Automated flow for compressing convolution neural networks for efficient edge-computation with FPGA
Deep convolutional neural networks (CNN) based solutions are the current state- of-the-art for computer vision tasks. Due to the large size of these models, they are typically run on clusters of CPUs or GPUs. However, power requirements and cost budgets can be a major hindrance in adoption of CNN for IoT applications. Recent research highlights that CNN contain significant redundancy in their structure and can be quantized to lower bit-width parameters and activations, while maintaining acceptable accuracy. Low bit-width and especially single bit-width (binary) CNN are particularly suitable for mobile applications based on FPGA implementation, due to the bitwise logic operations involved in binarized CNN. Moreover, the transition to lower bit-widths opens new avenues for performance optimizations and model improvement. In this paper, we present an automatic flow from trained TensorFlow models to FPGA system on chip implementation of binarized CNN. This flow involves quantization of model parameters and activations, generation of network and model in embedded-C, followed by automatic generation of the FPGA accelerator for binary convolutions. The automated flow is demonstrated through implementation of binarized “YOLOV2” on the low cost, low power Cyclone- V FPGA device. Experiments on object detection using binarized YOLOV2 demonstrate significant performance benefit in terms of model size and inference speed on FPGA as compared to CPU and mobile CPU platforms. Furthermore, the entire automated flow from trained models to FPGA synthesis can be completed within one hour.
💡 Research Summary
The paper presents a fully automated design flow that transforms a trained TensorFlow convolutional neural network (CNN) into a binarized implementation on a low‑cost FPGA system‑on‑chip (SoC), targeting edge‑computing scenarios where power, cost, and memory are tightly constrained. The authors first quantize the full‑precision model to 1‑bit weights and 2‑bit activations (except for the first and last layers), then retrain to recover accuracy. The quantized model is exported as a TensorFlow protocol‑buffer file, parsed, and unnecessary sub‑graphs (e.g., linear operations that become trivial after quantization) are removed. By packing 32 binary weight values into a single 32‑bit word, the model size shrinks dramatically—from 255 MB for the original YOLO‑v2 to 8.26 MB (a 32× reduction).
Next, an embedded‑C representation of the network is automatically generated. The flow identifies convolution layers that are suitable for hardware acceleration and maps them to a high‑level synthesis (HLS) template. The FPGA accelerator is built from two hierarchical building blocks: a Processing Element (PE) that processes 32 binary kernel elements in parallel with a 32‑bit accumulator, and a Processing Engine (PEN) that arranges multiple PEs in a matrix to exploit inter‑kernel parallelism and input reuse. Design assumptions (output feature maps multiple of 8, input feature maps multiple of 16, limited on‑chip memory) match the characteristics of popular CNN architectures and low‑cost edge devices.
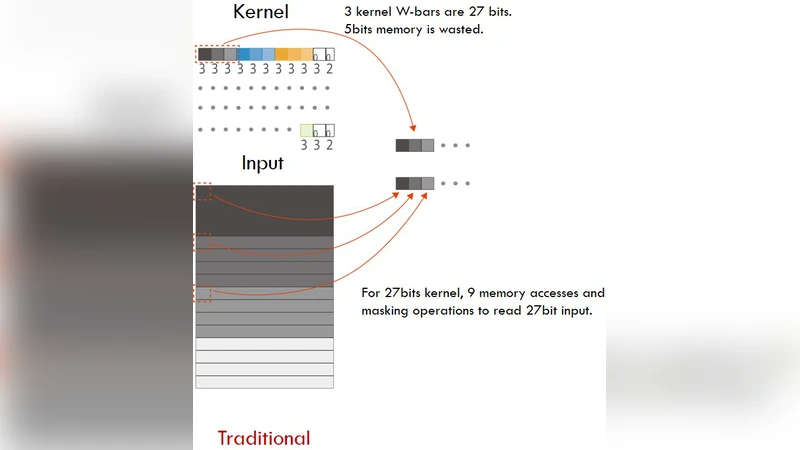
A novel data‑ordering strategy is introduced to improve memory bandwidth. Instead of the conventional depth‑first layout (Depth×Width×Height), the authors store tensors in Height×Width×Depth (or Width×Height×Depth) order. This depth‑first ordering maximizes the continuity of memory addresses during DRAM burst accesses, reduces the number of address jumps, and simplifies bit‑packing logic in on‑chip RAM. Consequently, both external DRAM bandwidth and internal RAM access become more efficient, which is especially beneficial for binary convolutions that are heavily memory‑bound.
The flow is evaluated by implementing a binarized version of YOLO‑v2 on an Intel Cyclone‑V 5CSEA6 SoC (ARM Cortex‑A9 + FPGA). Three platforms are compared: a desktop Intel Core i7‑6800K, a mobile ARM Cortex‑A9, and the Cortex‑A9 + FPGA SoC. All binaries are compiled with -O3. The FPGA‑accelerated binary convolution core (BinCon‑v‑Core) yields up to 11.5× speed‑up over the mobile CPU alone and 1.21× over the desktop CPU for that specific operation. Overall inference on the SoC is 5.34× faster than the mobile CPU alone, though it remains 1.78× slower than the high‑end desktop CPU. The entire pipeline—from a trained TensorFlow model to a synthesized FPGA bitstream—takes roughly one hour, demonstrating practical usability.
In conclusion, the authors deliver an end‑to‑end, largely hands‑free methodology for deploying binarized CNNs on resource‑constrained FPGA SoCs. The approach achieves substantial model size reduction, competitive inference speed, and a rapid development cycle. However, the current implementation does not yet meet real‑time performance requirements for demanding applications, and the authors acknowledge the need for deeper design‑space exploration, higher parallelism, and more sophisticated memory‑hierarchy management in future work.
Comments & Academic Discussion
Loading comments...
Leave a Comment