Dynamic Multi-Arm Bandit Game Based Multi-Agents Spectrum Sharing Strategy Design
For a wireless avionics communication system, a Multi-arm bandit game is mathematically formulated, which includes channel states, strategies, and rewards. The simple case includes only two agents sharing the spectrum which is fully studied in terms …
Authors: ** Jingyang Lu, Lun Li, Dan Shen
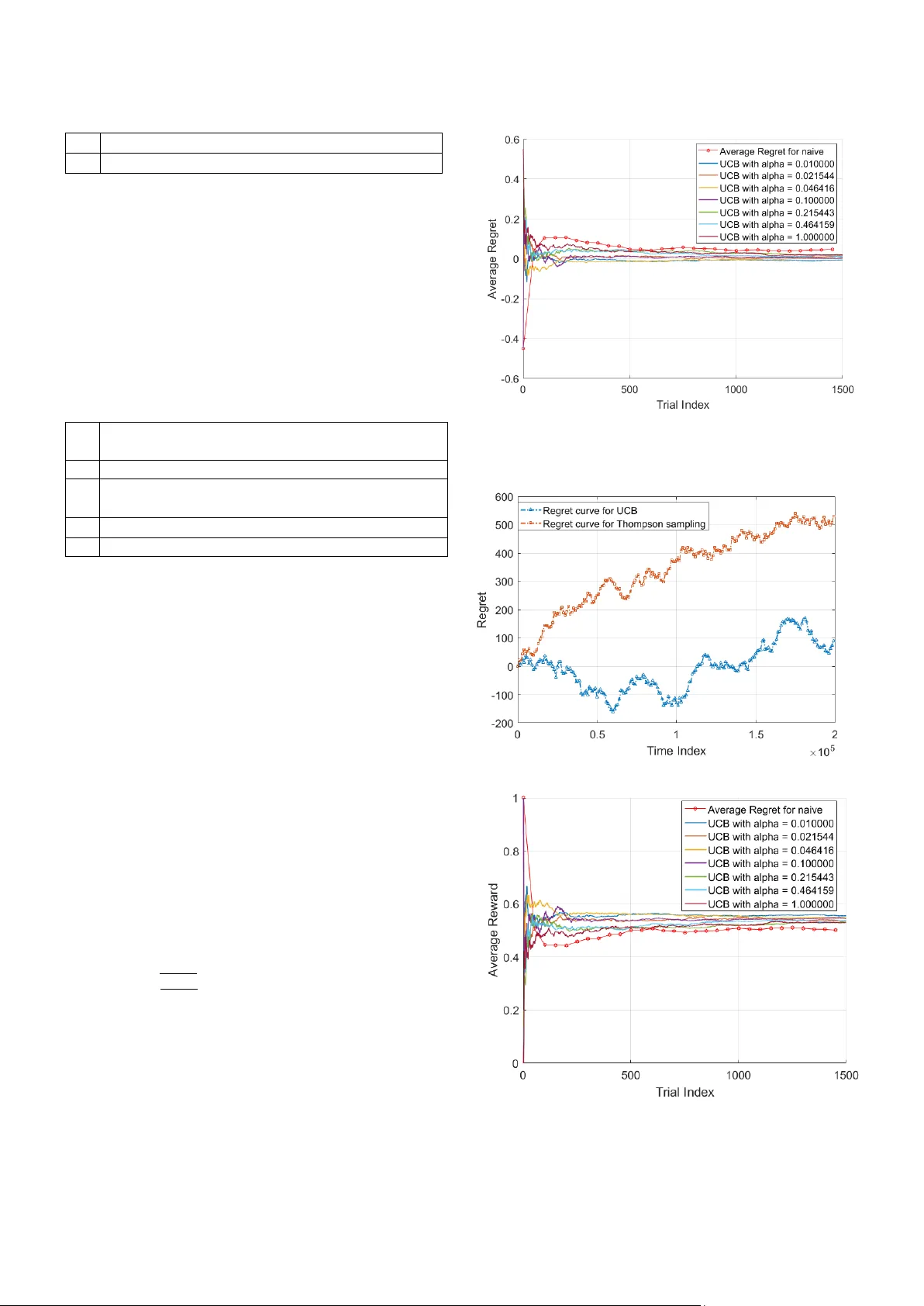
Dynamic Multi-Arm Bandit Game Based Multi- Agents Spectrum Sharing Strategy Design Jingyang Lu, Lun Li, Dan Shen, Gens he Chen, Bin Ji a Intelligent Fusion Tec hnology, Inc., 20271 Gold enrod Ln, Germantown, MD, 208 76 {Jingyang.lu, lun.li, dshen, gc hen, bin.ji a} @intfusiontech.co m Erik Blasch, Khan h Pham Air Force Research Laboratory Rome, NY and Kirtland, AFB, NM {erik.blasch.1, khanh.pham} @us.af.mil Abstract — Fo r a wireless a vionics co mmunication syste m, a Multi- a rm bandit game is m athematically formulated, which includes channel states, strategies, and rewards. The simple case includes only two agents sharing the s pectrum w hich is fully studied in terms of maxi m izing the c umulative reward over a finite ti me horizon. An upper confidence bound (UCB) algorithm is used to achieve the optimal solutions for the stochastic M ulti-arm bandit (MAB) problem. Also, the M AB problem can also be sol ved fr om the Markov game fra mework perspective. Meanwhile, Thompson sampling (TS) is also used as benchmark to evaluate the proposed approach performance. Numerical results are also provided regarding minimizing the expectation of the regret and choosing the best parameter for the upper confid ence bound. Keywords — Multi-arm Bandit Ga me;Cognitive Raido Network ; Dynamic Spectrum Access I. I NTRODUCTI ON Avionics systems are dependent on communication capabili ties for navigation and control [1][2]. A key element of future unmanned aerial s ystems (UAS) would be wireless communications. Ho wever, the many possible U AS would be sharing the available spec trum for navigation and co ntrol. A wireless spectrum, regarde d as a li mited resource, has been investigated to increase the utility efficiency [1] . A Cognitive radio (CR) has been proposed to automatically adapt the communication system parameter to overcome the conflict between the great demand for spectrum and large amount of spectrum left available b y Joseph Mitola III [3] . In a cognitive radio network ( CRN), spectrum sensing p rovides the b asis for the communication contr ol center to d ynamically allo cate the spectrum resources without bringing harmful inter ference to other users [4][5 ] . Recently, the spectrum alloc ation problem has been studied from the physical (PHY), medium access control (M AC), and network layers usin g different approaches s uch as communication theor y, signal processing, graph theory, machine learning, and game theory; all o f which invol ve computational complexity and communication overhead [6] . These approaches are advancing capabilities for avionics systems. Thus, a key p roblem arise s as how to acco mmodate the different parts of co mmunication syste m to balance the system spectr um utility and com putation co mplexit y constrained by the limited res ources. In this paper, a new t ype of ga me is for mulated to design t he strategy that each communicat ion node can dynamically select a candidate spectrum to transmit signal efficientl y with the smallest accumulative r egret. In the Multi- arm Bandit (MAB) game , which is o riginally proposed in [7], a gambler has to choose one of K machines to play. Each time, the gambler pulls the arm o f one slot machine and receives a reward or payoff. T he purp ose of the ga me is to maximize the gambler's accu mulative