Dialogue Act Recognition via CRF-Attentive Structured Network
Dialogue Act Recognition (DAR) is a challenging problem in dialogue interpretation, which aims to attach semantic labels to utterances and characterize the speaker’s intention. Currently, many existing approaches formulate the DAR problem ranging from multi-classification to structured prediction, which suffer from handcrafted feature extensions and attentive contextual structural dependencies. In this paper, we consider the problem of DAR from the viewpoint of extending richer Conditional Random Field (CRF) structural dependencies without abandoning end-to-end training. We incorporate hierarchical semantic inference with memory mechanism on the utterance modeling. We then extend structured attention network to the linear-chain conditional random field layer which takes into account both contextual utterances and corresponding dialogue acts. The extensive experiments on two major benchmark datasets Switchboard Dialogue Act (SWDA) and Meeting Recorder Dialogue Act (MRDA) datasets show that our method achieves better performance than other state-of-the-art solutions to the problem. It is a remarkable fact that our method is nearly close to the human annotator’s performance on SWDA within 2% gap.
💡 Research Summary
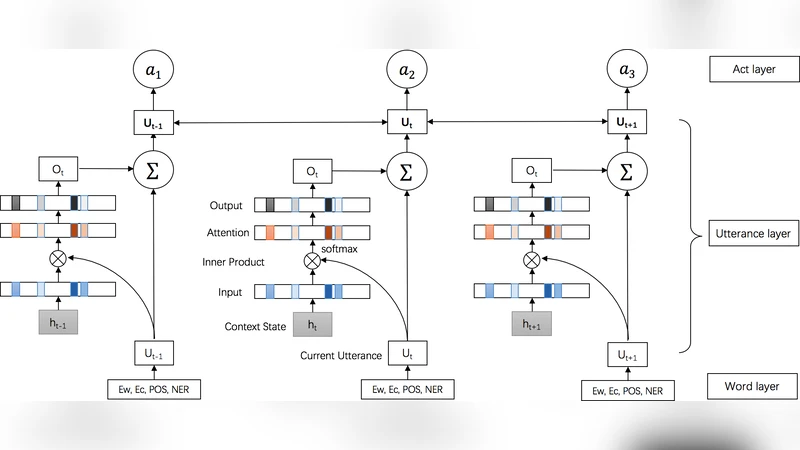
The paper addresses Dialogue Act Recognition (DAR) by proposing a novel end‑to‑end architecture called CRF‑Attentive Structured Network (CRF‑ASN). The authors first point out that existing methods either rely on handcrafted features or treat the problem as a flat multi‑class classification, thereby ignoring the rich contextual dependencies among utterances and their associated dialogue acts. To overcome these limitations, the model integrates three main components. (1) Hierarchical semantic inference: each word is represented by a concatenation of pretrained word embeddings (Word2Vec/GloVe), character‑level CNN embeddings, POS tags, and NER tags. These rich token vectors are processed by a bidirectional GRU to obtain an utterance‑level vector. (2) Memory‑enhanced contextual representation: a single‑hop memory network computes attention scores between the current utterance vector and all previously encoded utterance vectors, producing a weighted sum that allows unrestricted access to the entire conversation history. The output memory is added back to the original utterance representation, yielding a context‑aware embedding. (3) Structured CRF‑Attention layer: rather than applying a standard linear‑chain CRF directly on the utterance embeddings, the authors introduce a structured attention mechanism that treats the selection of latent variables (the dialogue act sequence) as a soft distribution over all possible label structures. This mechanism is integrated into the CRF’s transition potentials, enabling joint modeling of utterance semantics and label dependencies. The whole network is fully differentiable and trained end‑to‑end with a combined cross‑entropy and CRF log‑likelihood loss. Experiments on two benchmark corpora—Switchboard Dialogue Act (SWDA) with 42 classes and Meeting Recorder Dialogue Act (MRDA) with 5 classes—show that CRF‑ASN outperforms prior state‑of‑the‑art methods such as DRLM‑Conditional, LSTM‑Softmax, and RCNN. On SWDA the model achieves 78.9 % accuracy, within 2 % of human annotator performance, and on MRDA it reaches 84.3 % accuracy. Ablation studies confirm that both the memory‑enhanced encoder and the structured attention contribute significantly to the gains. The paper concludes that enriching CRF with neural attention and memory mechanisms provides a powerful, scalable solution for dialogue act recognition and opens avenues for extending the approach to other conversational AI tasks.
Comments & Academic Discussion
Loading comments...
Leave a Comment