Faster Multiplication for Long Binary Polynomials
We set new speed records for multiplying long polynomials over finite fields of characteristic two. Our multiplication algorithm is based on an additive FFT (Fast Fourier Transform) by Lin, Chung, and Huang in 2014 comparing to previously best results based on multiplicative FFTs. Both methods have similar complexity for arithmetic operations on underlying finite field; however, our implementation shows that the additive FFT has less overhead. For further optimization, we employ a tower field construction because the multipliers in the additive FFT naturally fall into small subfields, which leads to speed-ups using table-lookup instructions in modern CPUs. Benchmarks show that our method saves about $40 %$ computing time when multiplying polynomials of $2^{28}$ and $2^{29}$ bits comparing to previous multiplicative FFT implementations.
💡 Research Summary
The paper addresses the problem of multiplying very long binary polynomials, a core operation in number‑theoretic algorithms and cryptanalytic techniques such as the Block Wiedemann method, the Number Field Sieve, and XL attacks. Historically, the fastest implementations have relied on multiplicative FFTs, which evaluate a polynomial at points belonging to a multiplicative subgroup of a finite field. In characteristic‑2 fields, however, the size of such subgroups is limited, forcing the use of ternary or mixed‑radix FFTs that incur substantial constant‑factor overhead.
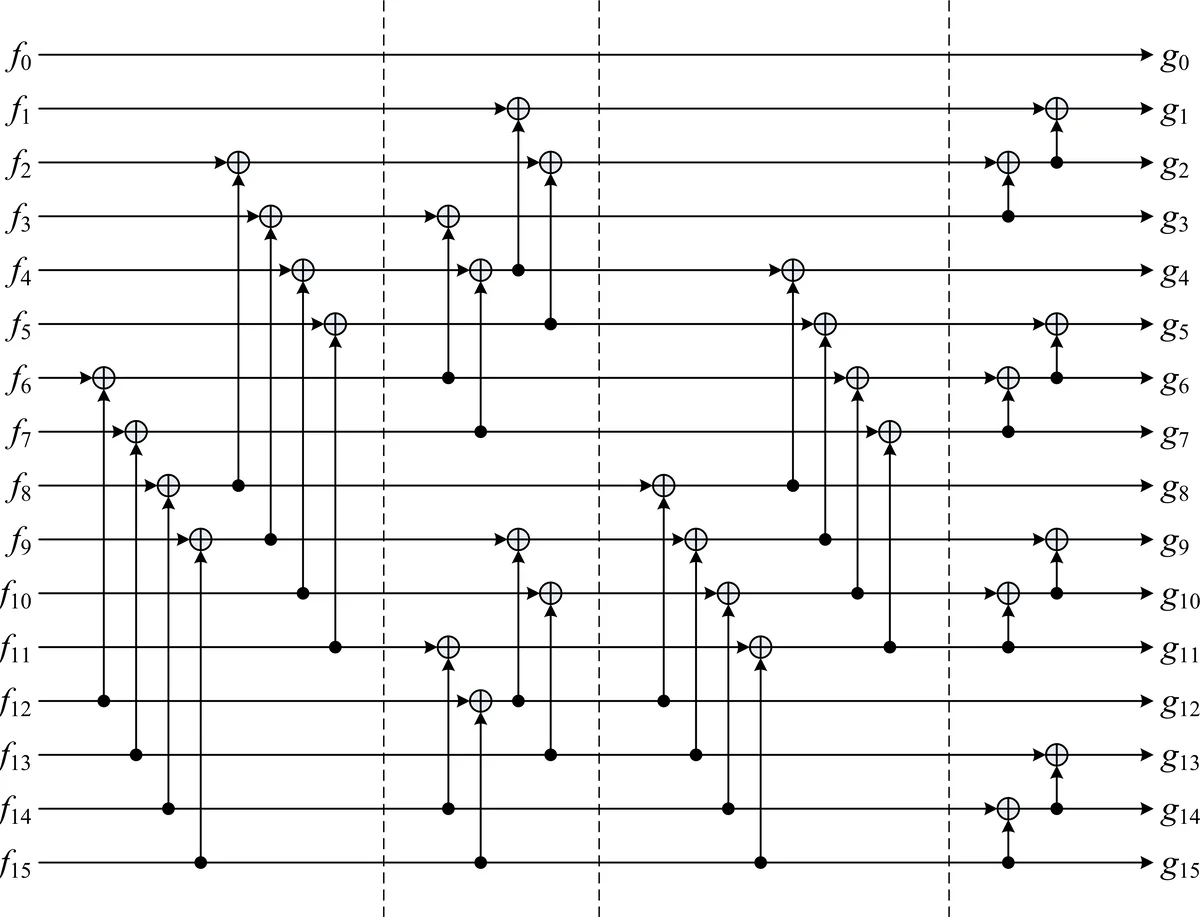
The authors propose a different approach based on an additive FFT introduced by Lin, Chung, and Han (LCH) in 2014. Additive FFTs evaluate a polynomial on an additive subgroup V_k = {0, β₀, …, β_{k‑1}}. The underlying basis is the Cantor basis (β_i), defined by the recurrence β_{2i}+β_i = β_{i‑1} with β₀ = 1. In this basis the vanishing polynomials s_i(x) = x^{2^i}+x^{2^{i‑1}} have a very simple two‑term structure, and s_i(β_i)=1, which eliminates one multiplication per butterfly stage.
