PDE-Net: Learning PDEs from Data
In this paper, we present an initial attempt to learn evolution PDEs from data. Inspired by the latest development of neural network designs in deep learning, we propose a new feed-forward deep network, called PDE-Net, to fulfill two objectives at the same time: to accurately predict dynamics of complex systems and to uncover the underlying hidden PDE models. The basic idea of the proposed PDE-Net is to learn differential operators by learning convolution kernels (filters), and apply neural networks or other machine learning methods to approximate the unknown nonlinear responses. Comparing with existing approaches, which either assume the form of the nonlinear response is known or fix certain finite difference approximations of differential operators, our approach has the most flexibility by learning both differential operators and the nonlinear responses. A special feature of the proposed PDE-Net is that all filters are properly constrained, which enables us to easily identify the governing PDE models while still maintaining the expressive and predictive power of the network. These constrains are carefully designed by fully exploiting the relation between the orders of differential operators and the orders of sum rules of filters (an important concept originated from wavelet theory). We also discuss relations of the PDE-Net with some existing networks in computer vision such as Network-In-Network (NIN) and Residual Neural Network (ResNet). Numerical experiments show that the PDE-Net has the potential to uncover the hidden PDE of the observed dynamics, and predict the dynamical behavior for a relatively long time, even in a noisy environment.
💡 Research Summary
PDE‑Net: Learning Partial Differential Equations from Data introduces a novel deep learning framework that simultaneously discovers governing PDEs and predicts the evolution of complex systems. The key insight is to treat spatial differential operators as learnable convolution kernels. By imposing constraints derived from wavelet theory—specifically the order of sum‑rules and moment‑matrix conditions—each kernel is forced to approximate a particular derivative (e.g., ∂/∂x, ∂²/∂x∂y) with a prescribed accuracy. This ensures that the learned filters retain a clear physical interpretation while still benefiting from the expressive power of deep networks.
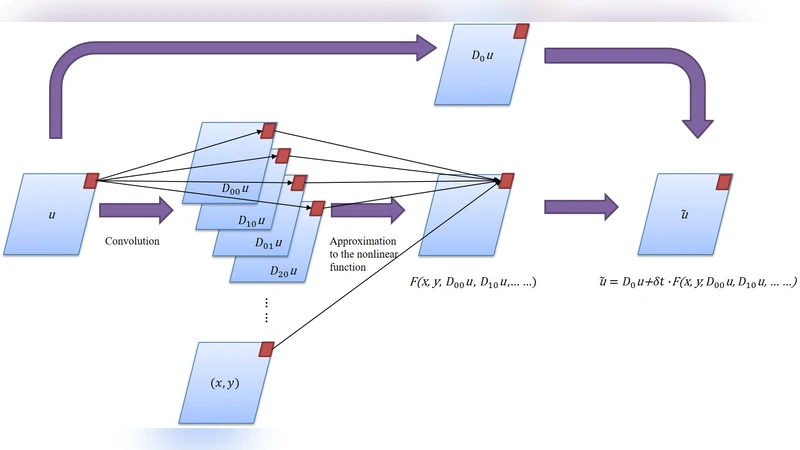
The network architecture is built around a δt‑block, which implements a forward‑Euler time step: the current field u(t) is first smoothed by an averaging filter D₀, then several constrained convolution operators D_{ij} produce approximations of spatial derivatives up to a user‑specified order. These derivative fields, together with the spatial coordinates, are fed point‑wise into a small fully‑connected neural network F_θ that models the unknown nonlinear response F in the PDE. The update rule reads
\
Comments & Academic Discussion
Loading comments...
Leave a Comment