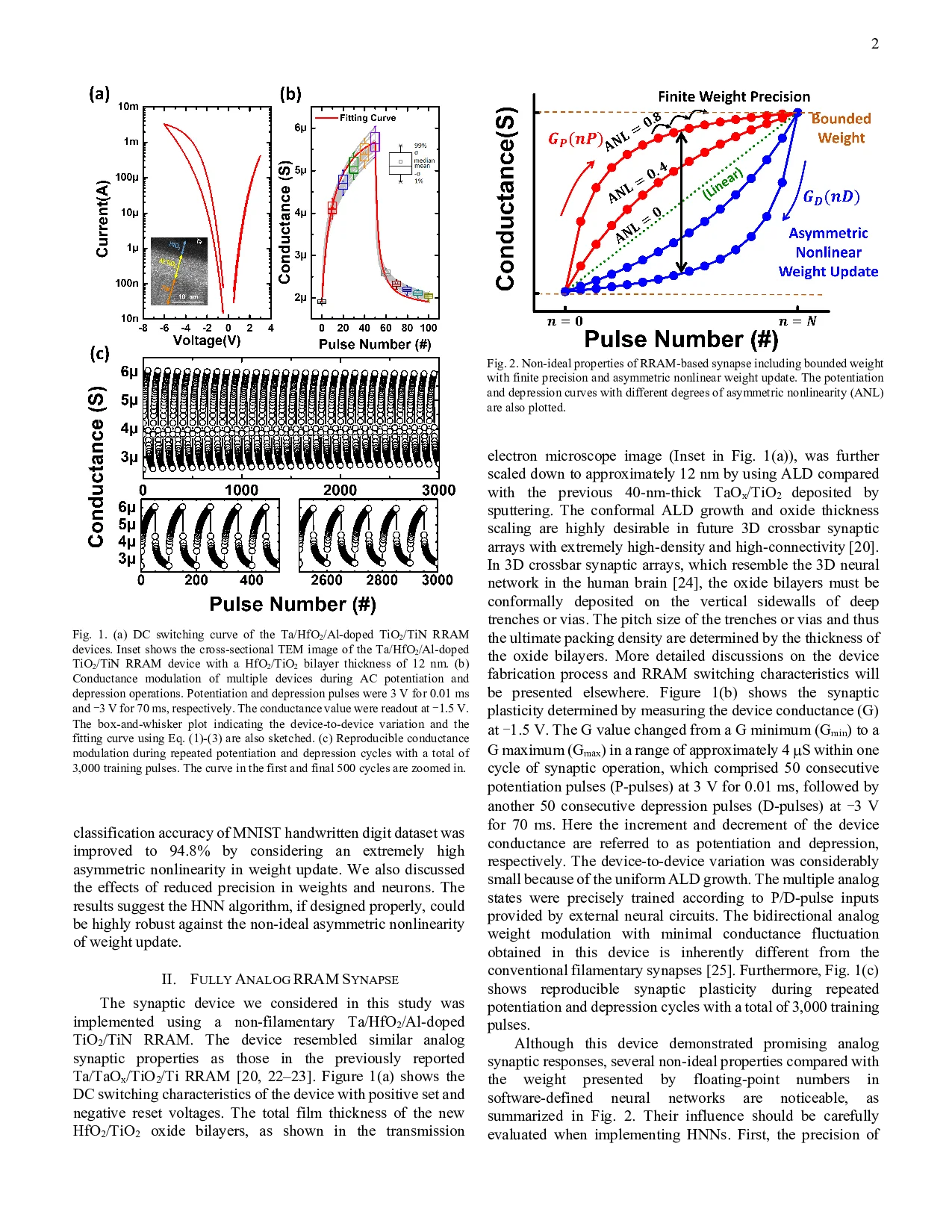
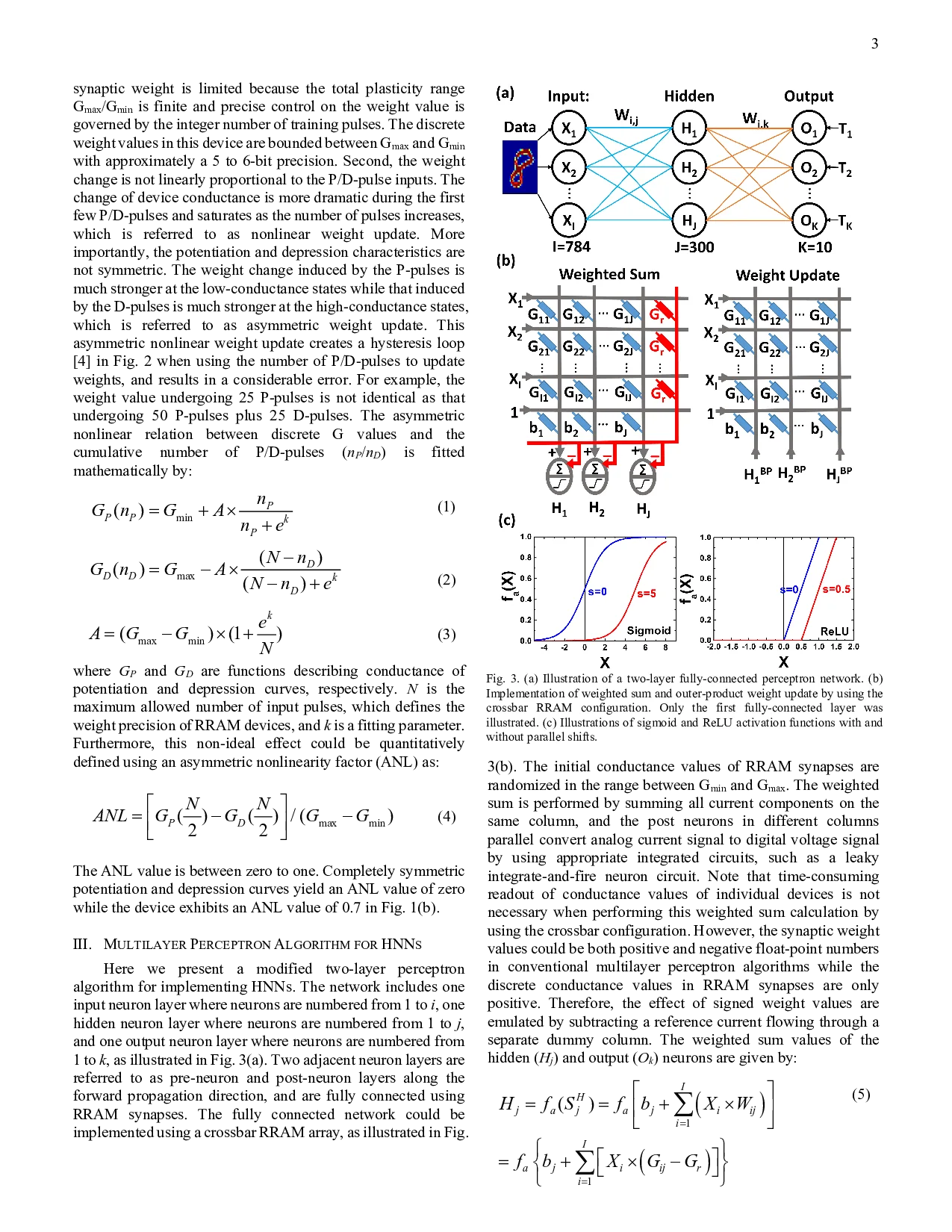
Asymmetric nonlinear weight update is considered as one of the major obstacles for realizing hardware neural networks based on analog resistive synapses because it significantly compromises the online training capability. This paper provides new solutions to this critical issue through co-optimization with the hardware-applicable deep-learning algorithms. New insights on engineering activation functions and a threshold weight update scheme effectively suppress the undesirable training noise induced by inaccurate weight update. We successfully trained a two-layer perceptron network online and improved the classification accuracy of MNIST handwritten digit dataset to 87.8/94.8% by using 6-bit/8-bit analog synapses, respectively, with extremely high asymmetric nonlinearity.
Deep Dive into Mitigating Asymmetric Nonlinear Weight Update Effects in Hardware Neural Network based on Analog Resistive Synapse.
Asymmetric nonlinear weight update is considered as one of the major obstacles for realizing hardware neural networks based on analog resistive synapses because it significantly compromises the online training capability. This paper provides new solutions to this critical issue through co-optimization with the hardware-applicable deep-learning algorithms. New insights on engineering activation functions and a threshold weight update scheme effectively suppress the undesirable training noise induced by inaccurate weight update. We successfully trained a two-layer perceptron network online and improved the classification accuracy of MNIST handwritten digit dataset to 87.8/94.8% by using 6-bit/8-bit analog synapses, respectively, with extremely high asymmetric nonlinearity.
