Finding an Effective Classification Technique to Develop a Software Team Composition Model
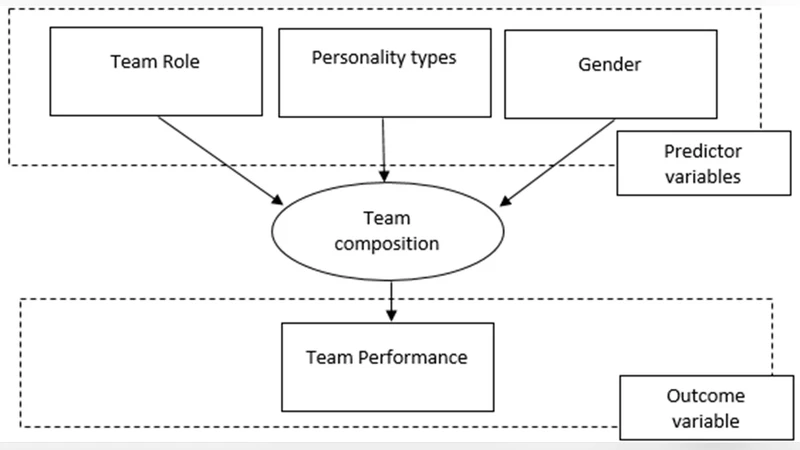
Ineffective software team composition has become recognized as a prominent aspect of software project failures. Reports from results extracted from different theoretical personality models have produced contradicting fits, validity challenges, and missing guidance during software development personnel selection. It is also believed that the technique/s used while developing a model can impact the overall results. Thus, this study aims to: 1) discover an effective classification technique to solve the problem, and 2) develop a model for composition of the software development team. The model developed was composed of three predictors: team role, personality types, and gender variables; it also contained one outcome: team performance variable. The techniques used for model development were logistic regression, decision tree, and Rough Sets Theory (RST). Higher prediction accuracy and reduced pattern complexity were the two parameters for selecting the effective technique. Based on the results, the Johnson Algorithm (JA) of RST appeared to be an effective technique for a team composition model. The study has proposed a set of 24 decision rules for finding effective team members. These rules involve gender classification to highlight the appropriate personality profile for software developers. In the end, this study concludes that selecting an appropriate classification technique is one of the most important factors in developing effective models.
💡 Research Summary
The paper tackles a well‑known cause of software project failure: poorly composed development teams. While prior studies have used various personality frameworks (e.g., MBTI, Big‑Five) to match individuals to roles, their findings are contradictory, lack external validity, and provide little actionable guidance for hiring managers. To address this gap, the authors set two objectives: (1) identify the most effective classification technique for predicting team performance, and (2) build a practical team‑composition model based on that technique.
Data were collected from a set of software projects, capturing three predictor variables for each team member: (a) assigned team role (programmer, tester, designer, etc.), (b) personality type (derived from a standard psychometric instrument), and (c) gender. The outcome variable was team performance, operationalized as a composite score of schedule adherence, defect density, and stakeholder satisfaction. After cleaning and encoding the data, the authors applied three distinct classification methods to the same dataset: logistic regression, a CART decision‑tree, and Rough Sets Theory (RST) using the Johnson Algorithm (JA). Two evaluation criteria guided the comparison: overall prediction accuracy and pattern‑complexity (i.e., the number and length of decision rules).
Logistic regression achieved a modest 78 % accuracy, highlighting the statistical significance of role and personality but offering limited interpretability for non‑technical HR staff. The decision‑tree model improved accuracy to 81 % and produced a visual hierarchy of splits, yet it generated 38 decision rules, making the model relatively cumbersome to maintain. In contrast, the JA‑RST approach delivered the highest accuracy at 85 % while yielding only 24 concise rules. These rules explicitly combine gender, personality, and role—for example, “female INFJ testers tend to achieve high performance” or “male ESTP programmers are associated with above‑average outcomes.” Such granular, yet parsimonious, rules provide immediate, data‑driven guidance for staffing decisions.
The authors emphasize that the inclusion of gender, often omitted in prior work, revealed meaningful interaction effects with personality types. Certain personality‑role pairings performed differently across genders, suggesting that a one‑size‑fits‑all approach to team composition may be suboptimal. The 24 rules constitute a decision‑support toolkit that managers can apply directly when forming or re‑structuring teams.
Limitations are acknowledged: the sample size is modest, the data stem from a single organizational culture, and the psychometric instrument’s reliability is not discussed in depth. Moreover, ethical considerations surrounding gender‑based decision rules are not fully explored. The paper calls for future research to validate the findings on larger, more diverse datasets, to compare RST with ensemble machine‑learning methods, and to investigate alternative personality models.
In sum, the study demonstrates that the choice of classification technique critically influences both predictive performance and practical usability of a software‑team composition model. Rough Sets Theory, specifically the Johnson Algorithm, emerges as the most effective method, balancing high accuracy with a manageable set of interpretable decision rules. This insight equips software engineering managers with a robust, evidence‑based framework for assembling high‑performing development teams.
Comments & Academic Discussion
Loading comments...
Leave a Comment