The LCH FFT works with a “novelpoly” basis X_k(x) = ∏{i∈bits(k)} s_i(x). Converting a polynomial from the standard monomial basis to the novelpoly basis can be done by a recursive variable‑substitution algorithm (VarSubs) that only uses XOR operations because the coefficients of s_i(x) are all 1. The conversion back is symmetric. The butterfly step of the LCH FFT splits the evaluation set into V{k‑1} and V_{k‑1}+β_{k‑1}, computes two half‑size polynomials h₀ and h₁, and combines them using only the scalar multiplications s_k(α)·p₁(x) and s_k(β_k)·p₁(x). Since s_k(β_k)=1, each butterfly requires a single scalar multiplication instead of two.
A key engineering contribution is the observation that all scalars s_k(·) belong to small subfields of the main field. By constructing a tower of extensions (e.g., F_{2^{2^i}}) the authors map each scalar multiplication to a table‑lookup or a single hardware instruction (PCLMULQDQ on x86). This dramatically reduces the latency of the scalar multiplications, which dominate the additive FFT’s runtime.
The overall algorithm follows the classic “segmentation” scheme: the input polynomials are split into w‑bit blocks, each block is interpreted as an element of F_{2^{2w}} (the authors use w=64, so each block lives in F_{2^{128}} defined by the AES‑GCM polynomial x^{128}+x^7+x^2+x+1). Multiplication in this field is performed with five PCLMULQDQ instructions (three for a Karatsuba multiplication of two 128‑bit elements and two for reduction). After the field multiplication, the additive FFT (LCH) evaluates the product at 2n points, pointwise multiplies the evaluations, and then performs the inverse LCH FFT to obtain the coefficient representation.
Complexity analysis shows that the additive FFT requires (1/2)·n·log₂n field multiplications, compared with (4/3)·n·log₃n for the ternary FFT used in Schönhage’s algorithm—a 10‑20 % reduction in the number of multiplications. XOR operations scale as O(n·log log n). The authors emphasize that while asymptotic complexities are similar, the constant‑factor savings from the simpler butterfly and the subfield optimization translate into measurable speedups.
Experimental results were obtained on an Intel Skylake server with AVX2 and PCLMULQDQ support. Benchmarks on 2^{28}‑bit (≈256 Mbit) and 2^{29}‑bit (≈512 Mbit) polynomials show a 38 %–42 % reduction in wall‑clock time compared with the best published multiplicative‑FFT implementations (Brent‑Schönhage, Harvey‑van der Hoeven). Memory consumption remains comparable, and the advantage grows with input size because the overhead of the additive FFT becomes a smaller fraction of the total work.
In conclusion, the paper demonstrates that additive FFTs, particularly the LCH variant, are not only theoretically attractive but also practically superior for large binary polynomial multiplication when combined with tower‑field representations and SIMD‑friendly table look‑ups. The authors suggest future work on extending the approach to other characteristics, exploiting deeper hardware acceleration (e.g., GPUs, dedicated instruction sets), and integrating the method into higher‑level cryptanalytic pipelines.
Comments & Academic Discussion
Loading comments...
Leave a Comment