On the Efficacy of Live DDoS Detection with Hadoop
Distributed Denial of Service flooding attacks are one of the biggest challenges to the availability of online services today. These DDoS attacks overwhelm the victim with huge volume of traffic and render it incapable of performing normal communication or crashes it completely. If there are delays in detecting the flooding attacks, nothing much can be done except to manually disconnect the victim and fix the problem. With the rapid increase of DDoS volume and frequency, the current DDoS detection technologies are challenged to deal with huge attack volume in reasonable and affordable response time. In this paper, we propose HADEC, a Hadoop based Live DDoS Detection framework to tackle efficient analysis of flooding attacks by harnessing MapReduce and HDFS. We implemented a counter-based DDoS detection algorithm for four major flooding attacks (TCP-SYN, HTTP GET, UDP and ICMP) in MapReduce, consisting of map and reduce functions. We deployed a testbed to evaluate the performance of HADEC framework for live DDoS detection. Based on the experiments we showed that HADEC is capable of processing and detecting DDoS attacks in affordable time.
💡 Research Summary
The paper presents HADEC, a Hadoop‑based framework designed to detect large‑scale Distributed Denial‑of‑Service (DDoS) flooding attacks with near‑real‑time responsiveness. HADEC is built around three logical components: a traffic‑capturing server, a detection server, and a Hadoop cluster that provides HDFS storage and MapReduce processing. The capturing server uses the open‑source packet capture library tshark to sniff live traffic, extracts only essential header fields (timestamp, source IP, destination IP, protocol, and a brief header summary), and writes them into log files whose size and count are configurable by the administrator. Once a log file reaches the configured size, the capturing server pauses capture, notifies the detection server via a web service, and transfers the file to the detection server using SCP. The detection server, acting as the Hadoop NameNode, uploads the log into HDFS, where it is automatically split into equal‑size blocks and distributed across the data nodes.
A MapReduce job then processes the logs. The mapper reads each line (representing a single packet) and emits a (key, value) pair where the key is the source IP address and the value is the packet record. Protocol‑specific filtering is performed in the mapper: UDP/QUIC packets are selected for UDP flood detection, ICMP packets for ICMP flood detection, TCP packets with the SYN flag for SYN flood detection, and HTTP GET requests for HTTP‑GET flood detection. During the shuffle phase, all records sharing the same source IP are routed to the same reducer. Each reducer maintains a simple counter for its assigned IP and, after processing all its records, compares the count against a pre‑defined threshold. If the threshold is exceeded, the IP is flagged as an attacker and written to an output file in HDFS. After the job completes, the detection server reads the result file, notifies the administrator through the capturing server, and cleans up the input and output directories in HDFS.
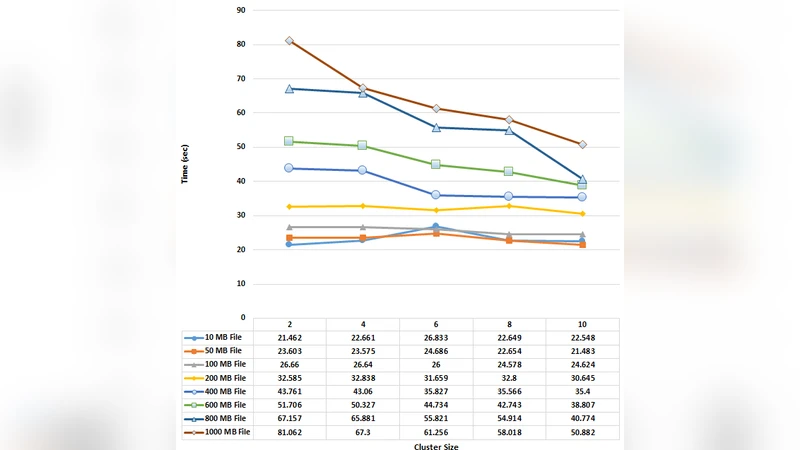
The authors evaluated HADEC on a testbed consisting of ten physical machines connected via a gigabit LAN, with one machine acting as the capturing server and the remaining nine forming the Hadoop cluster. They generated 300 GB of synthetic attack traffic covering TCP‑SYN, UDP, ICMP, and HTTP‑GET floods, which the capturing server reduced to a 20 GB log file. HADEC processed this log in approximately 8.35 minutes on the ten‑node cluster, demonstrating that the framework can handle massive volumes of data within a practical time window. For a smaller scenario representing 1.8 Gbps of live traffic, the entire detection pipeline (capture, transfer, MapReduce processing, and result notification) completed in about 21 seconds, indicating that HADEC can approach real‑time detection for moderate traffic loads.
The paper highlights several strengths of the approach. By leveraging Hadoop’s inherent scalability, HADEC can increase processing capacity simply by adding more nodes, which addresses the throughput bottleneck faced by traditional intrusion detection systems when monitoring high‑speed links. The use of a counter‑based detection algorithm keeps the implementation straightforward and computationally cheap, allowing the framework to scale linearly with the number of nodes. Moreover, the separation of capture and detection responsibilities enables the system to be deployed in environments where the victim’s network is isolated from the analysis cluster, preserving operational stability.
However, the authors also acknowledge notable limitations. The MapReduce paradigm introduces a non‑trivial job‑initialization overhead, which limits the minimum achievable detection latency; true sub‑second detection for high‑frequency attacks is not feasible with the current batch‑oriented design. The detection logic relies solely on source‑IP packet counts, making it vulnerable to low‑rate “stealth” attacks and to IP‑spoofing, which can cause false positives or allow attackers to evade detection. The paper does not provide quantitative metrics on detection accuracy (precision, recall, false‑positive/false‑negative rates), nor does it discuss how the chosen thresholds were derived, leaving the practical effectiveness of the algorithm uncertain. Additionally, only four attack vectors are covered, and the framework does not address encrypted traffic or application‑layer attacks that do not manifest as simple request floods.
In terms of future work, the authors suggest moving from batch‑oriented MapReduce to streaming processing frameworks such as Apache Spark Streaming or Apache Flink, which would reduce latency by processing packets as they arrive. Incorporating richer feature sets—such as five‑tuple flow statistics, packet‑size distributions, TTL variance, and temporal patterns—could enable more sophisticated, machine‑learning‑based classifiers capable of detecting low‑volume or multi‑vector attacks. Addressing IP‑spoofing could involve correlating inbound and outbound flow records or employing source‑validation techniques at upstream routers. Finally, integrating the detection output with Software‑Defined Networking (SDN) controllers or automated mitigation appliances would close the loop, allowing HADEC not only to detect but also to actively block malicious traffic in near real‑time.
Overall, HADEC demonstrates that big‑data platforms like Hadoop can be repurposed for large‑scale DDoS analysis, offering a scalable foundation for handling massive traffic logs. To evolve into a fully operational real‑time defense system, the framework will need to adopt streaming analytics, enhance detection sophistication, and provide tighter integration with mitigation mechanisms.
Comments & Academic Discussion
Loading comments...
Leave a Comment