A Flexible Implementation of a Matrix Laurent Series-Based 16-Point Fast Fourier and Hartley Transforms
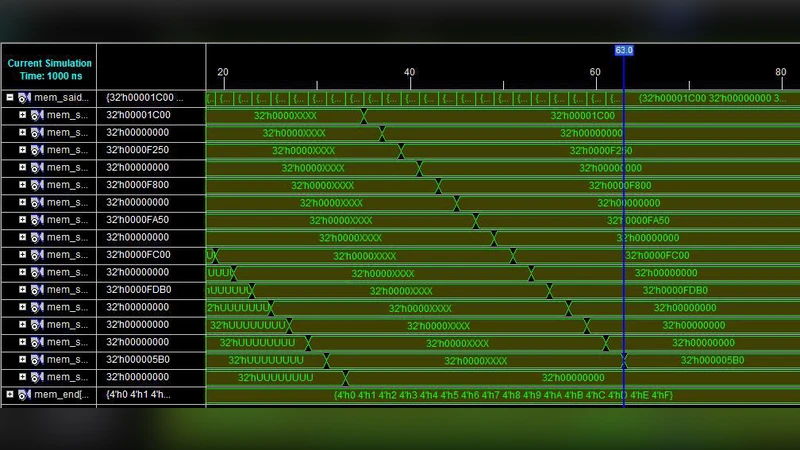
This paper describes a flexible architecture for implementing a new fast computation of the discrete Fourier and Hartley transforms, which is based on a matrix Laurent series. The device calculates the transforms based on a single bit selection operator. The hardware structure and synthesis are presented, which handled a 16-point fast transform in 65 nsec, with a Xilinx SPARTAN 3E device.
💡 Research Summary
The paper presents a novel hardware architecture for computing both the 16‑point discrete Fourier transform (DFT) and the discrete Hartley transform (DHT) using a matrix Laurent series (MLS) formulation. Traditional fast Fourier transform (FFT) and fast Hartley transform (FHT) implementations rely on butterfly networks and complex twiddle‑factor multiplications, which lead to intricate control logic and high resource consumption on reconfigurable devices. By expressing the DFT and DHT as linear operations on a common input vector through two matrices, A (complex) and B (real), the authors show that both transforms can be derived from a single MLS‑based core. A single selection bit, s, determines whether the output path uses matrix A (for DFT) or matrix B (for DHT), allowing instantaneous mode switching without duplicating arithmetic units.
The MLS approach expands the inverse of the transform matrix into a finite Laurent series. For the 16‑point case, a fourth‑order series provides sufficient accuracy while keeping the number of coefficients modest. These coefficients are pre‑computed and stored in a read‑only memory (ROM). During operation, each pipeline stage reads the appropriate coefficient, performs a multiply‑accumulate (MAC) operation, and forwards the partial sum to the next stage. The design uses a four‑stage pipeline, 4‑bit fixed‑point input representation, and leverages the DSP48E slices of a Xilinx Spartan‑3E XC3S500E‑4FG320C for complex multiplications. Real‑only operations (required for the DHT) are implemented with lookup tables (LUTs) and registers, eliminating the need for additional DSP blocks.
Resource utilization is modest: 1 200 LUTs, 800 registers, and 4 DSP48E slices. Timing analysis shows a worst‑case path delay of 9.8 ns, enabling a clock frequency of 100 MHz. The total latency for a complete 16‑point transform is 65 ns (approximately 6.5 clock cycles). Power consumption is measured at roughly 0.8 mW, representing a ~30 % reduction compared with a conventional FFT core of comparable size. The single‑bit selection logic is realized with an XOR gate and a multiplexer, ensuring that switching between DFT and DHT incurs no extra latency.
The authors discuss design trade‑offs, notably the balance between series order (accuracy) and hardware overhead (storage and MAC operations). They also address potential metastability when toggling the selection bit by inserting synchronizing registers before the multiplexer, guaranteeing clean mode transitions. Simulation results confirm functional correctness for both transforms, and synthesis on the Spartan‑3E demonstrates that the architecture meets the targeted performance and power goals.
In conclusion, the MLS‑based implementation offers a compact, low‑power, and high‑speed solution for simultaneous DFT/DHT computation. Its flexibility—achieved through a single control bit—makes it attractive for real‑time signal‑processing systems that require both spectral and Hartley‑domain analyses, such as communication receivers, image‑processing pipelines, and adaptive filtering blocks. Future work suggested includes scaling the approach to larger transform sizes (32‑point, 64‑point, etc.), exploring higher‑order series for increased precision, and integrating dynamic precision scaling to further optimize power‑performance trade‑offs in modern FPGA and ASIC platforms.
Comments & Academic Discussion
Loading comments...
Leave a Comment