Conversational AI: The Science Behind the Alexa Prize
Conversational agents are exploding in popularity. However, much work remains in the area of social conversation as well as free-form conversation over a broad range of domains and topics. To advance the state of the art in conversational AI, Amazon launched the Alexa Prize, a 2.5-million-dollar university competition where sixteen selected university teams were challenged to build conversational agents, known as socialbots, to converse coherently and engagingly with humans on popular topics such as Sports, Politics, Entertainment, Fashion and Technology for 20 minutes. The Alexa Prize offers the academic community a unique opportunity to perform research with a live system used by millions of users. The competition provided university teams with real user conversational data at scale, along with the user-provided ratings and feedback augmented with annotations by the Alexa team. This enabled teams to effectively iterate and make improvements throughout the competition while being evaluated in real-time through live user interactions. To build their socialbots, university teams combined state-of-the-art techniques with novel strategies in the areas of Natural Language Understanding, Context Modeling, Dialog Management, Response Generation, and Knowledge Acquisition. To support the efforts of participating teams, the Alexa Prize team made significant scientific and engineering investments to build and improve Conversational Speech Recognition, Topic Tracking, Dialog Evaluation, Voice User Experience, and tools for traffic management and scalability. This paper outlines the advances created by the university teams as well as the Alexa Prize team to achieve the common goal of solving the problem of Conversational AI.
💡 Research Summary
The paper presents a comprehensive overview of the Alexa Prize competition, a $2.5 million university challenge launched by Amazon to accelerate research in conversational artificial intelligence. Sixteen university teams were tasked with building “socialbots” capable of sustaining coherent, engaging, and topic‑rich dialogues for up to twenty minutes with real Alexa users. The competition uniquely combined a live user base of millions, large‑scale conversational data, and continuous human feedback to create a realistic research environment.
The authors first describe the dual customer‑experience (CX) strategy. For end‑users, a simple invocation phrase (“Alexa, let’s chat”) and a brief introductory script lowered the barrier to entry. After each conversation, users supplied a one‑to‑five star rating and free‑form voice feedback; the system was later enhanced to recognize fractional ratings (e.g., “three and a half”) by fine‑tuning the speech recognizer. For university teams, Amazon provided extensive resources: free AWS compute and storage, a custom conversational ASR model with n‑best hypotheses and token‑level confidence scores, access to a live news API, and the CAPC dataset (frequently asked questions derived from real user interactions). Teams also received curated evaluation reports, bi‑weekly office hours with Alexa engineers, and a dedicated Slack channel for on‑demand support.
A modular “Socialbot Management Framework” was built around the Alexa Skills Kit. The “Links” architecture coordinated multi‑stage skill handoffs: user invocation → random socialbot selection → dialogue → feedback collection. An uptime monitoring system combined passive failure detection with active synthetic traffic to each bot, automatically removing unresponsive bots from the user pool and re‑activating them after a six‑hour cooldown. Traffic allocation was initially uniform across the fifteen bots, then shifted to a rating‑driven routing during semifinals and finals to prioritize higher‑quality experiences.
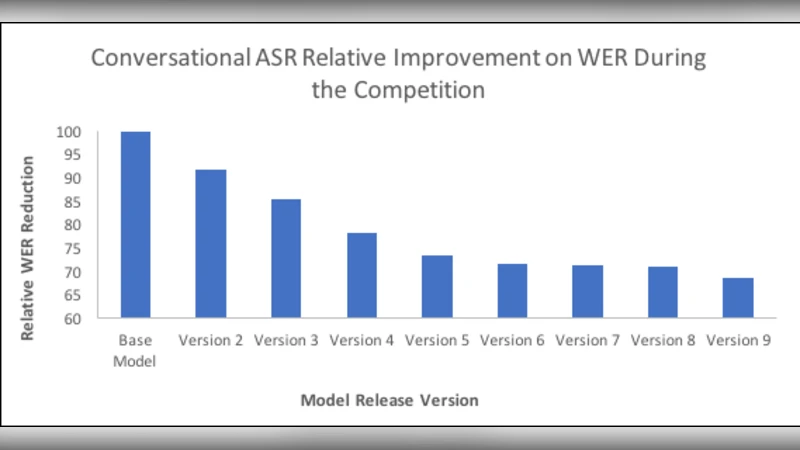
Technical infrastructure improvements are detailed. The Conversational ASR model was extended for longer utterances and provided confidence metrics to aid downstream NLU error analysis. While teams could use the default ASK NLU, they were encouraged to develop custom intent classifiers, entity extractors, and multi‑turn context trackers. Real‑time topic tracking leveraged the live news feed and CAPC to surface current events, enabling bots to stay up‑to‑date. Evaluation metrics went beyond simple star ratings, incorporating median and 90th‑percentile conversation length, average turn count, topic‑shift frequency, and profanity‑filter success rates. These multidimensional measures allowed a nuanced assessment of coherence, relevance, and user engagement.
Over the competition period (May 8 – November 7 2017), more than 40,000 hours of conversation and millions of interactions were logged. Teams iteratively refined their models using the daily feedback loop, experimenting with state‑of‑the‑art techniques such as Transformer‑based language models, reinforcement‑learning policy optimization, knowledge‑graph‑driven response generation, and commonsense reasoning modules. The Alexa team concurrently upgraded the ASR engine, topic‑tracking algorithms, and dialog‑quality evaluation models, creating a virtuous cycle of improvement.
The paper concludes that the Alexa Prize successfully established a large‑scale, real‑world testbed for conversational AI, addressing longstanding challenges of data scarcity, realistic evaluation, and system scalability. While the twenty‑minute dialogue goal remains ambitious, the competition demonstrated that with robust infrastructure, continuous user feedback, and interdisciplinary collaboration, significant progress can be made toward long‑form, multi‑domain, and personalized conversational agents. Future work is suggested in automated, objective quality metrics, deeper personalization, and extending the evaluation framework to capture nuanced aspects of human‑bot interaction.
Comments & Academic Discussion
Loading comments...
Leave a Comment