2vec) to form a rich word representation. Second, a word‑level encoder also uses a shallow CNN (two layers, kernel width three) to capture local context across neighboring words. The output of each CNN layer is concatenated with the original word features, yielding the final encoder hidden states. Third, instead of the commonly used CRF tag decoder, the authors employ a unidirectional LSTM decoder that predicts tags sequentially, feeding the previously predicted tag and the next word encoder state at each step. Greedy decoding is used both during training and inference; the authors demonstrate that this yields performance comparable to a CRF while avoiding the O(n · T²) dynamic‑programming cost of CRF partition‑function computation.
Active‑learning framework
Training proceeds in multiple rounds. At the start of each round the current model scores all unlabeled sentences and selects a batch for annotation under a fixed budget (cost proportional to sentence length). After receiving the new labels, the model is updated by mixing the newly labeled sentences with the existing training set and performing a small number of additional epochs (incremental learning) rather than retraining from scratch. This dramatically cuts the GPU time required for each round.
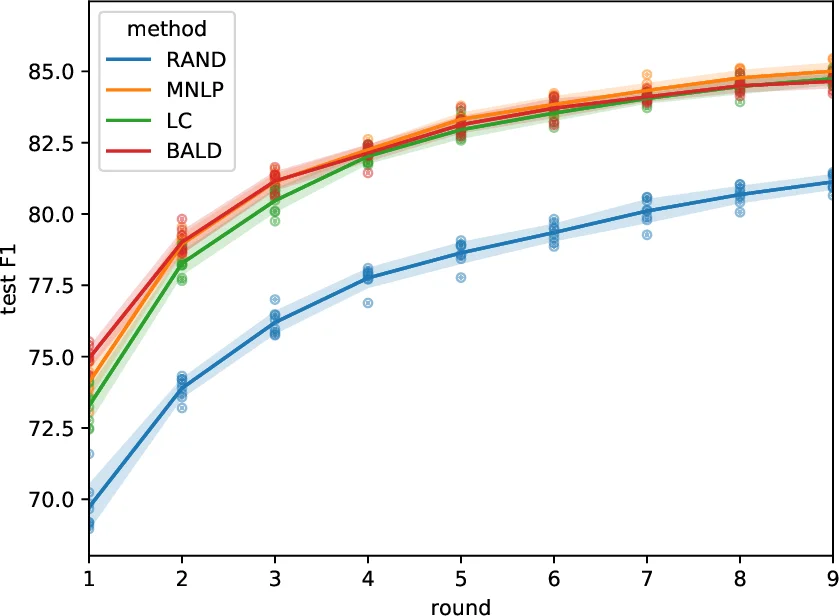
The authors explore three uncertainty‑based sampling criteria: (1) Least Confidence (LC), which ranks sentences by 1 − max_y P(y|x) using the probability of the greedy‑decoded tag sequence; (2) Maximum Normalized Log‑Probability (MNLP), a variant of LC that divides the summed log‑probabilities by sentence length to avoid a bias toward long sentences; and (3) Bayesian Active Learning by Disagreement (BALD), which estimates predictive variance via Monte‑Carlo dropout. LC and MNLP are computationally cheap (single forward pass), whereas BALD requires multiple stochastic forward passes.
Experimental evaluation
The approach is evaluated on the OntoNotes‑5.0 English and Chinese corpora (≈1.1 M words each). Baselines include recent LSTM‑CRF and CNN‑LSTM models, as well as a BALD‑based active‑learning method adapted from image classification. Results show that using only 24.9 % of the English training data the CNN‑CNN‑LSTM model attains 99 % of the F1 score achieved by the fully supervised state‑of‑the‑art system; on Chinese, 30.1 % of the data yields the same relative performance. LC and MNLP perform on par with BALD in terms of final F1, but require an order of magnitude less computation. Moreover, the proposed architecture trains 2–3× faster and consumes roughly 40 % less memory than comparable LSTM‑CRF systems, making the repeated updates in active learning feasible.
Analysis and limitations
Key contributions are (i) a fast, parameter‑efficient CNN‑CNN‑LSTM NER model that still reaches top‑tier accuracy, (ii) the MNLP scoring function that corrects the length bias inherent in raw confidence scores, and (iii) an incremental training protocol that eliminates the need for full retraining after each annotation batch. Limitations include evaluation on only two languages; the generality to morphologically richer or low‑resource languages remains untested. Additionally, greedy decoding may miss globally optimal tag sequences, suggesting that a hybrid CRF‑LSTM decoder could further improve performance.
Conclusion and future work
The study demonstrates that deep active learning for sequence tagging is practical when paired with a lightweight architecture and smart uncertainty sampling. Future directions include extending the method to multilingual and domain‑specific corpora, exploring hybrid decoders that combine the global consistency of CRFs with the speed of LSTMs, and investigating more sophisticated uncertainty estimators (e.g., entropy‑based or ensemble methods) to further reduce annotation cost while maintaining or improving accuracy.
Comments & Academic Discussion
Loading comments...
Leave a Comment