Improved Runtime Bounds for the Univariate Marginal Distribution Algorithm via Anti-Concentration
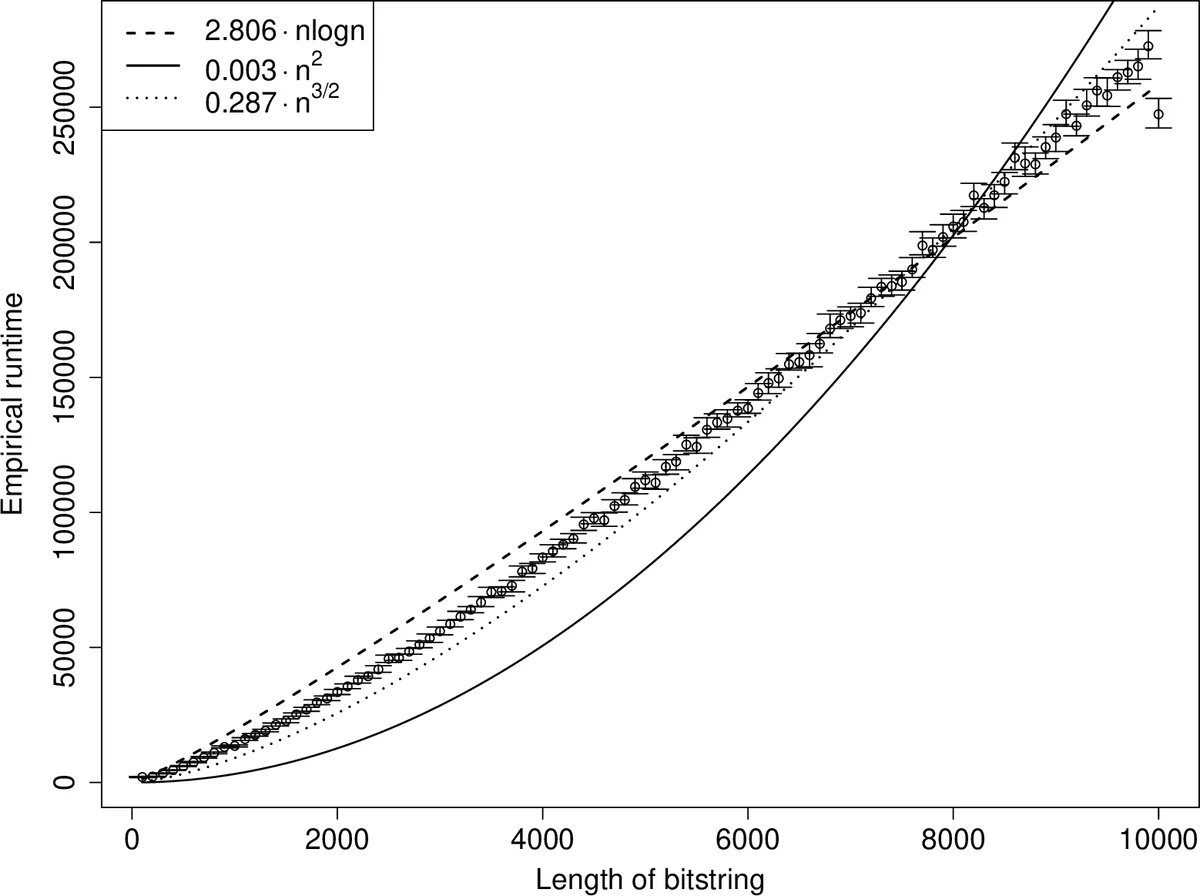
Unlike traditional evolutionary algorithms which produce offspring via genetic operators, Estimation of Distribution Algorithms (EDAs) sample solutions from probabilistic models which are learned from selected individuals. It is hoped that EDAs may improve optimisation performance on epistatic fitness landscapes by learning variable interactions. However, hardly any rigorous results are available to support claims about the performance of EDAs, even for fitness functions without epistasis. The expected runtime of the Univariate Marginal Distribution Algorithm (UMDA) on OneMax was recently shown to be in $\mathcal{O}\left(n\lambda\log \lambda\right)$ by Dang and Lehre (GECCO 2015). Later, Krejca and Witt (FOGA 2017) proved the lower bound $\Omega\left(\lambda\sqrt{n}+n\log n\right)$ via an involved drift analysis. We prove a $\mathcal{O}\left(n\lambda\right)$ bound, given some restrictions on the population size. This implies the tight bound $\Theta\left(n\log n\right)$ when $\lambda=\mathcal{O}\left(\log n\right)$, matching the runtime of classical EAs. Our analysis uses the level-based theorem and anti-concentration properties of the Poisson-Binomial distribution. We expect that these generic methods will facilitate further analysis of EDAs.
💡 Research Summary
**
The paper investigates the runtime of the Univariate Marginal Distribution Algorithm (UMDA) on the classic OneMax problem, aiming to close the gap between the best known upper and lower bounds. Previously, Dang and Lehre (GECCO 2015) proved an upper bound of O(n λ log λ) for UMDA, while Krejca and Witt (FOGA 2017) established a lower bound of Ω(λ √n + n log n). The authors improve the upper bound to O(n λ) under specific population‑size constraints, thereby eliminating the logarithmic factor and achieving a tight Θ(n log n) bound when the offspring population size λ = O(log n). This matches the well‑known runtime of the (1+1) Evolutionary Algorithm on linear functions.
Key methodological contributions
-
Level‑Based Theorem – The analysis is built on the level‑based theorem, a generic tool that provides expected runtime bounds for population‑based algorithms. The search space is partitioned into “levels” A₁,…,A_m, where each level corresponds to a set of solutions with the same OneMax fitness. The theorem requires three conditions:
- (G1) A lower bound z_j on the probability that, given at least a fraction γ₀ of the current population in level ≥ j, the next offspring belongs to level ≥ j+1.
- (G2) An amplification condition: if a fraction γ₀ of the population is at level ≥ j and a fraction γ of the population is already at level ≥ j+1, then the probability of producing a level ≥ j+1 offspring is at least (1 + δ)γ.
- (G3) A minimal population size λ that depends on γ₀, δ, and the smallest z_j.
Satisfying these conditions yields an explicit bound on the expected number of generations until an optimal individual appears.
-
Anti‑Concentration for Poisson‑Binomial Sums – Each offspring’s number of 1‑bits Y is the sum of independent Bernoulli variables with success probabilities p_i (the current marginal probabilities). The distribution of Y is Poisson‑binomial with mean μ = Σ p_i and variance σ² = Σ p_i(1 − p_i). The authors employ a sharp upper bound on point probabilities (σ·Pr(Y = y) ≤ η, η ≈ 0.4688) from Roos (2000) and Feige’s inequality (Pr(Y ≥ μ − Δ) ≥ min{1/13, Δ/(1 + Δ)}). These results guarantee that Y does not concentrate excessively on any single value, which in turn provides a strong lower bound on the probability of moving to a higher level.
-
Parameter Regime – The analysis assumes a parent population size µ satisfying c·log n ≤ µ = O(√n) for some constant c > 0, and an offspring size λ = Ω(µ). Under these settings the margins (lower/upper bounds on p_i) stay within
Comments & Academic Discussion
Loading comments...
Leave a Comment