Near Optimal Coded Data Shuffling for Distributed Learning
Data shuffling between distributed cluster of nodes is one of the critical steps in implementing large-scale learning algorithms. Randomly shuffling the data-set among a cluster of workers allows different nodes to obtain fresh data assignments at each learning epoch. This process has been shown to provide improvements in the learning process. However, the statistical benefits of distributed data shuffling come at the cost of extra communication overhead from the master node to worker nodes, and can act as one of the major bottlenecks in the overall time for computation. There has been significant recent interest in devising approaches to minimize this communication overhead. One approach is to provision for extra storage at the computing nodes. The other emerging approach is to leverage coded communication to minimize the overall communication overhead. The focus of this work is to understand the fundamental trade-off between the amount of storage and the communication overhead for distributed data shuffling. In this work, we first present an information theoretic formulation for the data shuffling problem, accounting for the underlying problem parameters (number of workers, $K$, number of data points, $N$, and the available storage, $S$ per node). We then present an information theoretic lower bound on the communication overhead for data shuffling as a function of these parameters. We next present a novel coded communication scheme and show that the resulting communication overhead of the proposed scheme is within a multiplicative factor of at most $\frac{K}{K-1}$ from the information-theoretic lower bound. Furthermore, we present the aligned coded shuffling scheme for some storage values, which achieves the optimal storage vs communication trade-off for $K<5$, and further reduces the maximum multiplicative gap down to $\frac{K-\frac{1}{3}}{K-1}$, for $K\geq 5$.
💡 Research Summary
The paper addresses the communication bottleneck caused by data shuffling in large‑scale distributed learning systems that employ a master‑worker architecture. In each learning epoch the master randomly permutes the entire dataset and assigns disjoint batches to K workers. Because each worker can store only S·d bits (where d is the dimensionality of a data point), communication is required whenever the storage per worker is less than the full dataset size N·d. The authors formulate the problem information‑theoretically, deriving a lower bound on the worst‑case communication load as a function of the number of workers K, the dataset size N, and the per‑worker storage S.
To obtain a tight bound they consider a special family of “cyclic shuffles” in which no worker receives any data that it stored in the previous two shuffles. This choice maximizes the amount of new information each worker must acquire, allowing the authors to express the lower bound as a linear program (LP) over the sizes of data sub‑chunks. Solving the LP yields a piecewise‑linear function R_lower(S) that captures the optimal trade‑off: when S = N/K (the minimum storage needed to hold a single batch) the bound is (K‑1)/K·N·d, and when S = N (full replication) the bound is zero.
