Optimizing Channel Selection for Seizure Detection
Interpretation of electroencephalogram (EEG) signals can be complicated by obfuscating artifacts. Artifact detection plays an important role in the observation and analysis of EEG signals. Spatial information contained in the placement of the electrodes can be exploited to accurately detect artifacts. However, when fewer electrodes are used, less spatial information is available, making it harder to detect artifacts. In this study, we investigate the performance of a deep learning algorithm, CNN-LSTM, on several channel configurations. Each configuration was designed to minimize the amount of spatial information lost compared to a standard 22-channel EEG. Systems using a reduced number of channels ranging from 8 to 20 achieved sensitivities between 33% and 37% with false alarms in the range of [38, 50] per 24 hours. False alarms increased dramatically (e.g., over 300 per 24 hours) when the number of channels was further reduced. Baseline performance of a system that used all 22 channels was 39% sensitivity with 23 false alarms. Since the 22-channel system was the only system that included referential channels, the rapid increase in the false alarm rate as the number of channels was reduced underscores the importance of retaining referential channels for artifact reduction. This cautionary result is important because one of the biggest differences between various types of EEGs administered is the type of referential channel used.
💡 Research Summary
This paper investigates how reducing the number of EEG channels affects the performance of an automatic seizure detection system based on a hybrid convolutional neural network–long short‑term memory (CNN‑LSTM) architecture. Using the publicly available Temple University Hospital (TUH) EEG Seizure Corpus (TUSZ), which contains recordings with a standard 22‑channel 10‑20 montage, the authors systematically create reduced‑channel configurations (20, 16, 8, 4, and 2 channels) while trying to preserve as much spatial information as possible.
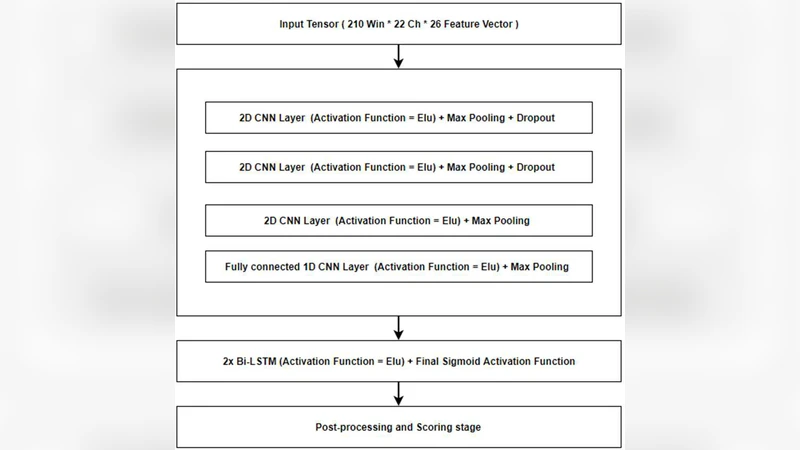
Feature extraction is performed with traditional linear frequency cepstral coefficients (LFCCs) and their first‑ and second‑order derivatives, computed on 0.1‑second frames (0.2‑second analysis windows). Each frame yields a 26‑dimensional feature vector per channel, forming a 22 × 26 input tensor for the full‑channel system. The deep model consists of three 2‑D convolutional layers (3 × 3 kernels, 16 filters each) with 2 × 2 max‑pooling, followed by a 1‑D convolutional (fully‑connected) block and a bidirectional LSTM. ELU activations are used throughout except for a final sigmoid output; training employs mean‑square error loss and the Adam optimizer, with dropout applied to mitigate over‑fitting.
Channel reduction is guided by domain knowledge. The first step removes the ear‑referential channels A1 and A2, yielding a 20‑channel configuration. Subsequent steps drop channels that contribute less to seizure detection (e.g., frontal polar FP1/FP2, certain temporal sites) to obtain 16‑, 8‑, 4‑, and 2‑channel sets. Because very low‑dimensional tensors cannot be processed with the same pooling strategy, the authors either keep the tensor shape unchanged or eliminate one or more CNN layers for the 4‑ and 2‑channel models.
Experimental results (Table 1) show that the full 22‑channel system achieves 39.15 % sensitivity, 90.37 % specificity, and 22.83 false alarms per 24 h—a strong baseline. The 20‑channel system drops to 34.54 % sensitivity and nearly doubles false alarms (49.25/24 h). The 16‑channel configuration recovers some sensitivity (36.54 %) but still yields ~54 false alarms. The 8‑channel model attains 33.44 % sensitivity with 38.19 false alarms, while the 4‑ and 2‑channel setups suffer dramatic degradation, producing >300 false alarms per day. ROC curves confirm that the 22‑channel system dominates at low false‑positive rates, which are most clinically relevant.
A key contribution is the analysis of referential (A1/A2, denoted Ax) channels. By comparing configurations with and without Ax (Table 2, Figures 5‑6), the authors demonstrate that even when the total channel count is held constant, adding the referential channels improves sensitivity by 3‑5 % and markedly reduces false alarms, especially in the low‑FPR region. This suggests that referential channels provide essential information for noise cancellation and for distinguishing true seizure patterns from artifacts such as muscle activity or electrode pops.
The paper also discusses practical challenges: model performance is highly sensitive to weight initialization and data shuffling; low‑channel systems require architectural adjustments (e.g., fewer CNN layers) to avoid dimensionality collapse. Consequently, a one‑size‑fits‑all deep‑learning pipeline is infeasible across heterogeneous EEG setups, and careful per‑configuration tuning is mandatory.
In summary, the study confirms that (1) preserving spatial context through thoughtful channel selection mitigates performance loss when reducing electrodes, (2) retaining referential channels is crucial for maintaining low false‑alarm rates, and (3) deep‑learning models must be adapted for low‑dimensional inputs. Future work is proposed to develop architectures that are robust to the absence of referential channels and to explore meta‑learning strategies that automatically select optimal channel subsets for diverse clinical environments.
Comments & Academic Discussion
Loading comments...
Leave a Comment