return o r eq uivalently, the accumulative regret. The problem is a t ypical example o f trade-off between the exploratio n and exploitation. If the player myopically focuses on the slot machine he thinks is th e best, he may miss the actually best machine. On the other ha nd, if he spends most of ti me trying different slot machines, he may fail to play the best o ption enough o ften to gain an optimal rewa rd. The trad itional Multi-arm band it game m ostly dep ends on the assumptions about the stati stics of the slot machine. I n [8] , a new type o f Multi-ar m ba ndit game is investigated, in which an adversary i nstead of a well behaved stochastic process, has complete control over th e payoffs. It is proved that the proposed algorithm can achieve the best payoff arm at the rate of in a seq uence of T plays. Considering the h igh computational complexity of solving stochastic dynamic ga mes as the n umber of ag ents grow, the proposed mean- field approximatio n can be dram atically reduced. Also, a performance bo und is d erived to evaluate the appr oximation performance [9]. Considering the computability and plausibility limitation of the Markov perfect equilibrium, an approximation m ethodolog y also called mean field equilibrium is con sidered where agents optimize o nly w it h respec t to the other players' av erage estimate, which is reasonable because it is impossible for each player to keep knowledge of other pla yers all t he time. The necessary co ndition for the existence o f a mean field equilibrium in such games is derived and i nvestigated [10] . The Multi-arm bandit g ame is a type of seq uential optimizatio n problem, where in successive trials, a n agent p ulls a rando m arm from a given set of arms of a certain size to rece ive corresponding reward from unkno wn priori. The agent can adjust his/her strategies by only observing his/her reward history. There might possibl y exist a gap bet ween the ideal maximum reward and actual reward because o f th e information shortage. Based on the basic bandit pro blem which involves only one agent, in t his paper, the problem i s g eneralized to multiple age nts, where each agent’s d ecision will affect the other agents’ reward. Multi-arm bandit games come in two categories: stochastic and adversarial. In stoch astic case , it is supposed that the pla yers’ action doesn’t c hange each b andit ’s reward pr obability distribution. While in adversa rial case , based on the agent’s actions, eac h bandit will adjust its strategies minimizing the agent’s reward on t he other side. Much research has been conducted related to the jamming effect and detectio n in communication systems . In [11][12], a stochastic game is characterized in the threat predication and situat ion a wareness. Based on [11] , a g ame theoretic situation awareness and im pact assessment approach is further extended for cyber network defense to consider the change o f threat intent during c yber conflict [13] . In [14][15], it is assumed that the system ce nter is un ware of the existence of the jammer, where the e ffect of th e jamming signal is studied from the trace and determ inant perspective. It is common to use Chi-Square d etection using the d eterminant fo r jamming detectio n. It is shown that in [16] that the ad versary can attac k the system witho ut being detected via taking advantage of the subspace of the measurement matrix. In [17] , the jammer detection is further studied in a power system, where a data frame attack is op timally d esigned as a quadratically constrained quadratic program. It sh ows that only a half critica l set of measurements are needed in order to make the system unobser vable. If some pr ior infor mation is