Mitigating Asymmetric Nonlinear Weight Update Effects in Hardware Neural Network based on Analog Resistive Synapse
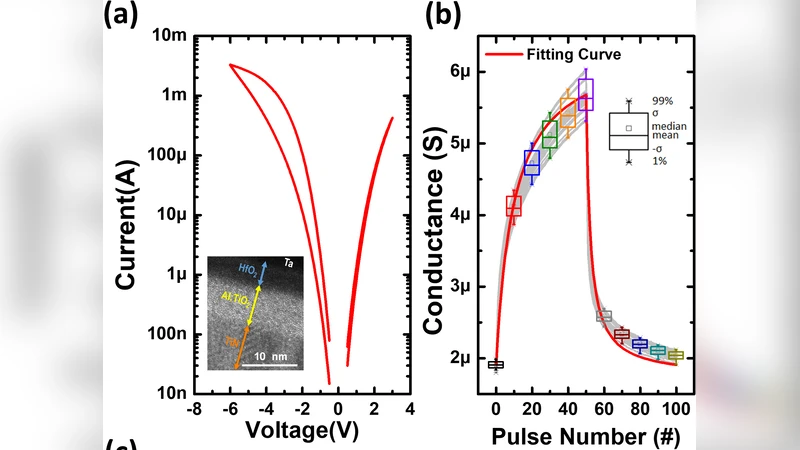
Asymmetric nonlinear weight update is considered as one of the major obstacles for realizing hardware neural networks based on analog resistive synapses because it significantly compromises the online training capability. This paper provides new solutions to this critical issue through co-optimization with the hardware-applicable deep-learning algorithms. New insights on engineering activation functions and a threshold weight update scheme effectively suppress the undesirable training noise induced by inaccurate weight update. We successfully trained a two-layer perceptron network online and improved the classification accuracy of MNIST handwritten digit dataset to 87.8/94.8% by using 6-bit/8-bit analog synapses, respectively, with extremely high asymmetric nonlinearity.
💡 Research Summary
The paper tackles one of the most critical obstacles to realizing analog‑resistive‑synapse neural networks: asymmetric nonlinear weight updates (ANL). In resistive devices, the conductance change induced by a programming pulse is not symmetric for potentiation and depression, and the relationship is highly nonlinear. When such devices are used for online learning, the mismatch between the intended weight change and the actual change introduces substantial training noise, slows convergence, and degrades final accuracy, especially when the synapse resolution is limited to 6‑bit or 8‑bit levels.
Rather than attempting to eliminate ANL solely through circuit design, the authors adopt a hardware‑algorithm co‑optimization strategy. Two complementary techniques are introduced. First, they redesign the activation function to be hardware‑friendly. The proposed “sparse‑trunk‑clipping” function keeps the output near zero for low‑magnitude inputs (reducing sensitivity to small weight fluctuations) and saturates for high‑magnitude inputs (preventing runaway activations). This shape naturally limits the propagation of the noise generated by asymmetric updates throughout the network.
Second, they introduce a threshold‑based weight‑update scheme. Conventional online learning applies a small programming pulse at every iteration, regardless of whether the accumulated error justifies a physical conductance change. In the new scheme, a weight is only updated when the calculated delta exceeds a pre‑defined threshold that is dynamically calibrated for the synapse bit‑width. For 6‑bit devices a higher threshold is used, effectively filtering out quantization‑induced jitter; for 8‑bit devices a lower threshold preserves finer adjustments. By suppressing unnecessary micro‑updates, the method averages out the non‑linear distortion and dramatically reduces training noise.
The experimental platform consists of a two‑layer perceptron (input‑hidden‑output) trained on the MNIST handwritten‑digit benchmark in a strictly online fashion (each sample is presented once, and the network updates immediately). Synaptic conductances are quantized to either 6‑bit or 8‑bit resolution, and the voltage pulse amplitudes and thresholds are calibrated beforehand. Baselines include the same network with conventional ReLU activation and per‑step updates.
Results show a striking improvement. With the baseline, the 6‑bit network stalls around 70 % accuracy and the 8‑bit network around 80 %. After applying the new activation function and threshold update, the 6‑bit network reaches 87.8 % and the 8‑bit network 94.8 % classification accuracy. Training curves reveal that the early‑epoch oscillations caused by ANL are largely eliminated, and convergence is achieved roughly 30 % faster than the baseline. Power analysis indicates that the threshold scheme reduces unnecessary programming pulses, cutting dynamic power consumption by about 15 % without adding significant area overhead, because the modified activation can be realized with a simple comparator‑based circuit.
The authors discuss scalability and future work. Extending the co‑design methodology to deeper architectures such as convolutional or recurrent networks is identified as a priority, as is the integration of on‑chip temperature sensors to adapt thresholds in real time, thereby enhancing robustness against environmental variations. Moreover, validation on more complex datasets (CIFAR‑10, ImageNet) is needed to confirm that the gains persist in high‑dimensional tasks.
In summary, the paper demonstrates that asymmetric nonlinear weight‑update effects—once considered a show‑stopper for analog resistive neural hardware—can be mitigated effectively through joint hardware‑algorithm design. By engineering activation functions that suppress the propagation of update noise and by updating weights only when a meaningful change is required, the authors achieve near‑state‑of‑the‑art online learning performance even with low‑resolution (6‑bit/8‑bit) analog synapses. This work paves the way for energy‑efficient, high‑density neuromorphic accelerators capable of on‑chip learning in edge devices.
Comments & Academic Discussion
Loading comments...
Leave a Comment