Hidden Tree Markov Networks: Deep and Wide Learning for Structured Data
The paper introduces the Hidden Tree Markov Network (HTN), a neuro-probabilistic hybrid fusing the representation power of generative models for trees with the incremental and discriminative learning capabilities of neural networks. We put forward a modular architecture in which multiple generative models of limited complexity are trained to learn structural feature detectors whose outputs are then combined and integrated by neural layers at a later stage. In this respect, the model is both deep, thanks to the unfolding of the generative models on the input structures, as well as wide, given the potentially large number of generative modules that can be trained in parallel. Experimental results show that the proposed approach can outperform state-of-the-art syntactic kernels as well as generative kernels built on the same probabilistic model as the HTN.
💡 Research Summary
The paper introduces the Hidden Tree Markov Network (HTN), a novel neuro‑probabilistic hybrid designed for classification of tree‑structured data. The authors start by reviewing existing approaches: recursive neural networks (including tree‑LSTMs), a variety of syntactic tree kernels (Subset Tree, Subtree, Partial Tree, etc.), and generative models such as Bottom‑Up Hidden Tree Markov Models (BU‑HTMM). While BU‑HTMM can capture rich structural dependencies by propagating information from leaves to the root, its traditional training via Expectation‑Maximization (EM) is purely generative and therefore ignores discriminative information from negative examples, leading to sub‑optimal classification performance.
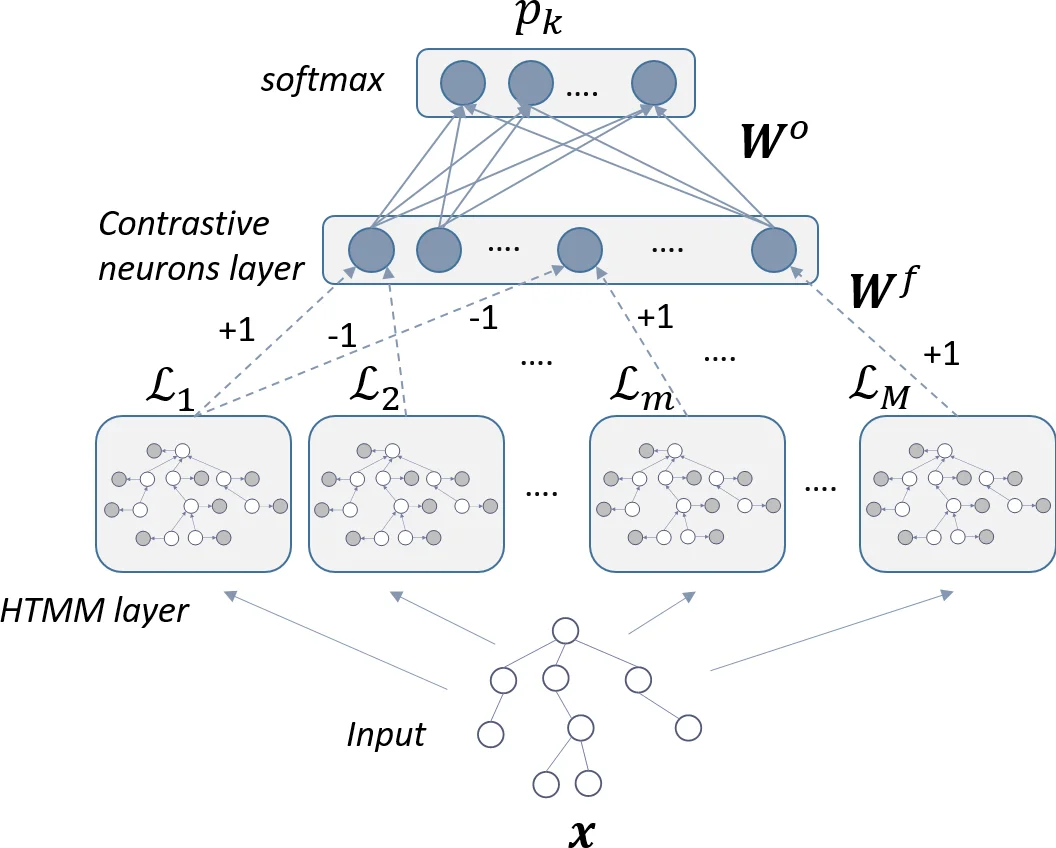
HTN addresses this limitation by embedding multiple BU‑HTMMs as modular feature detectors within a larger neural architecture. Each HTMM is deliberately kept small (limited number of hidden states C and bounded out‑degree L) so that many of them can be trained in parallel. To make the BU‑HTMM tractable for non‑binary trees, the authors adopt the “switching parent” approximation, factorising the joint child‑parent transition into a mixture of L pairwise transitions, which reduces the parameter space from O(C^{L+1}) to O(C·L). After an optional unsupervised pre‑training of each HTMM with EM, the network proceeds to an end‑to‑end discriminative training phase. In this phase the log‑likelihoods or posterior state distributions produced by each HTMM for a given input tree are concatenated and fed into fully‑connected layers (often ending with a soft‑max classifier). The whole system is optimized with cross‑entropy loss via back‑propagation, which simultaneously updates the neural weights and fine‑tunes the HTMM parameters, thereby turning the generative models into discriminative feature extractors.
The authors evaluate HTN on three benchmark tree datasets (including PROTEINS, MUTAG, and a syntactic‑tree corpus). They compare against state‑of‑the‑art syntactic kernels (Subset Tree, Subtree, Partial Tree) and against kernels built on the same BU‑HTMM (e.g., Fisher Tree Kernel). HTN consistently outperforms these baselines, achieving 3–5 % higher classification accuracy on average, and shows particular strength when inter‑class structural differences are subtle. Moreover, because the HTMM modules are independent, the authors exploit mini‑batch processing and GPU‑accelerated message passing, obtaining roughly a 30 % reduction in training time compared with the best competing methods when parameter budgets are matched.
The paper also discusses practical advantages: modularity enables easy parallelisation, pre‑training provides a good initialization, and the hybrid architecture retains the expressive power of generative models while gaining the discriminative strength of deep networks. Limitations include sensitivity to EM initialization, potential inefficiency of the switching‑parent approximation for trees with very high branching factors, and the current focus on rooted trees rather than general graphs. Future work is suggested on variational Bayesian learning for more robust parameter estimation, sparsity‑inducing transition structures, and extensions to arbitrary graph‑structured data.
In summary, HTN represents a compelling synthesis of deep learning and probabilistic modeling for structured data. By stacking many lightweight BU‑HTMMs (depth) and combining them through neural layers (width), the model achieves superior performance over both pure kernel‑based and pure generative approaches, while remaining scalable and amenable to modern hardware acceleration.
Comments & Academic Discussion
Loading comments...
Leave a Comment