accessible, Bayesian detection ca n be utilized for j amming detectio n. In [18], an improved Bayesian detection i s designe d that can minimize the system’s es timation error instead of minimizing the detection error. A minimum mean square error estimator is used as a benchmark for perfor mance analysis. Also, the jamming effect is al so studied from ga me perspective [1 9][20], where stochastic and two-person zero -sum games a re designed to improve the threat detection. Also, since tr ansponder designs have adopted more powerful onboard pro cessing and multiple antennas to enhance the co mmunication quality and robustness [21][22] that can be controlled for j amming mitigation . Overall, the contrib ution o f this paper is summarized as follow s: firstl y, the Mu lti-arm bandit ga me is mat hematicall y formulated, which includes t he channel state s, player strateg y, and p ayoff re ward. T he simple case involves only two agents sharing the spectrum . The t wo-player spectrum shari ng case is first fully st udied in ter ms of maxi mizing the cum ulati ve reward over a finite time horizo n. An upper confidence bound (UCB) algorithm is used to achieve the optimal solutions for the stochastic MAB p roblems. Als o, the prob lem can also be solved from the Markov g ame framework perspective. Meanwhile, Thompson s ampling (TS) is also used as benchmark to evalu ate the proposed approach performance. The rest of paper is organized as follo ws, Section I I generally describes the spectrum alloc ation problem and the system model. T wo approac hes i ncluding t he U CB and t he T hompson sampling are m athematicall y describ ed for c omparison to the MAB ap proach. Numerical results are shown in Section III as applied to an avionics com munication system for cyber protection. Sectio n IV summari zes the paper. II. S YST EM M ODEL A. Cog nitive Radio Network Regarding t he communication li mitation for avionics systems , the spec trum is divided by time and frequency. T he player can choose the frequency with the band width to transmit the signal information or co nduct jamming activit y. For the cooperating case , it is im port ant for each p layer to sense the vacuum spectrum hole to guarantee th e signal transmission performance with low probability of interference. For the adversary case , the player’s obj ective is to choo se the candidate spectrum hole to transmit t he signal with a low probabilit y of detection. B. Multi- arm Bandit (MAB) For mulation It is suppo sed that a game is p layed among players. A stochastic game defined as . Time: The game is played in discrete time, indexed by time , as shown in F igure 1. Figure 1: System Model State: Fo r ea ch p layer , th e state at time t is denoted as , where is co mpact. is used to denote the state of all the players except pla yer at the time t. Strategy/Action: The action taken by each player i at time t is denoted as . The feasible action set f or the state is denoted as , . It is assumed that is compact, so is compact as well. Transition pro bability: It is supposed that players e volve strategies based on t he Mar kov process. Giv en that , , , the next state for player i can be characterized based on Borel prob ability measure , (1) where Borel sets . Based on Equation (1) , given the current state for all players and action a for player i, the state is independent of all the ot her past states during t he game. Payoff/Reward: the payoff for player i at the time t is denoted as (2) Based on different t ypes of p ayoffs, the Multi -arm ban dit (MABs) game can be categorized as s tochastic MABs, adversarial MABs, and Ma rkovian M ABs. Discount facto r: is the discount factor and t he corresponding payoff for a pla yer till