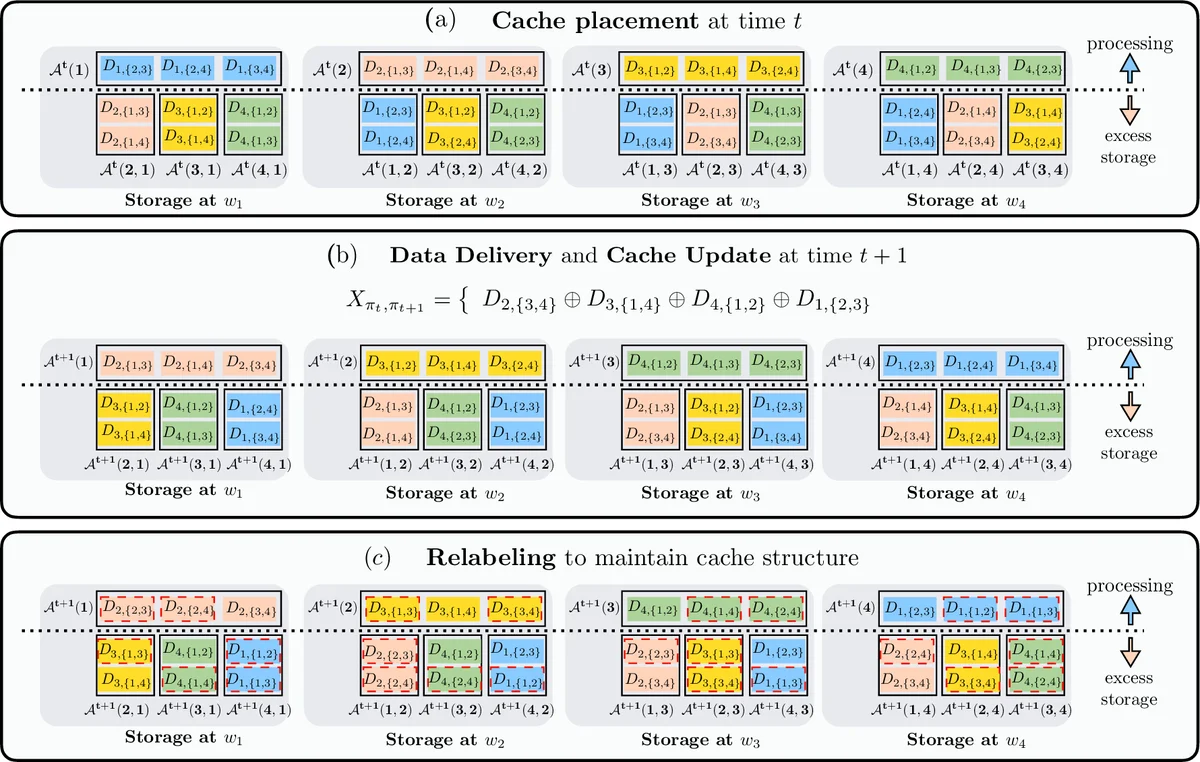
Based on this analysis the authors propose a structural invariant placement scheme. The dataset is partitioned into 2^{K‑1} sub‑files indexed by subsets of workers. Each worker stores its current batch uncoded and, in its excess storage (S – N/K)·d bits, stores sub‑files that correspond to subsets containing that worker. This placement is invariant under shuffles: after each epoch the same pattern of sub‑files is retained, merely relabeled.
During the data delivery phase the master broadcasts a single linear combination of all sub‑files (a coded message X). Because each worker already knows many of the sub‑files from its cache, it can subtract them from X and recover the missing pieces needed for the next batch. The authors prove that this coded transmission achieves a communication rate R = (K/(K‑1))·R_lower(S), i.e., at most a factor K/(K‑1) above the information‑theoretic optimum. As K grows, this factor approaches 1, meaning the scheme is asymptotically optimal.
To further close the gap, the paper introduces an Aligned Coded Shuffling technique. Here the authors deliberately align the interference seen by different workers so that each worker’s undesired components occupy the smallest possible subspace. This is accomplished by carefully designing the sub‑file partitioning and the coding matrix so that multiple workers can simultaneously decode their required pieces from the same broadcast. With this alignment, the scheme attains the exact lower bound for K < 5 (thus optimal) and reduces the worst‑case multiplicative gap to (K‑1/3K‑1) for K ≥ 5, a significant improvement over the basic scheme.
The contributions can be summarized as follows:
- Information‑theoretic lower bound on worst‑case shuffling communication for arbitrary K, N, and storage S, derived via a novel LP based on cyclic shuffles.
- Structural invariant placement and coded delivery that achieves within a factor K/(K‑1) of the lower bound for any K, with simple broadcast and linear decoding operations.
- Aligned coded shuffling that eliminates the gap for small K and reduces it dramatically for larger K, effectively achieving optimality in many practical regimes.
The paper situates its work among prior studies on coded shuffling, coded computation, and index coding, highlighting that earlier works either considered only specific K values, assumed full replication, or did not provide tight converse bounds. By jointly addressing storage design, coding, and interference alignment, this work provides a near‑optimal solution to the fundamental storage‑communication trade‑off in distributed learning.
Future directions suggested include extending the analysis to average‑case (random) shuffles, incorporating straggler mitigation, and adapting the schemes to wireless or noisy channels where broadcast reliability and channel coding must be jointly considered.
Comments & Academic Discussion
Loading comments...
Leave a Comment