1
Abstract—Asymmetric nonlinear weight update is considered
as one of the major obstacles for realizing hardware neural
networks based on analog resistive synapses because it
significantly compromises the online training capability. This
paper provides new solutions to this critical issue through
co-optimization with the hardware-applicable deep-learning
algorithms. New insights on engineering activation functions and
a threshold weight update scheme effectively suppress the
undesirable training noise induced by inaccurate weight update.
We successfully trained a two-layer perceptron network online
and improved the classification accuracy of MNIST handwritten
digit dataset to 87.8/94.8% by using 6-bit/8-bit analog synapses,
respectively, with extremely high asymmetric nonlinearity.
Index Terms—Neuromorphic computing, RRAM, synapse,
multilayer perceptron
I. INTRODUCTION
EEP learning on software-defined neural networks has
greatly advanced many aspects of artificial intelligence,
such as image recognition, speech recognition, natural
language understanding, and decision making, by using a
general-purpose
learning
procedure
on
conventional
computing hardware, such as central processing units or
graphic processing units [1]. Recently, the limitations of the
conventional computing hardware on the form factor, cost, and
power consumption of deep learning systems have promoted
active research on hardware neural networks (HNNs) that are
inspired by the physical structure of high-density, low-power,
and distributed biological neural networks [2-3]. The HNNs
employing
crossbar
resistive
random
access
memory
(RRAM)-based synaptic arrays are particularly interesting
because they may significantly improve the learning efficiency
by fully parallelizing the vector-matrix multiplication
(weighted sum) and outer-product weight update through the
This work was supported by the Ministry of Science and Technology of
Taiwan under grant: MOST 105-2119-M-009-009 and Research of Excellence
program
MOST
106-2633-E-009-001,
and
Taiwan
Semiconductor
Manufacturing Company. T.-H. Hou acknowledges support by NCTU-UCB
I-RiCE program, under grant MOST 106-2911-I-009-301.
The authors are with Department of Electronics Engineering and Institute of
Electronics,
National
Chiao
Tung
University,
Hsinchu,
Taiwan
(email:thhou@mail.nctu.edu.tw)
distributed weight storage [4]. Impressive RRAM-based HNN
prototypes have been demonstrated including speech and
electroencephalography
signal
recognition
[5],
pattern
recognition [6], dot product engine [7], nature image
processing [8], and face classification [9]. However, most
implementations were limited to primitive algorithms such as
single-layer perceptron or sparse coding, and many of them
relied on offline training. By contrast, our brain processes
information intelligently and in real time through a
considerably more complicated deep neural networks with a
layered structure [10]. The software approach also resorts to
extremely deep neural networks to improve recognition
accuracy that surpasses humans [11]. Designing a deep HNN
with online training capability is a nontrivial task because of the
challenges of non-ideal properties of RRAM synapses [4,
12–16]. In particular, the asymmetric nonlinear weight update
of RRAM synapses had been identified as an outstanding issue
that significantly degraded the learning accuracy [15–17].
Several approaches have been proposed aiming at improving
the asymmetric nonlinear weight update of RRAM synapses,
for example by careful material/device engineering [18], by
implementing an additional compensational circuit [19], or by
optimizing the operating pulse waveform [20]. However, to
further increase the immunity against this undesirable nonlinear
effect,
co-optimization
considering
both
the
device
characteristics and the HNN algorithms suitable for future deep
learning would be essential.
This paper focused on the HNN design employing a
Ta/HfO2/Al-doped TiO2/TiN synaptic device deposited by
atomic layer deposition (ALD). The device exhibited
bidirectional analog weight change that is suitable for the
ultimate
high-density
neural
network
by
using
one
two-terminal RRAM cell per synapse [4]. By contrast, more
than one RRAM cell per synapse would be required by using
binary RRAM [21] or unidirectional analog RRAM [15].
Furthermore, we presented a hardware-applicable multilayer
perceptron (MLP) algorithm that accelerated supervised online
training through massive parallelism. The MLP algorithm is the
foundation of numerous deep-learning neural networks such as
convolutional neural network (CNN). We reported that
engineering the nonlinear activation function and employing a
cutoff threshold on weight update were effective for mitigating
the effects of asymmetric nonlinear weight update. The
Chih-Cheng Chang, Pin-Chun Chen, Teyuh Chou, I-Ting
…(Full text truncated)…
This content is AI-processed based on ArXiv data.