time T ca n be characterized as, (3) It is supposed that a gam bler face s slot machines trying to find a s trategy that can maximize the average reward , , where denotes the ac cumulative reward over a finite time horizon, denotes the reward for each ti me i ndex by c hoosing the ar m i . Let denote the maximum reward i f the player ’ s action is supposed to be best for each round, so the goal for the ga mbler is to minimize the expectation of accumulati ve regret. I n this paper, the discount factor , the problem can be ch aracterized as (4) Regret: After T rounds, regr et is defined as the difference between the sum of t he collected rew ards and the sum associated with an optimal strateg y r ewards. T he regret of an action set over the sequence is given by (5) where is the opti mal strategy for each round. For the play er, the goal is ty p ically to min imize the regret discussed ab ove from either expectat ion, or with high probability based on th e w ay how th e rew ar ds are gener ated. To determ ine th e perform ance, a b o und is s et for an algorithm from either expectation or the high probability the reward for wh ich the decisi o n of th e draw is sele cted. As for the stochasti c MABs, the objective function (5) above is investigat ed from the expectation perspectiv e, w hich can be character ized as , (6) Because the is inside the expectation operation, the objective function is ha rd to s olve. Usually, the p seud o-regret objective function is conside red when designing the MA Bs algorithm , (7) where denotes the highest mean reward among the arms , and denotes th e rew ard mean f or arm i . For the cognitive radio n etwork, an arm is regarded as one channel candidate in the limited spe ctrum resources. For each player i, the strategy is a functi on ov er the tim e t . T he strategy is supposed that each player makes his/her own decisi on, w hich can be ch aracter ized as, (8) The Upper Confi dence Bou nd (UCB) algorithm is often used to find the o ptim al so lution. L et denote the to tal times that arm i has been chosen f o r the f irst T t rials , (9) nd denotes the sample mean rewards obtain ed by pulling the arm i for the first T trials , ( 10 ) The UCB alg orithm is show n in Algori thm 1. Algorithm 1: Upper Confidence Bound 1 Param eter 2 For 3 4 Set if Else 5 Receive new reward C . Thom pson sampli n g As for th e Thompson sampling, it is assumed that the pla yer has some prior knowledge of t he posterior distrib ution of the reward for each arm. For each arm, the player starts from a pri or information o n t he p arameters of the distribution of reward for each ar m i . T he posterior distribution of the reward for each arm is upd ated by taking ad vantage of the received observation. The best arm is selecte d based on t he updated po sterior prob ability. In thi s pap er, the Ber noulli M ulti -arm B andit game is st udied. is usually selected as the p rior information. The Thompson Sampling algorit hm is summarized in Algorithm 2. Algorithm 2: T hompson sampling 1 Initialization: scale parameter , , 2 t = t+1 3 For each , 4 Choose 5 Go to step 2 III. N UMER I CAL R ESULT In this section, the Upp er Confiden ce Bound (UCB) algorithm is imple mented in selecting t he available spectrum blo ck to transmit the s ignal. It is supposed th at the operator is facing four spectrum candidates regarded as fo ur ar ms denoted as , , , , which follow one of t he four distributions: 1) Ber noulli distribution , 2) , 3) Exponential distributio n with , or 4) Finite elements with p robability . The corresponding means derived based on the distribution discussed abo ve are 0.5, 0.25, 0.11 , and 0. 