From virtual demonstration to real-world manipulation using LSTM and MDN
Robots assisting the disabled or elderly must perform complex manipulation tasks and must adapt to the home environment and preferences of their user. Learning from demonstration is a promising choice, that would allow the non-technical user to teach the robot different tasks. However, collecting demonstrations in the home environment of a disabled user is time consuming, disruptive to the comfort of the user, and presents safety challenges. It would be desirable to perform the demonstrations in a virtual environment. In this paper we describe a solution to the challenging problem of behavior transfer from virtual demonstration to a physical robot. The virtual demonstrations are used to train a deep neural network based controller, which is using a Long Short Term Memory (LSTM) recurrent neural network to generate trajectories. The training process uses a Mixture Density Network (MDN) to calculate an error signal suitable for the multimodal nature of demonstrations. The controller learned in the virtual environment is transferred to a physical robot (a Rethink Robotics Baxter). An off-the-shelf vision component is used to substitute for geometric knowledge available in the simulation and an inverse kinematics module is used to allow the Baxter to enact the trajectory. Our experimental studies validate the three contributions of the paper: (1) the controller learned from virtual demonstrations can be used to successfully perform the manipulation tasks on a physical robot, (2) the LSTM+MDN architectural choice outperforms other choices, such as the use of feedforward networks and mean-squared error based training signals and (3) allowing imperfect demonstrations in the training set also allows the controller to learn how to correct its manipulation mistakes.
💡 Research Summary
The paper addresses a critical challenge in assistive robotics: enabling robots to learn complex manipulation tasks for disabled or elderly users without requiring the users to provide physical demonstrations in their homes. Collecting demonstrations in a real home environment is time‑consuming, disruptive, and poses safety risks. To overcome this, the authors propose a complete pipeline that starts with virtual demonstrations, trains a deep neural network controller, and then transfers that controller to a physical Baxter robot.
Virtual Demonstration Collection
A Unity3D simulation was built that models a tabletop with a shelf and a simple two‑finger gripper with seven degrees of freedom. Users (a single participant in the study) control the gripper via mouse and keyboard, performing two representative ADL tasks: (1) pick‑and‑place (grasp a small box and place it on a shelf) and (2) push‑to‑pose (rotate and translate a box on the table without grasping). Demonstrations were recorded at 33 Hz, capturing the full state of all movable objects and the gripper’s pose and open/close status. The raw dataset comprised 650 pick‑and‑place and 1,614 push‑to‑pose trajectories.
Data Augmentation
Because the pick‑and‑place task allows the object to be placed at any point on the shelf, the authors generated additional trajectories by shifting existing ones laterally. Both tasks benefited from temporal down‑sampling: the high‑frequency recordings were subsampled to 4 Hz, creating multiple independent low‑frequency trajectories from each original demonstration. This augmentation expanded the training set to 31,200 pick‑and‑place and 12,912 push‑to‑pose trajectories, providing over 600 k and 370 k waypoints respectively.
Network Architecture
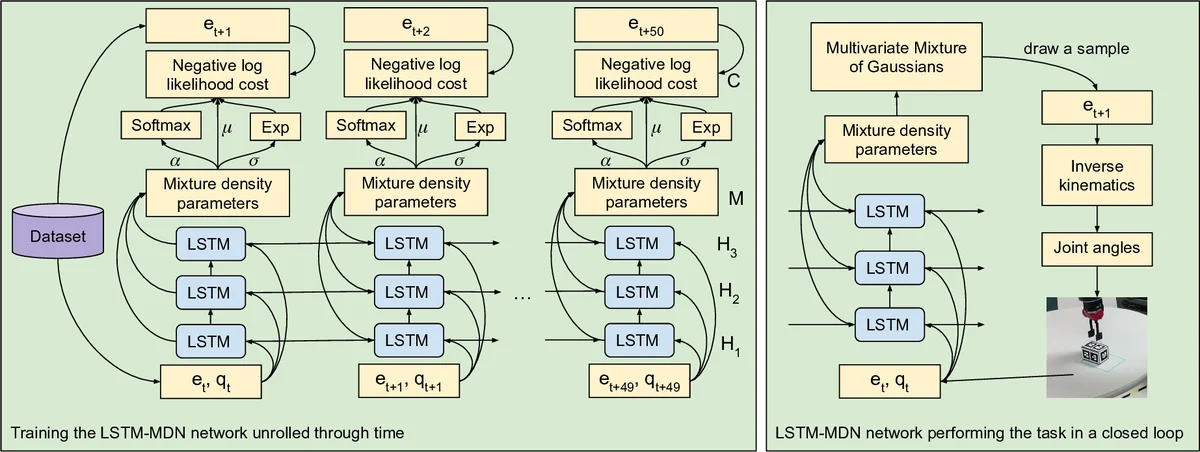
The controller receives the current environment state (object poses) and the current gripper state, and predicts the next gripper pose and open/close status. The core of the model is a three‑layer LSTM (50 units per layer) that captures temporal dependencies and the sequential nature of the tasks. On top of the LSTM, a Mixture Density Network (MDN) predicts the parameters of a Gaussian mixture model (means, variances, mixing coefficients) for the next pose. The loss is the negative log‑likelihood of the true next waypoint under this mixture, which allows the model to represent multimodal action distributions. This contrasts with conventional feed‑forward networks trained with mean‑squared error (MSE), which would average over multiple viable solutions and produce unrealistic intermediate actions.
Transfer to Physical Robot
For deployment, the trained LSTM‑MDN predicts a desired gripper pose at each timestep. An off‑the‑shelf vision system (RGB‑D) estimates object poses in the real world, providing the same input format as the simulation. An inverse kinematics module converts the predicted pose into joint commands for Baxter. The robot then executes the trajectory in real time.
Experimental Results
The authors evaluated three hypotheses: (1) virtual‑trained controllers can successfully operate a real robot, (2) LSTM‑MDN outperforms feed‑forward‑MSE baselines, and (3) including imperfect demonstrations enables the robot to learn corrective behaviors. In real‑world trials, the LSTM‑MDN controller achieved >90 % success on both tasks, while the feed‑forward‑MSE baseline failed frequently, especially on the push‑to‑pose task where multimodal solutions are common. Moreover, demonstrations that contained failures (e.g., missed grasps, dropped objects) were deliberately retained in the training set. The resulting controller learned to detect and recover from small execution errors, effectively “self‑correcting” during task execution.
Contributions and Future Work
The paper’s three main contributions are: (i) a validated method for transferring policies learned from virtual demonstrations to a physical assistive robot, (ii) empirical evidence that the combination of LSTM memory and MDN multimodal output yields superior performance over simpler architectures, and (iii) demonstration that imperfect, noisy demonstrations can be beneficial, teaching the robot to handle and rectify mistakes. The authors suggest future extensions such as integrating domain randomization, incorporating real user feedback, scaling to more complex manipulators, and expanding the repertoire of ADL tasks.
Comments & Academic Discussion
Loading comments...
Leave a Comment