55. In the first simulation , the UCB algorithm is used to maintain the co nfidence intervals for t he various mean re wards for each arm. Fo r ea ch give n trial, the UCB algorithm c hooses t he a rm with the highest upper confide nce bound up to t he current time t . In our simulation, is set to be in t he ra nge(0.1,1), and the step size is 0.14. T he best is selected based on Equation (3) . The estimation of r eward mean is updated in each iteration through . T he bench mark used in the simulation is that the pla yer j ust choose s the arm of the highest sample mean, which is equivalently to . The reward average and th e regret average considering the different values ar e sho wn in Figure 2 and Figure 4 . Figure 4 shows that the UCB alg orithm outperfor ms the n aïve algorithm in terms of average reward. The UCB alg orithm with achieves the most average reward . Figure 2 Average regret via UCB with different value Figure 3: System performance between UCB and Thompson Figure 4 : Average reward via UCB with different value In the second simu lation , there are four spectrum candidates satisfying the Ber noulli distribution with mean 0.20 , 0.23, 0. 25 , and 0 .21. T he optimal is ac hieved based on simulation from the range(0.1, 1 ) set th e sam e as Simulation 1. As for the Thompson s ampling methods, the scale p arameter is . From the simulation shown i n Figure 3 , a 200000 tim es Mo nte Carlo run i s conduc ted in the simulati on. It is shown that the UCB w ith the op timal o utperforms th e Thompson sampling algorithm . The average r eward between UCB and T hompson sampling is shown in Figure 5 . In general, it is not pr actical to assume that t he reward for certain arm satisfies either a Ber noulli or a Gaussian distrib ution, because Thompson sampling is not a Bayesian posterio r sam pling algorithm for general stoc hastic Multi-ar m bandit games. However, the T hompson sam pling is an online al gori thm that provides a baseline for comparison . Fro m Figure 5, it is shown that both algorithms can achieve comparativel y good system performance. Figure 5: Average reward between UCB and Thompson sampling IV. C ONCLUSION In this paper, the Multi-arm bandit game is applied in th e dynamically spectrum selection for avionics communicatio ns . Firstly, the Mult i-a rm bandit mathematically f ormulated, wh ich includes channel activities, p layer strategy, and pa yoff re ward. The simple case where only t wo agents get i nvolved in shar ing the spectrum is first fully studied in terms o f maximizing the cumulative re ward over a finite ti me horizon. T he upper confidence bound (UCB ) is used to achieve t he optimal so lutions for the stocha stic M AB prob lems. Also, the p roble m can also be sol ved fro m the Markov game fra mework perspective. Meanwhile, T hompson sa mpling (TS) is also used as benchmark to evaluate the proposed approach performance. Future work includes appl ying the method s for a space co mmunications scenario [23 ] and for coor dination o f UAVs [24]. These testbeds would inco rporate the methods to p rovide robust communicatio n in an adversarial en vironment. V. R EFERENCES [1] D. Niy ato and E. Hossain, "Co mpetitive spectru m sharin g in cognitive radio networks: a dy namic game approach," in IEEE Transactions o n Wireles s Com munications , vol. 7, no. 7, pp. 2651-2660, July 2008. [2] E. Blasch, P. Paces, P . Kostek, K. Krame r, “Summary of Avionics Technologies,” IEEE Aerospace and Electronics Systems Magazine , Vol. 30, Issue 9, pp. 6-11, Sept. 2015. [3] J. Mitola and G. Q. Maguire, "Cognitive radio : making software radios more personal," in IEEE Personal Communications , vol. 6, no. 4, pp. 13- 18, Aug 1999. [4] Q. Zhao, B. M . Sadler, "A Survey of Dynamic Spectrum Access," in IEEE Signal Processing Magazine , vol. 24, no. 3 , pp. 79-89, May 2007. [5] A. Goldsmith, S. Jafar, A., Maric, I., S rinivasa, S., “Breaking Spectrum Gridlo ck With Cognitive Radio s: An Information Theoretic P erspective," in Proceedings o f the IEEE , vol. 97, n o. 5, pp. 894-914, May 2009. [6] S. Hayk in, “Cognitive radio: brain -empowered wireless communications," in IEEE Journal on S elected Areas in Communications , vol. 23, no. 2, pp. 201-220, Feb. 2005. [7] G , Y. Weintraub , L. Benkard and B, Van Roy, “ Obliviou s Equilibrium: A Mean Field Approximation for Large-S cale Dynamic Games” [8] J. Vermorel, M. Mohri M. “Multi -armed Bandit Algorithms and Empirical Evaluation. Springer, Berlin, Heidelberg [9] G. Y. Weintraub, C. L, Benkard and B. Van Roy. “Oblivious Equilibrium: A M ean Field Approxim ation for Large-Scale Dynamic Games.” NIPS , 2005. [10] S. Adlakha, R. Johari, “Mean Field Equilibrium in Dy namic Games with Complementarities ,” h , 2010. [11] G. Ch en, D. Shen, C. Kwan, J. B. Cru z, M. Kruger, E. Blasch, "Game Theoretic Approach to Threat Prediction and Situation Awareness," Journa l of Advances in Information Fu sion, Vo l. 2, No. 1, 1-14, June 2007. [12] D. Shen , G. Chen, J. B. Cruz, Jr., L. Haynes, M. Kruger, E . Blasch, “A Markov game t heoretic da ta f usion a pproach for cyber situational awareness, ” Proc. SPIE 6571, 2007. [13] D. Shen, G. Chen, E. Blasch and G. Tadda, "Adaptive Markov Game Theoretic Data Fusion Approach for Cy ber N etwork Defense," IEEE Military Communications (M ILCOM) Conference , Orlando, FL, USA, 2007. [14] J. Lu and R. Niu, "False information injection attack on dynamic state esti mation in multi-sensor systems," Interna tional Conference on Information Fusion (FUSION ), 2014. [15] J. Lu and R. Niu, "Malicious attacks on state estim ation in multi - sensor dynam ic systems," IEEE In ternational Workshop on Information Forensics a nd Securi ty (W IFS), Atlanta, GA , pp. 89- 94, 2014. [16] Y. Liu, P. Ning, and M . K. Reiter, “ False data injection attacks against state est ima tion in electric power grids,” ACM Trans. Inf. Syst. Secur. 14, 1, Article 13 (June 2011), 33 pages. DOI=http://dx.doi.org/10.1145/1952982.1952995 [17] J. Kim , L . Ton g and R. J. Thom as, "Data Framing A ttack o n State Estimation," in IE EE J ournal on Selected Areas in Communications , vol. 32, no. 7, pp. 1460-1470, July 2014. [18] R. Niu and J. Lu, "False information d etection w ith minim um mean squared errors for Bayesian estimation ," Annual Conference on Information Sciences a nd Systems (CISS), Baltimore, MD, 2015. [19] G. Chen, D. Shen, C. Kwan, J. B. Cruz and M. Kruger, "G ame Theoretic A pproach to Threat P rediction and Situation Awareness," International Co nference o n Information F usion , Florence, 2006. [20] J. Lu and R. Niu, "A state estimation and m alicious attack game in multi-sensor d ynam ic systems ," International Conference on Information Fusion (Fusion), pp. 932-936, 2015. [21] P. Arapoglou, K. Liolis, M. Bertinelli, A. P anagopoulos, P. Cotti s, and R. Gaudenzi, “MIMO o ver Satellite: A Review”, IEEE Communications Surveys & Tutorials , vol. 13, p p. 27-51, Fiest Quarter 2011. [22] J. Clerk Ma xwell, A Treatise on Electricity and Magnetism , 3rd ed., vol. 2. Oxford: Clarendon, 1892, pp.68 – 73. [23] D. Shen, G. Chen, G. Wang, K. Ph am, E. Blasch, Z. Tian, “Network Survivability Oriented Markov Games (NSOMG) in Wideband Satellite C ommunications,” IEEE/ AIAA Digital Avionics Systems Conference , 2014. [24] Z. Wang, E. Blasch, G. Chen, D. Shen, X. Lin, K. Pham, “A L ow - Cost Near Real Time Tw o -UAS Based UWB E mitter Monitorin g System,” IEEE AE SS Magazine , V ol. 30, No. 11, pp. 4 -11, Nov. 2015.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment